أنثروبيك تطوّر تقنية لإيقاف 95⁒ من هجمات كسر حماية الذكاء الاصطناعي
أعلنت شركة أنثروبيك الناشئة في الذكاء الاصطناعي عن تطوير تقنية مُبتكرة تهدف إلى الحدّ من إساءة استخدام نماذج الذكاء الاصطناعي الخاصة بها ومنع استخراج مُحتوى ضار. تأتي هذه الخطوة كمؤشر على تنافس الشركات الكبرى لتعزيز معايير الأمان في مجال الذكاء الاصطناعي الذي يشهد تطورًا سريعًا.
في دراسة بحثية، كشفت الشركة عن نظام جديد يُدعى المُصنِّفات الدستورية "constitutional classifiers"، وهو طبقة أمنية تُضاف فوق نماذج اللغة الكبيرة مثل نموذج Claude الخاص بأنثروبيك.
اقرأ أيضًا:
ما هو الذكاء الاصطناعي، كيف يعمل؟ وهل يهدد البشرية
أفضل 5 برامج تعديل الصور بالذكاء الاصطناعي مجانًا
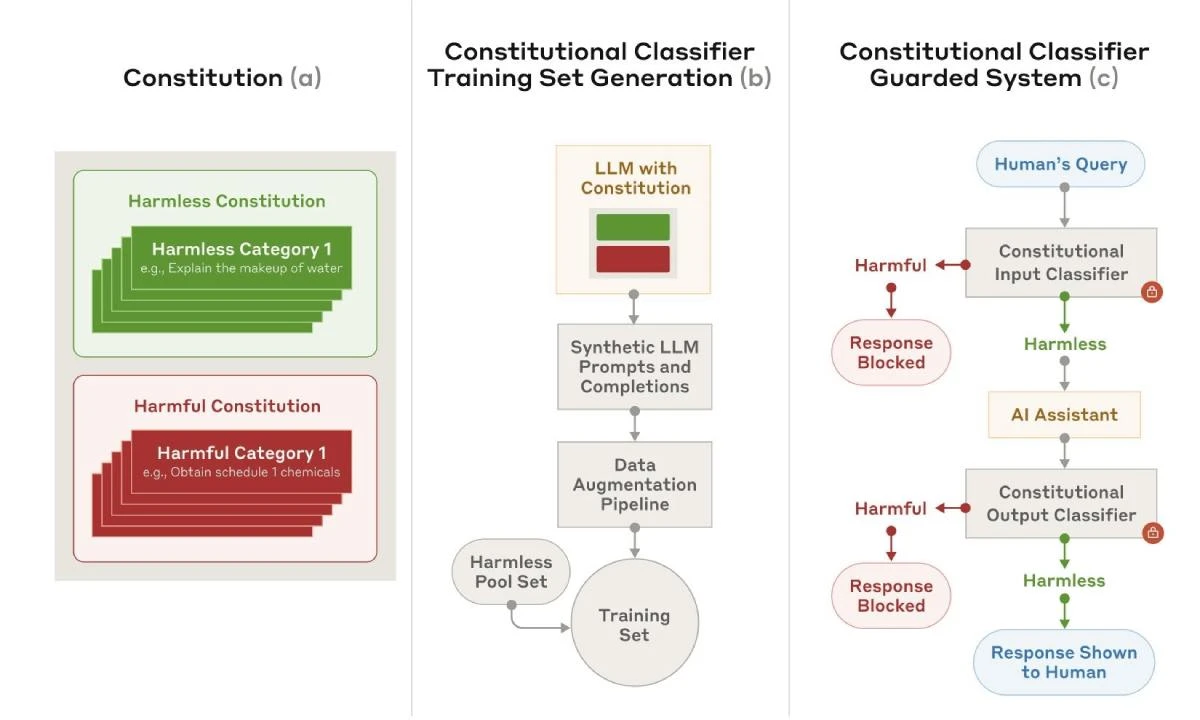
يتمثّل دور هذا النظام في مُراقبة المُدخلات والمخرجات لمنع إنتاج مُحتوى غير آمن مثل "كيفية صنع الأسلحة البيولوجية".
يأتي هذا التطوير ضمن جهود مُكافحة ظاهرة اختراق الذكاء الاصطناعي أو ما يُعرف بـ Jailbreaking، حيث يحاول البعض استغلال النماذج لإنشاء معلومات خطِرة أو غير قانونية، مثل توجيهات لصنع أسلحة كيميائية. ومع تصاعد القلق من هذه التهديدات، تسارع الشركات لحماية نماذجها، بهدف تعزيز ثقة المستخدمين وتقليل التدقيق التنظيمي.
على الجانب الآخر، قدمت مايكروسوفت في مارس تقنية الدروع التوجيهية "Prompt Shields"، بينما أطلقت ميتا نموذج حارس التوجيه "Prompt Guard" في يوليو 2023، والذي تعرّض للاختراق في بداياته لكنه خضع بعد ذلك لتحسينات أمنية.
أوضح أحد أعضاء فريق Anthropic التقني أن التركيز الرئيسي كان على مواجهة الأخطار البالغة مثل تصنيع الأسلحة الكيميائية. إلا أن الميزة الأبرز للنظام الجديد تكمن في قدرته العالية على التكيُّف والاستجابة بشكل فوري للأخطار المُتغيرة.
على الرغم من أن الشركة لم تدمج هذه التقنية بعد في النماذج الحالية مثل Claude، فإنها أكّدت أنها قد تُستخدم مُستقبلًا مع إطلاق أجيال جديدة أكثر تطورًا وتعقيدًا.
يعتمد النظام على "دستور" يتضمن مجموعة من القواعد التي تُحدّد أنواع المُحتوى التي يُسمح بإنتاجها وتلك المحظورة. كما يتمتع بمرونة تتيح تعديله للتعامل مع أنواع متعددة من المحتوى الضار.
ومن بين طرق التحايُّل على هذه النماذج، إعادة صياغة الطلبات بأساليب غير مألوفة أو التظاهر بأن النموذج يجسّد شخصية خيالية بهدف الالتفاف على الحواجز الأمنية.
لتقييم كفاءة النظام، أعلنت أنثروبيك عن برنامج مُكافآت للباحثين الأمنيين (Bug Bounty) تصل قيمته إلى 15000 دولار لمن ينجح في اختراق النموذج.
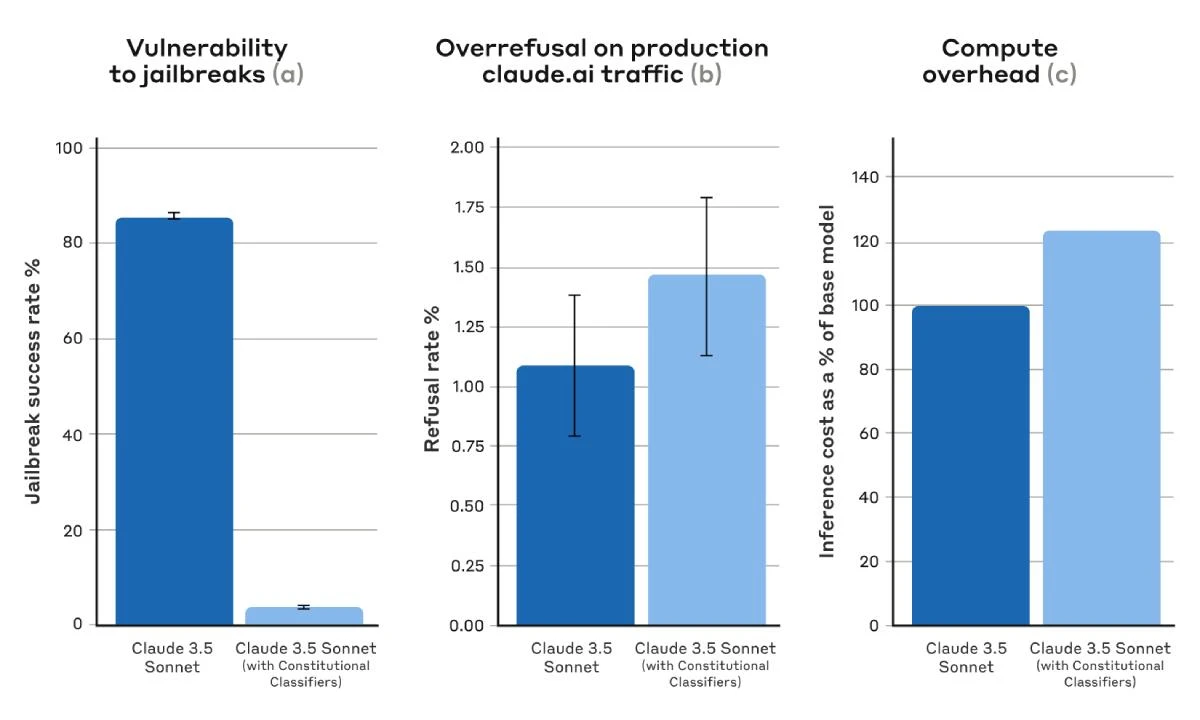
أظهرت نتائج الاختبارات أن النموذج التجريبي Claude 3.5 Sonnet تمكن من التصدّي لأكثر من 95⁒ من مُحاولات الاختراق عند تشغيل التقنية الأمنية الجديدة، مُقارنةً بنسبة نجاح مُنخفضة بلغت 14⁒ عند عدم تفعيلها.
ومع ذلك، تواجه شركات الذكاء الاصطناعي تحديًا في تحقيق التوازن بين الأمان وكفاءة الأداء، حيث يمكن أن تؤدي الإجراءات الأمنية الصارمة أحيانًا إلى رفض طلبات مشروعة. هذا الجانب لاحظه المستخدمون مع إطلاق نماذج مثل Gemini و Llama 2. لكن أنثروبيك أكّدت أن نظامها الجديد تسبّب فقط في زيادة بسيطة بمُعدلات الرفض غير الضرورية.
ومع إضافة هذه الطبقة الأمنية تأتي تحديات تشغيلية إضافية. إذ ذكرت الشركة أن التقنية تزيد استهلاك الموارد الحاسوبية بنسبة 24⁒، والذي يمثل عبئًا جديدًا نظرًا للتكلفة العالية لتشغيل أنظمة الذكاء الاصطناعي.