فعاليات مؤتمر GTC 2014: ماذا سوف تقدم لنا تقنية NVLink؟

كنا قد تحدثنا في خبر سابق هنا عن معمارية Pascal القادمة في عام 2016 والتي سوف تدخلنا في نظريات جديدة من الأداء واستهلاك المنخفض للطاقة, ولكن ما كان ينقصنا المزيد من التفاصيل عن التقنيات الجديدة القادمة معها و احد اهم هذه التقنيات هي ما يعرف بـ NVLink. ومن اجل ذلك هناك مجموعة من التفاصيل التي كشفت عنها NVIDIA ايضا ضمن فعاليات مؤتمر GTC.

كانت NVIDIA قد اعلنتها صراحة أنها تخطط لدمج توصيل عالي السرعة يُسمى بتقنية NVIDIA NVLink، وذلك داخل المعالجات الرسومية المستقبلية، مما يتيح لكلا من المعالجات الرسومية والمعالجات المركزية أن يتشاركا البيانات بشكل أسرع من خمس لـ12 مرة مما يستطيعان القيام به اليوم. هذا سوف يزيل الاختناق الطويل ويساعد بتمهيد الطريق من أجل جيل جديد من الحواسب الفائقه بسرعة exascale التي هي أسرع بـ50-100 مرة من أكثر الأنظمة قوة اليوم. فلك ان تتخيل على ماذا نحن مقبلون عليه!
ستضيف شركة NVIDIA تقنية NVLink داخل معمارية Pascal التي وجدت من اجل تحقيق افضل النتائج في عالم المعالجات الرسومية مختلفة الفئات. فكما اعلن رسميا فسوف يتم تقديمه في عام 2016, وقبل معمارية Pascal سوف نشاهد المعمارية المنتظرة بشدة Maxwell الجديدة هذه السنة. التوصيل الجديد تم تطويره بالتعاون مع IBM، والتي سوف تدرجه في الإصدارات المستقبلية لمعالجاتها المركزية POWER.

قال برايان كيليهر نائب رئيس أول لقسم هندسة المعالجات الرسومية لدى شركة NVIDIA " تقنية NVLink تفتح إمكانية المعالجات الرسومية كاملا بواسطة تحسين كبير لنقل البيانات بين المعالجات الرسومية والمعالجات المركزية، مما يقلل وقت الانتظار التي تتطلبه المعالجات الرسومية من أجل معالجة البيانات".
قال برادلي ماكريدي نائب رئيس لدى شركة IBM " إن الـNVLink يتيح تبادل بيانات سريع بين المعالجات المركزية والمعالجات الرسومية، بالتالي يحسن ناتج البيانات عبر نظام الحوسبة ويتجاوز الاختناق الرئيسي الذي يحصل للحوسبة المسرعة اليوم. NVLink تسهل على المطورين تعديل تطبيقات عالية الأداء وتحليلات البيانات للاستفادة من أنظمة المعالج المركزي والمعالج الرسومي المسرعة. نعتقد بأن هذه التقنية تمثل مساهمة هامة أخرى لنظامنا OpenPOWER الإيكولوجي".

مع قيام تقنية NVLink باقتران محكم للمعالجات المركزية الخاصه بـ IBM POWER ومع المعالجات الرسومية NVIDIA Tesla، فإن النظام الإيكولوجي لمركز بيانات POWER سيكون فادرا على الاستفادة الكلية لتسريع المعالجات الرسومية من أجل مجموعة متنوعة من التطبيقات، مثل حوسبة عالية الأداء، تحليلات البيانات، وتعليم الأليات.
المعالجات الرسومية اليوم، متصلة بالمعالجات المركزية مستندة على x86 عبر واجهة (PCIe)، التي تحد من قدرة المعالجات الرسومية للوصول إلى نظام ذاكرة المعالجات المركزية وهي أبطئ بأربع لخمس مرات من أنظمة ذاكرة المعالجات المركزية النموذجية. واجهة PCIe تعتبر ذات اختناق كبير بين المعالجات الرسومية و المعالجات المركزية IBM POWER، التي تملك عرض نطاق ترددي أكثر من المعالجات المركزية x86. فمع واجهة ستطابق عرض النطاق الترددي لأنظمة الذاكرة الخاصه بالمعالجات المركزية النموذجية، فإنها ستتيح حتما بالمعالجات الرسومية بالوصول إلى ذاكرة المعالجات المركزية بكامل عرض النطاق الترددي الخاص بها.
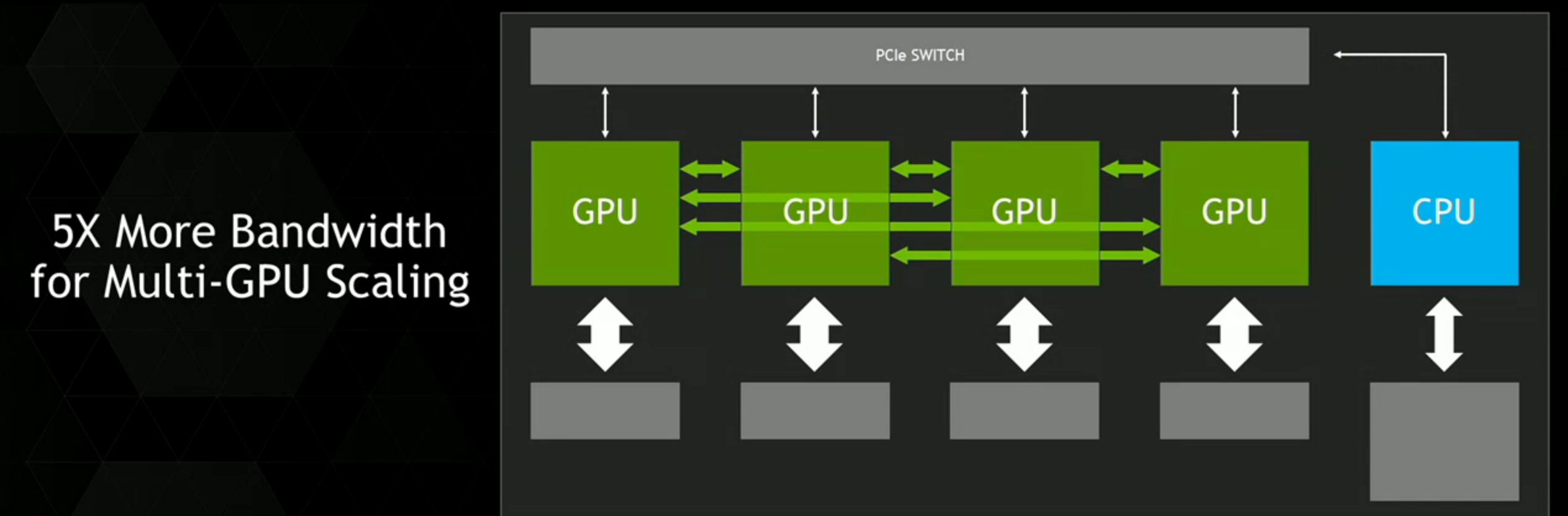
توصيل عرض نطاق ترددي عالي سيحسن بشكل كبير أداء تطبيق البرمجيات المسرعه. بسبب فروق نظام الذاكرة, فإن المعالجات الرسومية تمتلك ذواكر سريعة لكن صغيرة، و المعالجات المركزية تمتلك ذواكر ضخمة لكن بطيئة- تطبيقات الحوسبة المسرعة تحرك البيانات بالعادة من الشبكة أو قرص التخزين لذاكرة المعالجات المركزية، ومن ثم تنسخ البيانات إلى ذاكرة المعالجات الرسومية قبل أن يتم معالجتها من قبل المعالجات الرسومية. مع NVLink فسوف تنتقل البيانات بين ذاكرة المعالجات المركزية و ذاكرة المعالجات الرسومية بسرعات أكثر بكثير، مما يجعل تطبيقات المعالجات الرسومية المسرعة تجري بشكل أسرع بكثير مما نحن نتوقعه.
نقل بيانات أسرع، مقترن مع ميزة أخرى معروفة باسم Unified Memory او الذاكرة الموحدة، والتي بدورها سوف تبسط برمجة مسرع المعالجات الرسومية. الذاكرة الموحدة تسمح للمبرمج بالتعامل مع ذواكر المعالج الرسومي والمعالج المركزي على أنه كتلة واحدة من الذاكرة. يمكن للمبرمج العمل على البيانات دون القلق حول ما إذا كانت ستقيم في ذاكرة المعالج الرسومي ام المعالج المركزي.
مع أن المعالجات الرسومية المستقبلية لـ NVIDIA ستستمر بدعم واجهة PCIe، فإن تقنية NVLink ستُستخدم من أجل توصيل المعالج الرسومي لـ المعالج المركزي المهيأة للـNVLink فضلا عن توفير اتصالات عرض نطاق ترددي عالي مباشرة بين المعالجات الرسومية المتعددة. أيضا، مع أن عرض نطاق ترددي عال جدا، فإن NVLink بشكل جوهري أكثر كفاءة للطاقة المنقول من واجهة الـPCIe.
صممت شركة NVIDIA وحدة قياسية لاستيعاب المعالج الرسومي على معمارية Pascal مع NVLink. وحدة المعالج الرسومي الجديدة بثلث حجم لوحات الـPCIe القياسية المستخدمة من أجل المعالج الرسومي اليوم. الموصلات في أسفل وحدة الـPascal تتيح لها أن توصل باللوحة الأم، مما يحسن تصميم النظام وسلامة الإشارة. توصيل NVLink عالي السرعة ستمكننا من ان نرى أنظمة مقترنة بإحكام التي تقدم مسارا لحواسب فائقة بسرعة exascale قابلة للتطوير وذات كفاءة طاقة عالية، تعمل عند 1,000petaflops ( أي 1x 1018عملية فاصلة عائمة في الثانية)، أو أسرع بـ50-100 مرة من أكثر الأنظمة قوة اليوم.