"مايا 200" رد مايكروسوفت على NVIDIA و Google
مايكروسوفت تتحدى حدود الفيزياء بشريحة 'مايا 200' لتهيمن على سحابة الذكاء الاصطناعي.
في خطوة استراتيجية تعيد رسم معالم الحوسبة السحابية، كشفت مايكروسوفت يوم الإثنين (26 يناير) عن جيلها الثاني من مسرّعات الذكاء الاصطناعي، شريحة مايا 200.
يأتي هذا الإعلان ليعزز ترسانة منصة Microsoft Azure، حيث لا تمثل الشريحة الجديدة مجرد تحديث تقني، بل قفزة هندسية تقترب في حجمها من أقصى الحدود الفيزيائية لما يمكن تصنيعه اليوم، والمعروف بـ "حد القناع الضوئي".

تُعد منصة Azure إحدى أكبر منصات الحوسبة السحابية عالميًا، حيث تتيح للمستخدمين تطوير التطبيقات والخدمات، واختبارها، ونشرها، وإدارتها، من خلال شبكة ضخمة من مراكز البيانات التي تديرها مايكروسوفت حول العالم.
الشرائح المطبوخة منزليًا!
يأتي هذا الإعلان في إطار سعي الشركة إلى تعزيز استقلاليتها التقنية في مجال الذكاء الاصطناعي، وتقليل الاعتماد على المسرّعات العامة، عبر تطوير بنية تحتية مخصّصة قادرة على تحقيق أعلى كفاءة ممكنة في الأداء، والتكلفة، واستهلاك الطاقة، خصوصًا في أحمال العمل المرتبطة بنماذج اللغة الضخمة والتطبيقات الذكية الحديثة.

في تحوّلٍ واضح يُرسّخ ملامح ما يمكن تسميته بـ «عصر السيليكون المُفصَّل حسب الطلب»، تتّجه كبرى شركات الحوسبة السحابية إلى تَبنِّي استراتيجية تصميم عتاد مخصّص (ASIC) داخليًا، بهدف بناء منصّات حوسبة تمنحها أفضلية تنافسية يصعب تقليدها أو مجاراتها.
فبدلًا من الاعتماد الكامل على الوحدات الرسومية العامة المخصّصة للحوسبة والذكاء الاصطناعي من شركات مثل NVIDIA و AMD، أصبح تطوير المسرّعات الخاصة داخل الشركة هو المسار الأساسي للسيطرة على بنية مراكز البيانات الحديثة.
وقد تحوّل تصميم شرائح الـ ASIC داخليًا إلى معيار جديد لرفع كفاءة البنية التحتية، من حيث:
- تسريع عمليات الاستدلال (Inference) وخفض زمن الاستجابة،
- تحسين اقتصاديات توليد الرموز (Token Generation) على نطاق واسع،
- تقليل استهلاك الطاقة وتحسين الأداء لكل واط،
- رفع الأداء مقابل التكلفة (Performance per Dollar).
ولا يقتصر هذا التحوّل على مستوى العتاد فقط، بل يمتد ليشمل تكاملًا عميقًا بين البرمجيات، والمعالجات، والأنظمة، ومراكز البيانات، في نموذج متكامل يتيح لهذه الشركات تحسين كل طبقة من طبقات المنظومة بما يتناسب مع أحمال العمل الخاصة بها.
ومع صعود نماذج اللغة الضخمة، والتطبيقات الوكيلة Agentic AI، وأحمال العمل المعقّدة القائمة على السياقات الطويلة والاستدلال متعدد الخطوات، لم تعد الحلول العامة كافية لتحقيق الكفاءة المطلوبة، بل أصبح السيليكون المخصّص أحد أهم أدوات بناء التفوّق التقني والاستراتيجي في عصر الذكاء الاصطناعي.
ما هو ASIC ولماذا أصبح محور المنافسة؟
بعد هذا الإعلان، يبرز سؤال جوهري: ما المقصود بشرائح ASIC، ولماذا أصبحت محورًا أساسيًا في سباق الذكاء الاصطناعي بين عمالقة التكنولوجيا؟
يشير مصطلح (ASIC (Application-Specific Integrated Circuit إلى الدوائر المتكاملة المصمّمة لأداء مهام محددة بدقة عالية، بخلاف المعالجات العامة مثل وحدات المعالجة المركزية (CPU) أو الوحدات الرسومية (GPU)، التي تُبنى لتخدم طيفًا واسعًا من التطبيقات.
وتكمن قوة شرائح ASIC في كونها تُصمَّم خصيصًا لنوع معيّن من الأحمال الحسابية، مثل عمليات المصفوفات، وضرب المتجهات، والاستدلال العصبي، ما يسمح بتحقيق مستويات أعلى من الكفاءة في الأداء واستهلاك الطاقة مقارنةً بالحلول العامة.
ترتكز فلسفة تصميم شرائح ASIC على مبدأ الاختزال الاستراتيجي، حيث يُعاد تشكيل السيليكون بالكامل ليتمحور حول وظيفة برمجية محددة بدقة هندسية عالية. وفي هذا النموذج المعماري، تُجرَّد الشريحة من الأعباء التشغيلية (Overheads) التي تفرضها المعالجات العامة، مثل دوائر التنبؤ بالتفرعات (Branch Prediction)، وآليات إعادة تسمية السجلات (Register Renaming)، ومنطق التنفيذ خارج الترتيب (Out-of-Order Execution)، وغيرها من الوحدات الأخرى.
ورغم الأهمية المحورية لهذه المكوّنات في سياق الحوسبة العامة، فإنها تتحوّل إلى ما يمكن وصفه بـ «هدر بنيوي» في أحمال عمل الذكاء الاصطناعي الرتيبة والمكثّفة، حيث يكون مسار التنفيذ معروفًا مسبقًا، وطبيعة الحسابات متوقّعة بدرجة عالية.
وبدلًا من ذلك، تُسخَّر مساحة سطح الشريحة «السيليكون» لبناء مصفوفات حسابية كثيفة ومتخصّصة في عمليات ضرب المصفوفات والمعالجة العصبية، بما يضمن توجيه كل مليمتر من الشريحة، وكل واط من الطاقة، نحو الغاية الجوهرية: تحقيق أعلى معدّل إنتاجية (Throughput) ممكن، بأقل تكلفة طاقة، وأعلى كفاءة تشغيلية.
وقد مكّن هذا التوجّه شركات مثل Google و Amazon و Microsoft من بناء منظومات متكاملة تجمع بين العتاد والبرمجيات، وتوفّر لها مرونة أكبر في التطوير، واستقلالية أعلى عن المورّدين الخارجيين، فضلًا عن تحسين الاقتصاديات التشغيلية على المدى الطويل.

مايا 200: تصميم مُخصَّص لقيادة الأداء مقابل التكلفة في الاستدلال
هندست مايكروسوفت هذه الشريحة خصيصاً لتلبية الطلب الهائل على عمليات الاستدلال (Inference) لنماذج الطليعة، وهي النماذج الأحدث والأقوى التي تدفع حدود القدرات الحالية مثل GPT-5.2 من Open AI. حيث تمثل مايا 200 تحولاً جوهرياً من العتاد العام نحو التوليد المتخصص ومنخفض التكلفة للرموز Tokens على نطاق واسع، مدعومة بنوى تنسور Tensor Cores تدعم تنسيقات البيانات فائقة الكفاءة FP4 و FP8 بشكل أصلي.
فيما يلي نغوص في التفاصيل التقنية والمواصفات التي تجعل من مايا 200 المحرك الأقوى لاستدلال الذكاء الاصطناعي في السحاب:
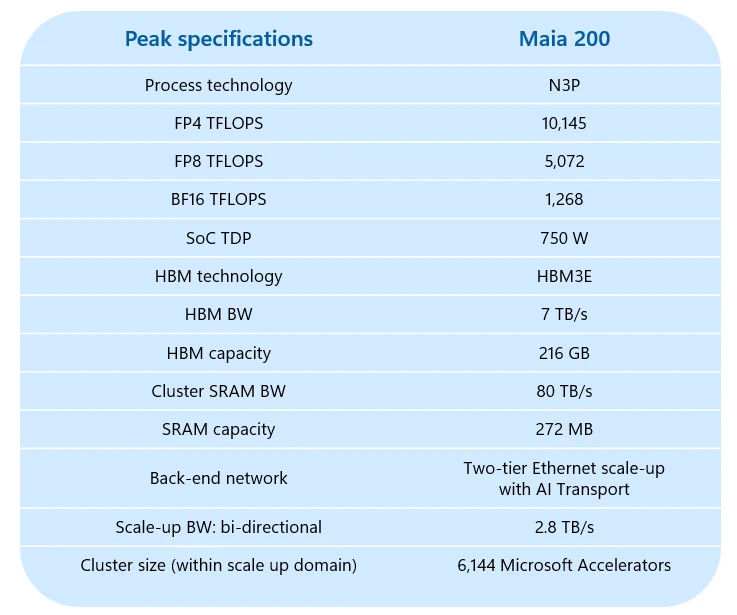
تقنية التصنيع وعدد الترانزستورات
تأتي شريحة مايا 200 بعقدة تصنيع متقدمة بدقة 3 نانومتر N3P من شركة TSMC، وهي النسخة الأعلى أداءً مقارنة بعقدة N3E، حيث توفّر كثافة ترانزستورات أعلى، مع تحسينات واضحة في الترددات وكفاءة الطاقة. وتضم الشريحة ما يقارب 140 مليار ترانزستور، ما يعكس مستوى التعقيد الهندسي الكبير المطلوب لدعم أحمال الذكاء الاصطناعي الحديثة.
الأداء الحوسبي وكفاءة الطاقة
من ناحية الأداء، توفّر مايا 200:
- أكثر من 10 بيتافلوبس بدقة FP4.
- أكثر من 5 بيتافلوبس بدقة FP8.
وهو ما يضعها في صدارة المسرّعات السحابية من حيث الأداء الخام مقارنةً بالمنافسين. ولا يقتصر تميّز مايا 200 على الأداء فقط، بل تمتد قوته إلى كفاءة التكلفة التشغيلية، حيث تؤكد مايكروسوفت أن هذه الشريحة تمثّل أكثر أنظمة الاستدلال كفاءةً قامت بنشرها حتى اليوم، مع تحقيق:
تحسّن بنسبة 30% في الأداء مقابل كل دولار يتم إنفاقه
مقارنةً بأحدث أجيال العتاد السابقة في أسطولها السحابي.
ويتحقق هذا المستوى من الأداء ضمن حدٍّ أقصى لاستهلاك الطاقة يبلغ 750 واط على مستوى النظام على الشريحة الواحدة (SoC TDP)، مما يعكس تركيز مايكروسوفت على تحقيق أفضل توازن بين القوة الحوسبية وكفاءة الاستهلاك.
منظومة الذاكرة وعرض النطاق
يعتمد مسرّع مايا 200 على منظومة ذاكرة عالية الأداء تتكوّن من:
- 6 وحدات HBM3E بسعة 36 جيجابايت لكل وحدة.
- بهيكلية 12H (طبقة مكدّسة 12).
ليصل إجمالي السعة إلى 216 جيجابايت. وتعتمد هذه الذاكرة على تكديس 12 طبقة DRAM عمودياً بسعة 3 جيجابايت لكل طبقة، وتوفّر:
- سرعة نقل تصل إلى 9.6 جيجابت/ثانية
- عرض نطاق إجمالي يبلغ 7 تيرابايت/ثانية
إلى جانب ذلك، تتضمّن الشريحة 272 ميجابايت من ذاكرة SRAM مدمجة داخلياً. تُستخدم هذه الذاكرة لخدمة العمليات كثيفة البيانات بكفاءة عالية، وتقليل الاعتماد على الذاكرة الخارجية، مما يخفّف الضغط على واجهة HBM، ويُحسّن كفاءة الطاقة بشكل عام.

نظام الربط والتوسّع الشبكي
تدعم مايا 200 نظام ربط شبكي عبر الإيثرنت القياسي، بقدرة نقل إجمالية تصل إلى:
- 2.8 تيرابايت/ثانية (ثنائي الاتجاه) بواسطة بطاقة شبكة مدمجة داخل الشريحة On-Die NIC، مما يعني أن البيانات يمكن أن تتدفق في الاتجاهين بين المعالج ووحدات الذاكرة أو المسرعات الأخرى في نفس الوقت، بدون تقليل عرض النطاق الإجمالي.
ويعتمد هذا النظام على:
- هيكلية توسّع ثنائية المستويات (Two-Tier Scale-Up)
- بروتوكول نقل مخصص لتطبيقات الذكاء الاصطناعي
صرّحت مايكروسوفت أن هذا البروتوكول قد جرى تطويره خصيصًا لمنظومة Azure، بهدف تحقيق اتصال فائق السرعة وزمن استجابة منخفض بين آلاف المسرّعات داخل مراكز البيانات، بما يتيح ربط ما يصل إلى 6,144 مسرّعًا ضمن عنقود حوسبي واحد يعمل كوحدة متكاملة.
كما تعتمد مايا 200 على بنية متقدمة لنقل البيانات داخل الشريحة (Efficient Data Movement Fabric)، ترتكز على نظام متعدد المستويات لنقل الذاكرة المباشر (Multi-Level DMA) وشبكة اتصال داخلية هرمية (Hierarchical Network-on-Chip).
تتيح هذه المنظومة تحريك البيانات بين وحدات المعالجة والذاكرة الداخلية وذاكرة HBM بكفاءة عالية دون تعطيل خطوط التنفيذ، مما يقلّل زمن الانتظار ويضمن تغذية مستمرة لوحدات الحساب.
وتؤدي هذه البنية إلى تحقيق أداء ثابت وقابل للتوسع، خاصة في أحمال العمل المعقدة والمتنوعة (Heterogeneous Workloads) والمهام كثيفة الاعتماد على الذاكرة (Memory-Bound Workloads)، وهو ما يعزز كفاءة الاستدلال على نطاق واسع داخل مراكز البيانات.

مايا 200 مقابل المنافسين، مقارنة الأداء والكفاءة
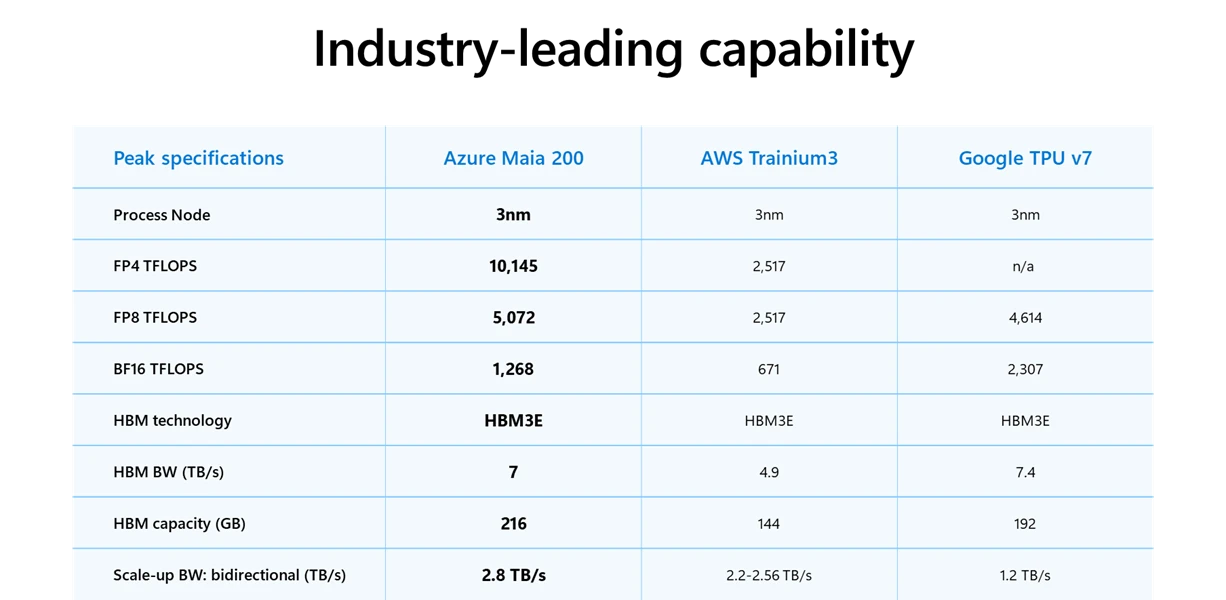
حملت مذكّرة الإطلاق التي نشرتها مايكروسوفت رسالة مباشرة إلى أبرز منافسيها في قطاع الحوسبة السحابية، وعلى رأسهم أمازون وجوجل. حيث تؤكّد الشركة بشكل صريح أن شريحة مايا 200:
- توفّر أداءً أعلى بثلاث مرات في دقة FP4 مقارنةً بأحدث مسرّعات Trainium 3 من أمازون.
- تتفوق في أحمال العمل بدقة FP8 على مسرِّع TPU v7 من جوجل.
- حجم ذاكرة أكبر من شرائح المنافسين.
وفي الوقت الذي تحافظ فيه مايكروسوفت على شراكة وثيقة مع شركة NVIDIA، معتمدةً على معالجات H100 و Blackwell في مهام التدريب الثقيلة للنماذج الضخمة، تمثّل مايا 200 خطوة واضحة نحو تقليل الاعتماد على السيليكون الخارجي في مهام الاستدلال اليومية، مثل تشغيل Microsoft 365 Copilot وخدمات Bing Search.
نظرة عامة على معمارية مايا 200
تعتمد مسرّعات مايا على بنية مجهرية هرمية (Hierarchical Micro-Architecture). وفي أساس هذا الهرم تقع وحدة (Tile)، وهي أصغر وحدة مستقلة تجمع بين القدرة الحسابية والتخزين المحلي.
تدمج كل وحدة (Tile) محركي تنفيذ متكاملين:
- وحدة المعالجة التنسورية (Tile Tensor Unit – TTU) المخصّصة لعمليات ضرب المصفوفات والالتفاف (Convolution) ذات الإنتاجية العالية.
- معالج المتجهات داخل الوحدة (Tile Vector Processor – TVP) وهو محرّك SIMD عالي القابلية للبرمجة يُستخدم للعمليات المرنة وغير النمطية.
كما تتضمّن كل وحدة Tile معالج تحكّم خفيف الوزن (Tile Control Processor – TCP)، يقوم بتنفيذ التعليمات منخفضة المستوى الصادرة عن طبقة البرمجيات، وينسّق بين أعمال وحدات TTU و DMA، بينما توفّر آليات المزامنة العتادية (Hardware Semaphores) تنسيقًا دقيقًا بين نقل البيانات وعمليات الحساب.
تتجمّع عدة وحدات Tile معًا لتشكّل عنقودًا (Cluster)، يمثّل المستوى الثاني من التنظيم المشترك وتبادل البيانات، ويحتوي كل عنقود على ذاكرة SRAM كبيرة متعددة البنوك (Cluster SRAM – CSRAM)، يمكن لجميع وحدات Tile داخله الوصول إليها، بالإضافة إلى نظام DMA مخصّص لنقل البيانات بين CSRAM و ذاكرة HBM عالية النطاق المدمجة مع الشريحة.
كما يحتوي كل عنقود على نواة تحكّم خاصة مسؤولة عن تنسيق التنفيذ المتعدد للوحدات، ويتم بناء النظام الكامل (SoC) من خلال دمج عدة عناقيد معًا.
وقد جرى تصميم مايا 200 من الأساس لدعم تنسيقات الحساب منخفضة الدقة Narrow Precision، إذ تم تحسين وحدة المعالجة التنسورية داخل الـ TTU لتنفيذ عمليات ضرب المصفوفات بدقة FP8 وFP6 وFP4، مع دعم أوضاع الدقة المختلطة (Mixed Precision)، مثل استخدام FP8 للتفعيلات (Activations) مع FP4 للأوزان (Weights)، بهدف تحقيق أقصى إنتاجية ممكنة دون التأثير على دقة النتائج.
وفي المقابل، يوفّر معالج المتجهات داخل الوحدة TVP قدرات حسابية بدقة FP8 إلى جانب دعم BF16 و FP16 وFP32، ما يمنح النظام مرونة عالية في التعامل مع الطبقات أو العمليات التي تستفيد من دقة أعلى.
كما تتضمّن الشريحة وحدة إعادة تشكيل وتحويل مدمجة (Integrated Reshaper)، تقوم برفع تنسيقات البيانات منخفضة الدقة إلى تنسيقات مناسبة للحساب بسرعة خطية (Line Rate) قبل تنفيذ العمليات، بما يضمن تدفّقًا سلسًا للبيانات دون التسبّب في اختناقات داخل خطوط التنفيذ.
كما تأتي ذاكرة SRAM المدمجة داخل السيليكون مقسّمة إلى مستويين رئيسيين:
- ذاكرة على مستوى العناقيد (Cluster SRAM – CSRAM)
- ذاكرة على مستوى الوحدات (Tile SRAM – TSRAM)
ويُتيح هذا الحجم الكبير من الذاكرة الداخلية تطبيق استراتيجيات متقدمة لإدارة البيانات بزمن وصول منخفض وكفاءة عالية في عرض النطاق.
وتُدار كلٌّ من CSRAM وTSRAM بالكامل عبر البرمجيات، سواء من خلال المطوّرين مباشرة أو عبر الـ Compiler وبيئة التشغيل (Runtime)، مما يسمح بتحديد موقع البيانات وتثبيتها بدقة داخل الشريحة، والتحكم الحتمي في موضعها وحركتها.


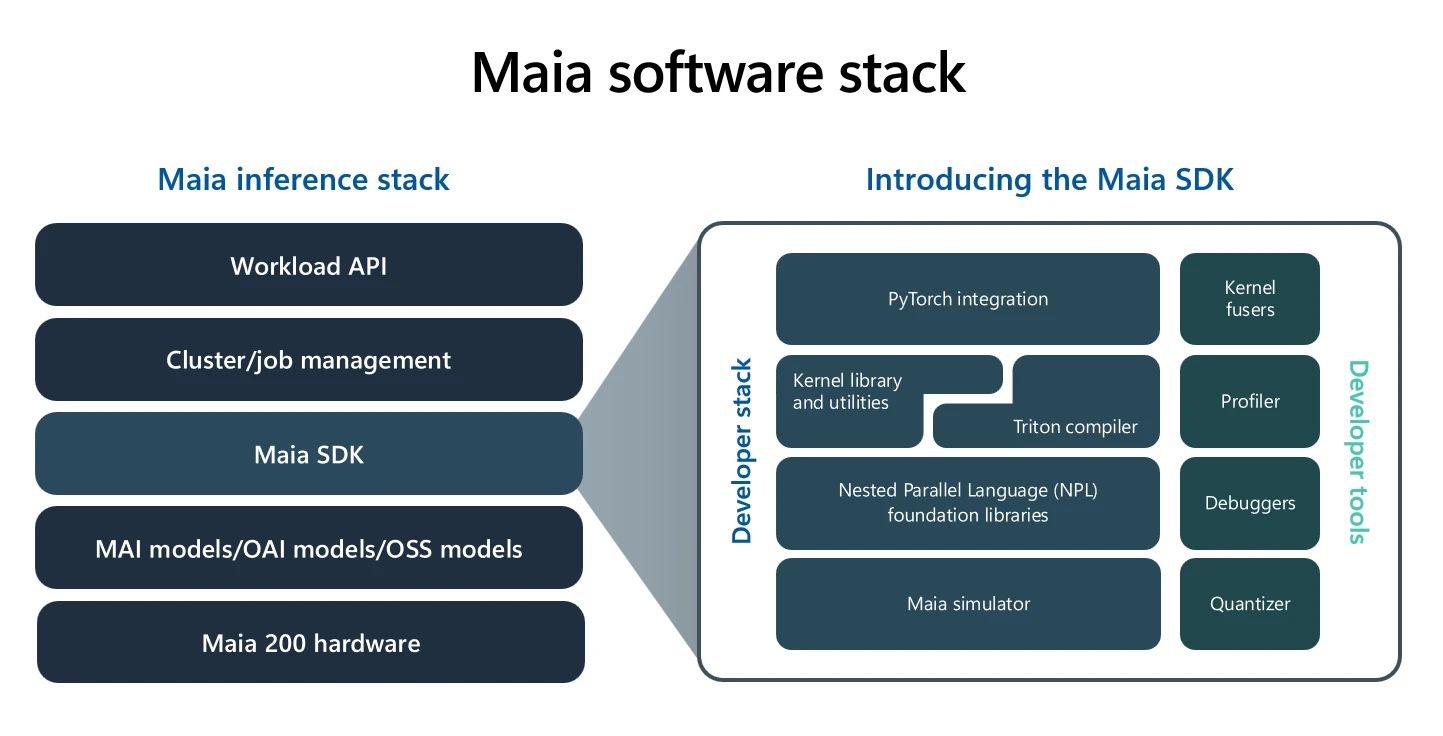
منظومة مايا 200 البرمجية وأدوات التطوير: منصة سحابية أصلية للاستدلال عالي الأداء
تجمع منظومة مايا 200 البرمجية بين منصة استدلال متكاملة ضمن بيئة Azure، وحزمة تطوير حديثة موجّهة للمطوّرين، صُمّمت خصيصًا لتقديم أداء مرتفع على نطاق واسع. وقد جرى تطوير هذه المنظومة بحيث تُمكّن مطوّري السحابة من اعتماد Maia بسلاسة، مع الاستفادة من الأدوات المألوفة، وفي الوقت نفسه إتاحة تحكّم منخفض المستوى عند الحاجة لتحقيق أعلى كفاءة ممكنة.
وتوفّر حزمة مايا SDK للمطوّرين مجموعة متكاملة من الأدوات لبناء النماذج مفتوحة المصدر والخاصة، وتحسينها، ونشرها على عتاد مايا. وتبدأ سير العمل بصورة طبيعية من إطار PyTorch، مع إمكانية اختيار مستوى التجريد المناسب لكل فريق، سواء عبر:
- استخدام مترجم مايا Triton لتوليد النوى الحسابية بسرعة.
- الاعتماد على مكتبات نوى محسّنة بعناية ومضبوطة لمعمارية مايا المعتمدة على الـ Tiles والـ Clusters.
- أو استهداف لغة مايكروسوفت الخاصة بالتوازي المتداخل Nested Parallel Language (NPL)، والتي تتيح تحكّمًا مباشرًا في حركة البيانات، وتوزيعها داخل SRAM، وتنفيذ العمليات المتوازية، بهدف الوصول إلى معدلات استخدام قريبة من الحدّ الأقصى للعتاد.
وتتضمّن الحزمة كذلك محاكيًا كاملًا، وسلسلة ترجمة متكاملة، وأدوات تحليل أداء (Profiler)، ومصحّح أخطاء (Debugger)، إلى جانب منظومة قوية للتحجيم العددي (Quantization) والتحقّق (Validation). وتتيح هذه الأدوات للفرق تطوير النماذج واختبارها حتى قبل توفر الشرائح فعليًا، وتشخيص عنق الزجاجة بدقة عالية، وضبط النوى الحسابية لتحقيق أفضل أداء ممكن عبر منظومة مايا بأكملها.
تحريك ميزان الاقتصاديات (الأداء مقابل التكلفة)
لا يتمثّل العامل الأهم لعملاء Azure والمستثمرين في السرعة الخام فقط، بل في معيار «الأداء مقابل التكلفة Performance per Dollar».
وفي هذا الإطار، صرّح سكوت غوثري، النائب التنفيذي لرئيس قطاع السحابة والذكاء الاصطناعي في مايكروسوفت، قائلاً:
«مايا 200 تمثّل قوة حقيقية في مجال استدلال الذكاء الاصطناعي».
يركّز تصميم مايا 200 على تحسين مرحلة الاستدلال والمنطق (Reasoning)، أي توليد الرموز (Token Generation)، بدلاً من مرحلة تدريب النماذج التي تتطلّب استثمارات رأسمالية ضخمة بمليارات الدولارات لكنها تتم بصورة محدودة، حيث تتم على فترات متباعدة، وغالباً ما تُنفَّذ مرة واحدة أو مرات محدودة.
في المقابل، يُشكّل الاستدلال التشغيل اليومي المستمر، حيث تولّد مليارات الرموز يوميًا لخدمة ملايين المستخدمين عبر تطبيقات مثل Copilot ومحركات البحث، وبالتالي يتحقّق العائد الاقتصادي الفعلي على المدى الطويل من خلال تقليل تكلفة كل رمز مُنتَج. ومن هذا المنظور، فإن الاستثمار في بنية الاستدلال عبر مايا 200 لا يرفع الأداء فحسب، بل يعظم العائد على الاستثمار (ROI) عن طريق خفض التكاليف التشغيلية المستمرة، مما يحوّل الذكاء الاصطناعي من عبء مالي متصاعد إلى نموذج أعمال مستدام وقابل للتوسّع.
وفي الختام، تُظهر مايا 200 أن الريادة في بنية الذكاء الاصطناعي التحتية لا تتحقّق من خلال شريحة قوية فقط، بل عبر تكامل شامل يشمل النماذج، وأدوات التطوير، وإدارة التشغيل، والسيليكون المخصّص، والشبكات، والبنية المعمارية على مستوى الرفوف، ومراكز البيانات بالكامل.
وتجسّد مايا 200 هذا المبدأ بوضوح، إذ توفّر تحسّنًا بنسبة 30% في الأداء مقابل التكلفة مقارنةً بأحدث الأجيال السابقة داخل منظومة مايكروسوفت، من خلال معمارية صُمّمت خصيصًا لتحقيق أعلى كفاءة على نطاق واسع. وتمثّل هذه الشريحة خطوة حاسمة نحو بناء أكثر منصات الحوسبة السحابية قدرةً وكفاءةً وقابليةً للتوسّع، كما تشكّل الأساس لمستقبل مايكروسوفت في مجال الذكاء الاصطناعي.
لا تتوقف مايكروسوفت عند هذا الحد، فقد أكدت الشركة أن الجيل التالي، مايا 300، موجود بالفعل في مرحلة التصميم.