ميتا تقلب الطاولة على ChatGPT بنموذج لا يقرأ ولا يكتب!
في الوقت الذي ينشغل فيه العالم بمطاردة البرومبت المثالي لـ ChatGPT، وتتسابق فيه شركات التكنولوجيا لحشو نماذجها اللغوية بمزيد من التريليونات من الكلمات والبيانات النصية، خرج يان ليكون - Yann LeCun، كبير علماء الذكاء الاصطناعي في شركة ميتا والحائز على جائزة تورينج (جائزة نوبل في الحوسبة)، ليلقي قنبلة بحثية هادئة، لكن مفعولها قد ينسف المسار الحالي للذكاء الاصطناعي بأكمله.
في هذا المقال:
- يرى "يان ليكون" أن نماذج مثل ChatGPT وGemini مجرد "ببغاوات إحصائية" تتنبأ بالكلمات دون فهم حقيقي للواقع أو السببية.
- نموذج ميتا الجديد لا يعتمد على توليد النصوص أو الصور، بل يتنبأ بـ "المعنى" في حيز تجريدي، مما يجعله أكثر كفاءة ودقة.
- البيانات التي يعالجها طفل في الرابعة من عمره تفوق كل النصوص التي تدربت عليها النماذج العملاقة، مما يجعل "الرؤية" هي مفتاح الذكاء الحقيقي.
- يحل النموذج الجديد معضلة "التخطيط الهرمي" المفقودة حاليًا، مما يفتح الباب لجيل جديد من الروبوتات المنزلية والقيادة الذاتية الواعية.
🔴 الورقة البحثية الجديدة التي نشرتها ميتا بعنوان VL-JEPA لا تقدم مجرد تحديث للخوارزميات الحالية، ولا تبحث عن منافسة GPT في كتابة القصائد أو تلخيص الإيميلات. إنها إعلان صريح عن فلسفة جديدة وشجاعة تقول: اللغة ليست هي الذكاء... والتنبؤ بالكلمة التالية هو طريق مسدود.
هل نحن حقًا أمام نهاية هيمنة نماذج اللغة الكبيرة (LLMs)؟ وهل كانت الشركات طوال السنوات الماضية تستثمر مليارات الدولارات في الاتجاه الخاطئ؟ بعيدًا عن الصخب، لماذا قد يكون هذا هو مستقبل الذكاء الاصطناعي؟
1.لماذا يرى يان ليكون أن ChatGPT غبي؟

لكي نستوعب حجم التغيير الذي تقترحه ميتا، يجب أولًا أن نفكك طريقة عمل النماذج التي ننبهر بها اليوم (مثل GPT-5.2 و Claude و Gemini). هذه النماذج، رغم قدراتها اللغوية المذهلة، تعمل بآلية تسمى التراجع الذاتي (Autoregressive).
ببساطة مخلة، هذه النماذج هي ببغاوات إحصائية فائقة التطور. عندما تسأل ChatGPT سؤالًا، هو لا يفكر في المعنى، ولا يمتلك خطة مسبقة للإجابة. هو يقوم بعمليات حسابية احتمالية معقدة ليعرف الكلمة التي يجب أن تأتي بعد الكلمة السابقة، واحداً تلو الآخر، من اليمين إلى اليسار. هو يكتب المقال كلمة بكلمة، كما لو كان يملأ فراغات في جملة لا تنتهي.

هنا تكمن مشكلة يان ليكون الجوهرية مع هذا النهج. هو يرى أن اللغة هي وسيلة للتواصل، وليست وسيلة للتفكير. ويستدل على ذلك بحقيقة علمية بسيطة ومذهلة: الطفل البالغ من العمر أربع سنوات، الذي قد لا يتقن الكلام بصورة كاملة، قد شاهد واستوعب بيانات بصرية (Visual Data) من العالم الواقعي تفوق بمراحل كل النصوص الموجودة على الإنترنت التي تدربت عليها هذه النماذج العملاقة.
يعرف الطفل فيزيائيًا أنه لو أسقط الكوب الزجاجي على السيراميك سينكسر، بينما الذكاء الاصطناعي النصي قرأ في الكتب أن الكوب ينكسر، لكنه لا يدرك قوانين الفيزياء أو السبب والنتيجة (Causality). هو يحفظ الوصف، لكنه لا يفهم الواقع.
يطرح "ليكون" مقارنة رقمية مذهلة تحسم هذا الجدل. لتدريب نموذج لغوي ضخم (مثل Llama-3 أو GPT-4)، نحتاج لنحو 30 تريليون "توكن" (رمز نصي)، وهو ما يعادل قراءة إنسان لمدة 400,000 سنة متواصلة دون توقف! ورغم هذا الكم المرعب من البيانات، لا يزال النموذج يرتكب أخطاء ساذجة. في المقابل، الطفل البالغ من العمر أربع سنوات، خلال ساعات يقظته (حوالي 16,000 ساعة فقط)، يتلقى عبر العصب البصري بيانات (Visual Data) تقدر بـ 20 ميجابايت في الثانية. هذا يعني أن الطفل يرى في أربع سنوات بيانات تفوق كل النصوص التي تدربت عليها أضخم نماذج الذكاء الاصطناعي في العالم.
V-JEPA 2 Benchmark
المشكلة إذن ليست في "كمية" البيانات، بل في "نوعيتها". النصوص لا تحمل معلومات كافية عن الواقع، بينما الرؤية (Vision) هي المصدر الحقيقي للذكاء.
2.VL-JEPA.. التفكير في المعنى وليس النص
النموذج الجديد الذي طرحته ميتا، المسمى VL-JEPA (Vision-Language Joint Embedding Predictive Architecture)، ينسف الطريقة القديمة تمامًا. الفكرة هنا ليست في توليد الكلمات، بل في التنبؤ بالمعنى.
كيف يعمل هذا العقل الصامت؟ يستخدم "ليكون" تشبيهًا علميًا دقيقًا لشرح هذا الفرق: تخيل أنك تريد التنبؤ بمكان كوكب المشتري بعد 100 عام.
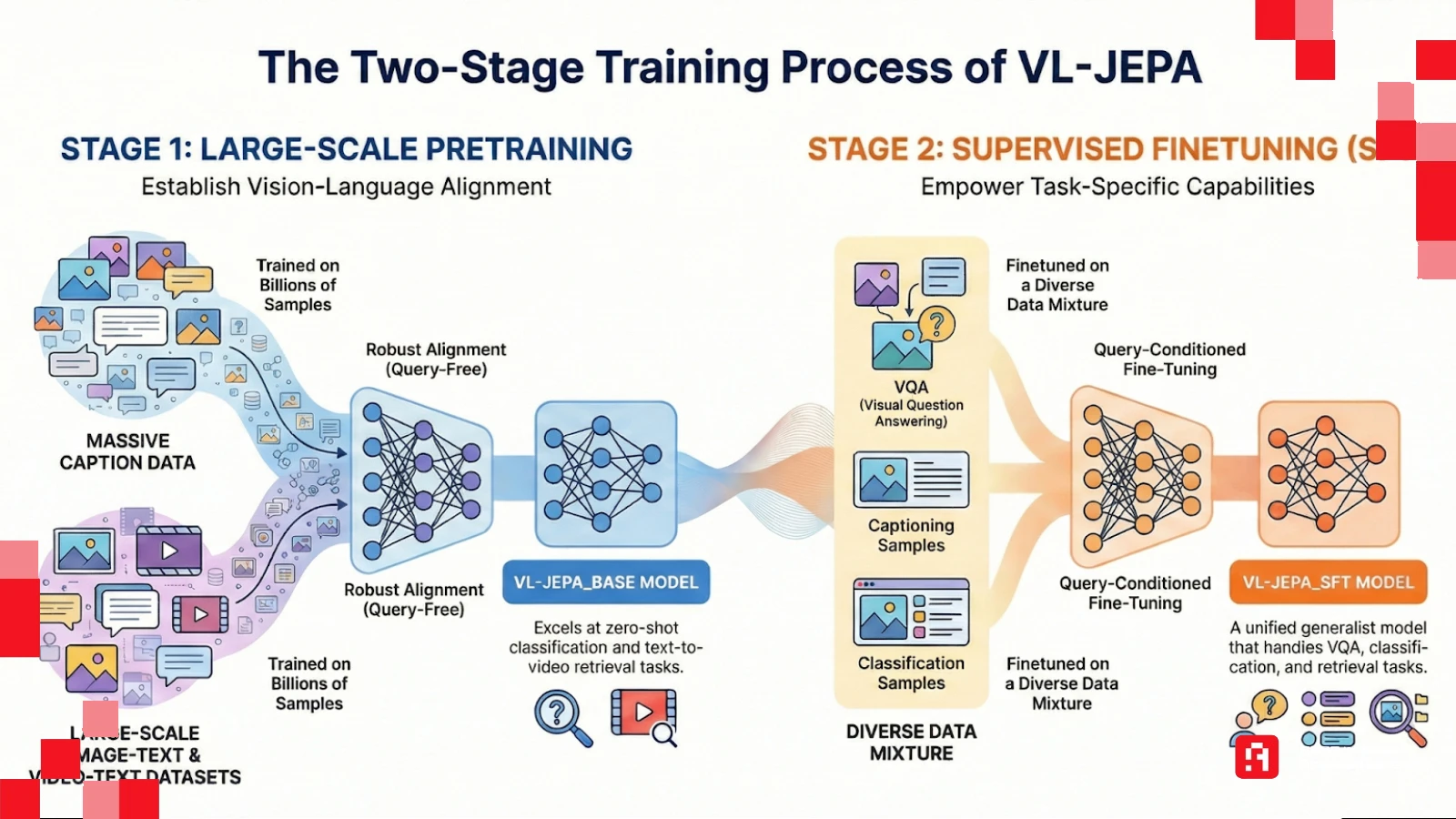
الطريقة التوليدية (القديمة): تحاول محاكاة حركة كل ذرة وكل جزيء غاز في الكوكب لتتوقع مكانه. هذه مهمة مستحيلة حسابيًا وستؤدي لنتائج كارثية بسبب كثرة التفاصيل العشوائية.
طريقة JEPA (الجديدة): تتجاهل الذرات تمامًا، وتركز على "المتغيرات المجردة" (موقع الكوكب، سرعته، مداره). هذا هو "التجريد" (Abstraction) الذي قامت عليه كل العلوم البشرية، وهو ما يفعله JEPA؛ يتجاهل حركة "أوراق الشجر" في الخلفية، ويركز على "مسار السيارة" فقط.
![]()
في الفيديوهات التي عرضتها ميتا لعمل النموذج، تظهر نقاط حمراء ونقاط زرقاء على الفيديو أثناء تحليله.
النقاط الحمراء تمثل تخمينات لحظية قد تكون خاطئة، ولكن بمجرد أن يستقر النموذج على الفهم (النقاط الزرقاء)، فإنه يدرك سياق الحركة بالكامل. هو يفكر مثل البشر تمامًا؛ عندما ترى سيارة مسرعة نحوك، أنت لا تقول لنفسك جملة هذه سيارة تويوتا حمراء تسير بسرعة 100 كم، بل عقلك يدرك معنى الخطر فورًا ويتصرف.
3. الذكاء ليس في ضخامة الحجم
المفاجأة الحقيقية في ورقة ميتا البحثية لم تكن في الفلسفة النظرية فحسب، بل في الأرقام التي أثبتت صحة النظرية وفضحت عدم كفاءة النماذج الحالية.
نماذج اللغة الحالية مثل GPT-4 يُشاع أنها تعمل بمئات المليارات (وربما تريليون) من المعاملات (Parameters)، وتحتاج لمراكز بيانات عملاقة تستهلك كهرباء تكفي لتشغيل مدن صغيرة. الرهان القائم حاليًا في وادي السيليكون هو قانون التحجيم (Scaling Laws): كلما كبرت النموذج، زاد الذكاء.
في المقابل، نموذج VL-JEPA حقق نتائج تتفوق على المنافسين الأضخم منه بمراحل في مهام الرؤية والفهم، وذلك باستخدام 1.6 مليار إلى 2 مليار معامل فقط.
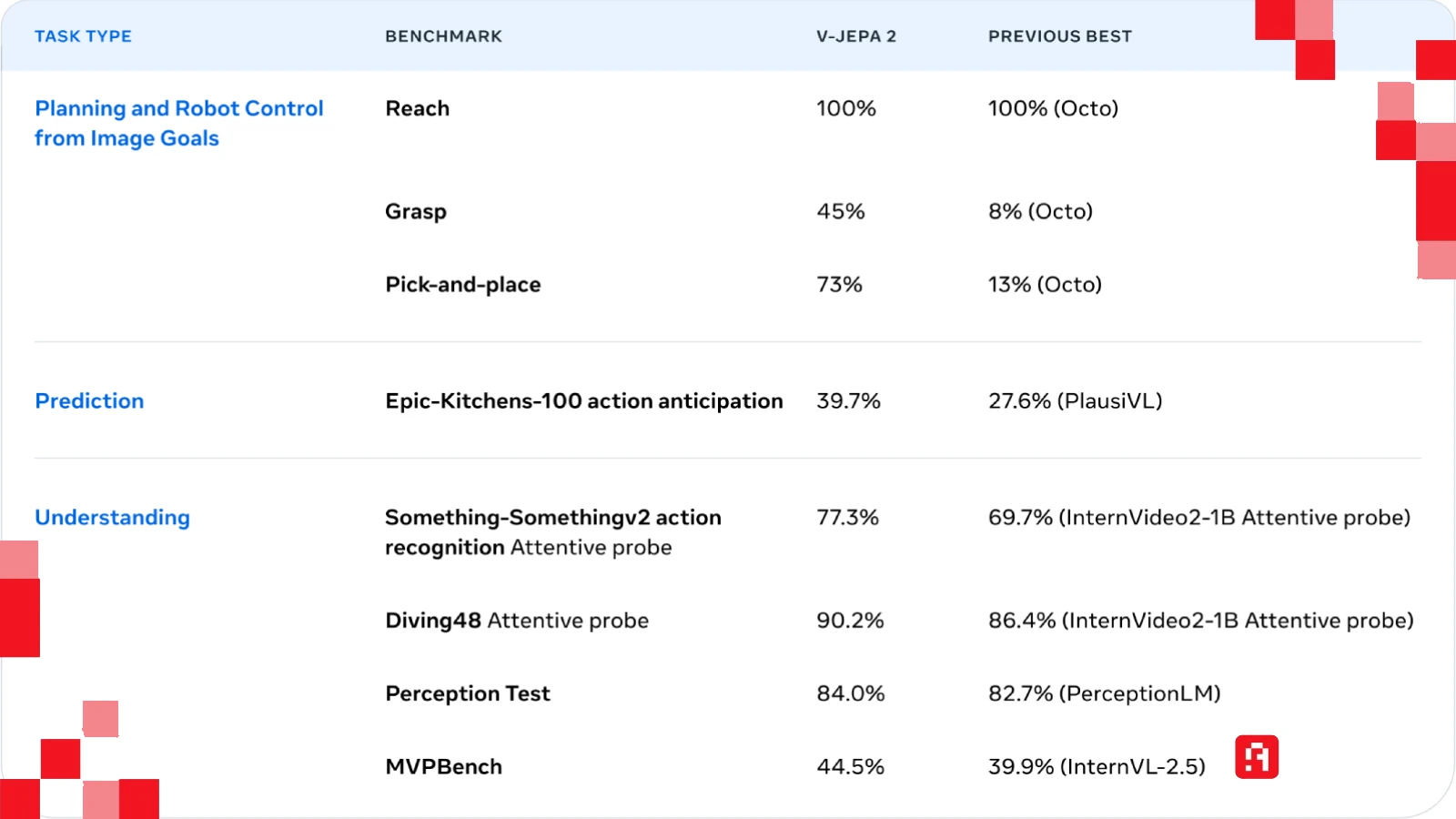
نعم، أنت تقرأ الرقم بشكل صحيح. نموذج بحجم قزم مقارنة بالعمالقة، تفوق عليهم لأنه يفهم ولا يحفظ. هذا يثبت أن البنية المعمارية للنموذج (Architecture) أهم بكثير من حجمه. هذا الاكتشاف يعني أننا قد نرى قريبًا ذكاءً اصطناعيًا حقيقيًا يعمل محليًا على هواتفنا ونظارات الواقع المعزز، دون الحاجة للاتصال بسيرفرات عملاقة، لأنه لا يحتاج لتلك القوة الحسابية المهولة.
4. معضلة "السفر إلى باريس": لماذا تفشل الروبوتات الحالية؟
قد تتساءل: لماذا يهمني هذا الأمر كمستخدم عادي؟ تكمن الإجابة في الفجوة الكبيرة بين الذكاء الاصطناعي الرقمي والذكاء الاصطناعي الفيزيائي. لماذا لدينا بوت يكتب قصائد شكسبيرية، لكن ليس لدينا روبوت منزلي يستطيع إفراغ غسالة الأطباق دون أن يكسر الأطباق؟
السبب هو أن نماذج اللغة (LLMs) عمياء عن العالم المادي. لا يمكنك تعليم روبوت الحركة في العالم الحقيقي عن طريق تغذيته بكتب ومقالات فقط؛ الروبوت يحتاج لفهم الفيزياء، والأبعاد، والزمن، وتوقع عواقب أفعاله.
نموذج VL-JEPA هو حجر الأساس لما يسمى الذكاء الاصطناعي المتجسد (Embodied AI). هذا النموذج يسمح للآلة بمشاهدة الواقع وتوقع ما سيحدث في الثواني القادمة (إذا تركت الزجاجة الآن ستسقط وتتحطم). هذا التوقع هو جوهر الذكاء الذي نحتاجه للسيارات ذاتية القيادة الحقيقية (Level 5)، وللروبوتات التي ستعمل في المصانع والمنازل بحلول عام 2026 أو 2027 كما تتوقع نفيديا وميتا.
في المحاضرة، كشف "ليكون" عن السبب الحقيقي لغياب الروبوتات المنزلية حتى الآن، وهو غياب القدرة على "التخطيط الهرمي" (Hierarchical Planning). النماذج اللغوية (LLMs) تعمل بطريقة التسلسل (كلمة تلو الأخرى)، وهذا كارثي في الواقع المادي. إذا قررت السفر من "نيويورك" إلى "باريس"، عقلك البشري لا يخطط لكل "مللي ثانية" ستحرك فيها عضلات رجلك! بل يخطط بمستويات عليا: (أحتاج للذهاب للمطار -> أحتاج لتاكسي -> أحتاج للنزول للشارع).

النماذج الحالية لا تستطيع فعل ذلك؛ هي تحاول التنبؤ بالخطوة التالية مباشرة فقط، مما يجعلها تتوه في التفاصيل أو "تهلوس" وتخرج عن المسار كلما طالت المهمة (Divergence). نموذج JEPA مصمم ليفهم هذه المستويات المتعددة، مما يجعله الوحيد القادر نظريًا على تشغيل روبوت يقوم بمهمة معقدة مثل "ترتيب المطبخ" دون أن يتوقف في المنتصف لأنه نسي الهدف النهائي.
تطبيقات ستغير حياتك اليومية
إذا كنت تعتقد أن هذا النموذج مخصص فقط للمصانع، فأنت مخطئ. رؤية "يان ليكون" تتجاوز الروبوتات لتصل إلى أجهزة نستخدمها أو سنستخدمها قريبًا. نموذج JEPA هو المفتاح السحري لثلاث تقنيات كانت تنتظر "عقلًا" حقيقيًا لتعمل:
- نظارات الواقع المعزز (AR Glasses): تستثمر ميتا المليارات في نظارات (Project Orion) و Ray-Ban Meta. حاليًا، المساعد الذكي في النظارة يعتمد على وصف ما يراه نصيًا (Image-to-Text). مع JEPA، النظارة لن "تصف" المشهد فقط، بل ستفهمه. تخيل أنك تنظر إلى "محرك سيارتك المعطل"؛ النظارة لن تقول لك "هذا محرك"، بل ستدرك المشكلة ميكانيكيًاً وترسم لك سهمًا (AR) على القطعة التي يجب فكها أولًا، لأنها تملك "نموذجًاً فيزيائيًا" للمحرك وتعرف عواقب فك هذا البرغي قبل ذاك.
- القيادة الذاتية الحقيقية (Level 5 Autonomy): السيارات الحالية (مثل تسلا) تعتمد على تدريب مكثف على ملايين الفيديوهات للطرق. لكن ماذا لو واجهت السيارة موقفًا لم تره من قبل (شاحنة تسقط حمولة غريبة)؟ النماذج الحالية قد ترتبك. نموذج JEPA لا يحتاج أن يرى الموقف سابقًا ليتصرف؛ هو يملك "حسًاً فيزيائيًا" (Common Sense) يجعله يتوقع أن "الجسم الساقط سيصطدم بي خلال ثانيتين"، فيتخذ قرار المراوغة فورًا دون الرجوع لقاعدة بيانات، تمامًا كما يفعل السائق البشري المحترف.
- المساعد الشخصي الاستباقي: بدلًا من المساعد الذي ينتظر أوامرك (Reactive)، سنرى مساعدًا استباقيًا (Proactive). لأنه يفهم "التسلسل الزمني"، إذا رآك تخرج البيض والدقيق، سيفهم أنك "تعد كعكة" وقد يجهز لك الفرن مسبقًا أو يذكرك بأنك نسيت شراء الفانيليا، قبل أن تبدأ حتى في الخلط. هو يتوقع "المستقبل القريب" بناءً على أفعالك الحالية.
5.هل التفكير لغة؟
- هذه الورقة البحثية أعادت إحياء نقاش قديم جدًا في علوم الإدراك (Cognitive Science): هل التفكير هو اللغة؟
المعسكر الأول (OpenAI, Google): يرى أن اللغة هي وعاء الفكر، وأنه إذا دربنا النموذج على كل لغات وعلوم الأرض، سيصل تلقائيًا للذكاء العام (AGI). لذا هم يستثمرون في تكبير النماذج اللغوية. - المعسكر الثاني (Meta, Yann LeCun): يرى أن اللغة هي مجرد تطبيق أو واجهة إخراج (Output Format) للتفكير. يحدث التفكير الحقيقي في منطقة صامتة ومجردة في الدماغ، حيث تُعالج الصور والأصوات والمشاعر والحقائق، ثم نترجم هذا الخليط إلى كلمات لننقله للآخرين.
ترجح ورقة VL-JEPA كفة المعسكر الثاني. الذكاء الاصطناعي القادر على التفكير الصامت في المعنى، ثم تحويله للغة عند الحاجة، سيكون أكثر كفاءة، وأقل هلوسة، وأكثر أمانًا من النماذج التي لا تتوقف عن الثرثرة الداخلية.
6. مفترق طرق أم هاوية؟
نحن الآن أمام مفترق طرق تاريخي، أو ما يمكن تسميته بـ هاوية الأتمتة بين عامي 2025 و 2027.
نهاية عصر هندسة الأوامر النصية: المهارة التي يتباهى بها الكثيرون الآن (Prompt Engineering) قد تصبح أقل أهمية. الذكاء القادم سيفهم النية والسياق من العالم المحيط به، ولن يحتاج لشرح نصي دقيق ومفصل.
صعود الوكلاء المستقلين (Autonomous Agents): الانتقال من Chatbot (يجيبك نصيًا) إلى Agent (ينفذ مهام). هذا الوكيل يحتاج لفهم العالم ليتصرف فيه، وVL-JEPA هو العقل المشغل لهذا النوع.
فرص الاستثمار والتعلم: الشركات التي تركز فقط على توليد النصوص قد تكون في خطر. والمستقبل لشركات الروبوتات (مثل Figure و Tesla Optimus) وللشركات التي تبني نماذج العالم (World Models). إذا كنت مطورًا أو مستثمرًا، فهذا هو الوقت المناسب للنظر فيما وراء Chatbots.
هل نودع ChatGPT؟
الإجابة قصيرة المدى هي: لا. سنظل نستخدم النماذج اللغوية للكتابة والتلخيص والترجمة لفترة طويلة، لكن الإجابة طويلة المدى: نعم، هيمنة النموذج اللغوي كعقل وحيد للذكاء الاصطناعي قد انتهت.

نحن نتجه لمستقبل هجين وسنحتاج نماذج اللغة للتواصل معنا كواجهة مستخدم، لكن العقل المركزي الذي يدير العمليات، ويفكر، ويحلل، ويتخذ القرارات، ويوجه الروبوتات، سيكون مبنيًا على معماريات مثل JEPA التي تفهم الواقع ولا تكتفي بوصفه.
ما فعلته ميتا ليس مجرد نشر ورقة بحثية؛ لقد وضعت لافتة كبيرة في منتصف الطريق تقول: الطريق السريع الحالي مسدود... الاتجاه الصحيح من هنا. ومن المثير للسخرية أن الشركة التي تملك أكبر منصة تواصل اجتماعي في العالم (فيسبوك)، هي التي تخبرنا الآن أن الكلام ليس هو أهم شيء.
يختتم يان ليكون محاضرته بنصيحة صادمة قد لا تجعله محبوبًا في وادي السيليكون:
"إذا كنت تريد بناء ذكاء حقيقي، توقف عن العمل على نماذج اللغة (LLMs). تخلى عن النماذج التوليدية (Generative Models) في الفيديو، وقلل من استخدام التعلم التعزيزي (Reinforcement Learning) لأنه غير كفء."
المستقبل بحسب رؤية ميتا، هو للأنظمة التي "تتعلم بالمشاهدة" (Self-Supervised) وتبني نموذجًا داخليًا للعالم، وليس تلك التي تحفظ القاموس.