COMPUTEX 23: شركة NVIDIA تكشف عن حلول ثورية للذكاء الاصطناعي!
بدأ عرض Computex 2023 المُنتظر أخيراً يا سادة، وها نحن ذا مع أول العمالقة التقنيين NVIDIA التي استعرضت اليوم منتجاتها الجديدة والمميزة في المعرض، لتُبهرنا بما عندها من التقنيات والمنتجات الجديدة التي ستجعل حياة المستخدمين أكثر سهولة من ذي قبل. وبدون الكثير من المُقدّمات المملة، دعونا نستعرض ما رأيناه اليوم في حدث NVIDIA.
تقنيات NVIDIA الجديدة
تقنية G-SYNC من الجيل الثاني ULMB (Ultra Low Motion Blur)
قدمت NVIDIA اليوم تقنية G-SYNC من الجيل الثاني ULMB (Ultra Low Motion Blur) التي توفر وضوحًا فعالاً للحركة يصل إلى 1000 هرتز، لتستهدف بها عُشّاق الرياضات الإلكترونية واللاعبين التنافسيين. مع تقنية ULMB 2، تتوقع NVIDIA تقديم إضاءة خلفية بمعدل تحديث كامل، قريبة من ضعف السطوع، وعدم تداخل.

عندما أطلقت NVIDIA تقنية ULMB الأصلية في عام 2015، كانت أوقات استجابة الشاشة (الوقت الذي يستغرقه البكسل في نقل الألوان) بطيئة نسبيًا، مما تسبب في ظهور التشبّح والصور الضبابية بشكلٍ كبير، مما أدى إلى ضعف وضوح الحركة. ولعل أفضل وصف لوضوح الحركة هو القدرة على رؤية وملاحظة الأشياء المتحركة بوضوح.

لذا تُعد الحواف الحادة والتفاصيل غير الباهتة من السمات المميزة لوضوح الحركة الجيد. لتحسين وضوح الحركة، قامت تقنية ULMB بتمكين تقنية تسمى backlight strobing. لتحقيق وميض الإضاءة الخلفية، يقوم ULMB بتعطيل الإضاءة الخلفية بنسبة 75٪ من الوقت. وتعني دورة العمل بنسبة 25٪ على لوحة 300 شمعة كحد أقصى أن الصور ستكون واضحة، ولكن أقل سطوعًا.
مع ULMB الأصلية، سنحتاج إلى الانتظار لفترة أطول حتى تنتقل وحدات البكسل إلى المكان الصحيح قبل تشغيل الإضاءة الخلفية نظرًا لأوقات استجابة البكسل الأبطأ في عام 2015. ولتعويض ذلك، كانت ULMB تقلل معدل التحديث لمنح البكسل مزيدًا من الوقت إلى التحول.
وبسبب هذه العيوب، غالبًا ما كان يختار اللاعبون التنافسيون عدم استخدام الميزة لأن معدل التحديث الكامل والصورة الساطعة كانا مرغوبين أكثر بالنسبة لهم.
الجيل الثاني من G-SYNC Ultra Low Motion Blur 2 (ULMB 2)
يوفر ULMB 2 إضاءة خلفية بمعدل التحديث الكامل وصورًا أكثر سطوعًا، مع الحفاظ على جودة الصورة الأصلية. مع تحسينات وقت استجابة اللوحة من شركائنا في AUO، تمنح ULMB 2 للاعبين المتنافسين وضوح الحركة اللازم للأداء عند مستويات الذروة من خلال إبقائهم في اللعبة عندما تصبح اللحظات فوضوية.

مع ULMB 2، يحصل اللاعبون على وضوح حركة فعال بأكثر من 1000 هرتز مع هذه التحسينات، محسوبة على أساس معدل تحديث الشاشة مضروبًا بواحد على مدار دورة العمل [فعالية الحركة = معدل التحديث * (1 / دورة العمل)].
فبالنسبة لشاشة 360 هرتز مع ULMB 2 على سبيل المثال، فإن وضوح الحركة الفعال هو في الواقع 1440 هرتز. هذا يعني أنه من أجل الحصول على نفس المستوى من وضوح الحركة بدون ULMB 2، سيحتاج اللاعبون إلى لوحة كلاسيكية قادرة على 1440 هرتز.
لإظهار ذلك عمليًا، قمنا بإعداد لوحة اختبار في معملنا. فيما يلي مثال على شاشة 120 هرتز مع إضاءة خلفية مضيئة مقارنة بشاشة 480 هرتز بدون إضاءة خلفية مضيئة: فعالية وضوح الحركة = 480 هرتز = 120 * (1 / 0.25). كما ترى، تبدو متطابقة تقريبًا من حيث وضوح الحركة.

ULMB 2 متاحة الآن
تقنية ULMB 2 متاحة الآن، ولكن لكي تعمل فيجب أن تفي الشاشات بالمتطلبات التالية:
توفر أكثر من 1000 هرتز من وضوح الحركة الفعال
يمكنها تشغيل ULMB 2 بمعدل التحديث الكامل للشاشة
تُقدّم أكثر من 250 شمعة سطوع مع الحد الأدنى من الحديث المتبادل أو الصور المزدوجة
في الوقت الحالي، يوجد بالفعل شاشتان قادرتان على تشغيل تقنية ULMB 2 في السوق، وسيتم إطلاق شاشتين أخريين في المستقبل القريب:
الشاشات المتاحة اليوم هي: Acer Predator XB273U F - 27” 1440p 360 Hz. وشاشة ASUS ROG Swift 360Hz PG27AQN - 27” 1440p 360 Hz.
متوفر قريبا: ASUS ROG Swift Pro PG248QP - 25” 1080p 540 Hz، وشاشة AOC AGON AG276QSG G-SYNC - 27 1440p 360 هرتز.
المعالج الرسومي GH200 Hopper
تم الكشف للتو عن المعالج الرسومي GH200 Hopper من NVIDIA المصنوع من أجل شرائح Grace Hopper Superchips والتي ستعمل على تشغيل أنظمة HGX. الشريحة الآن في مرحلة الإنتاج الكامل، وهي مُعدة لتشغيل أعباء العمل المعقدة للذكاء الاصطناعي، وأجهزة HPC.
وتنضم الأنظمة التي تعمل بنظام GH200 إلى أكثر من 400 تكوين نظام مدعوم بمجموعات مختلفة من بنيات (CPU) و GPU و DPU من NVIDIA بما في ذلك Grace و Hopper و Ada Lovelace و BlueField - التي تم إنشاؤها للمساعدة في تلبية الطلب المتزايد على الذكاء الاصطناعي التوليدي.

في COMPUTEX23 هذا العام، كشف مؤسس NVIDIA ومديرها التنفيذي Jensen Huang عن أنظمة وشركاء جدد وتفاصيل إضافية حول GH200 Grace Hopper Superchip، والتي تجمع بين معمارية Grace CPU و Hopper GPU القائمة على ARM باستخدام تقنية الربط البيني NVLink-C2C.
يوفر هذا عرض نطاق ترددي إجمالي يصل إلى 900 جيجابت / ثانية - أعلى بمقدار 7 مرات من ممرات PCIe Gen5 القياسية الموجودة في الأنظمة التقليدية المتسارعة، مما يوفر قدرة حوسبة مذهلة لمعالجة تطبيقات الذكاء الاصطناعي و HPC الأكثر تطلبًا.
وبهذا فإن أجهزة القياس العالمية الفائقة ومراكز الحوسبة الفائقة في أوروبا والولايات المتحدة من بين العديد من العملاء الذين سيتمكنون من الوصول إلى الأنظمة التي تعمل بنظام GH200.
الحوسبة الكاملة عبر الأنظمة المتسارعة
توفر المجموعة القادمة من الأنظمة التي تم تسريعها بواسطة بنيات Grace و Hopper و Ada Lovelace دعمًا واسعًا لمجموعة برامج NVIDIA، والتي تتضمن NVIDIA AI ومنصة Omniverse وتقنية RTX.
الكمبيوتر العملاق DGX GH200 AI صاحب قوّة الحوسبة الهائلة 1-Exaflop
أعلنت NVIDIA اليوم عن فئة جديدة من أجهزة الكمبيوتر العملاقة ذات الذاكرة الكبيرة والذكاء الاصطناعي - وهو كمبيوتر فائق من فئة NVIDIA DGX مدعوم بشرائح NVIDIA GH200 Grace Hopper Superchips ونظام NVIDIA NVLink Switch System - تم إنشاؤه لتمكين تطوير نماذج عملاقة من الجيل التالي لتطبيقات لغة الذكاء الاصطناعي التوليدية، أنظمة التوصية، وأعباء عمل تحليلات البيانات.



تستخدم مساحة الذاكرة المشتركة الهائلة في NVIDIA DGX GH200 تقنية NVLink interconnect مع نظام NVLink Switch System للجمع بين 256 وحدة GH200 Superchips، مما يسمح لها بالعمل كوحدة معالجة رسوميّة واحدة. ويوفر ذلك 1 إكسا فلوب من الأداء و 144 تيرابايت من الذاكرة المشتركة - أي ما يقرب من 500 مرة من الذاكرة أكثر من الجيل السابق NVIDIA DGX A100، الذي تم تقديمه في عام 2020.
منصة NVIDIA RTX
تدمج منصة NVIDIA RTX تتبع الأشعة، التعلم العميق، التنقيط التقليدي لتحويل العملية الإبداعية بشكل أساسي لمنشئي المحتوى والمطورين، مع دعم الأدوات وواجهات برمجة التطبيقات الرائدة في الصناعة. تجلب التطبيقات المبنية على النظام الأساسي RTX قوة العرض الواقعي في الوقت الفعلي والرسومات المحسّنة بالذكاء الاصطناعي ومعالجة الفيديو والصور لتمكين ملايين المصممين والفنانين من إنشاء أفضل أعمالهم.
التوافر
من المتوقع أن تكون الأنظمة المزودة بشرائح NVIDIA GH200 Grace Hopper Superchips متاحة في وقت لاحق من هذا العام. ومن المتوقع أن تكون أجهزة الكمبيوتر العملاقة DGX GH200 متاحة بحلول نهاية العام.
معمارية Hopper-Next
أكدت NVIDIA أن الشركة ستطلق كروت الشاشة من معمارية Hopper-Next في عام 2024، مما يوفر قفزة هائلة أخرى في الأداء في قطاع HPC و AI.
لم تؤكد NVIDIA أي تفاصيل جديدة لـ Hopper Next ولكن من المعروف أنها خليفة معمارية Hopper الحالية، وستستخدم بالتأكيد نظام تسمية مختلف كثيرًا عن "Hopper Next".
من المحتمل جدًا أن يتم تسمية هذه الشريحة باسم "Blackwell" وهي التسمية التي تم تسريبها العام الماضي. ويمكننا توقع قفزات مماثلة في الأداء كما رأينا مع Hopper مقارنة بـ Ampere.
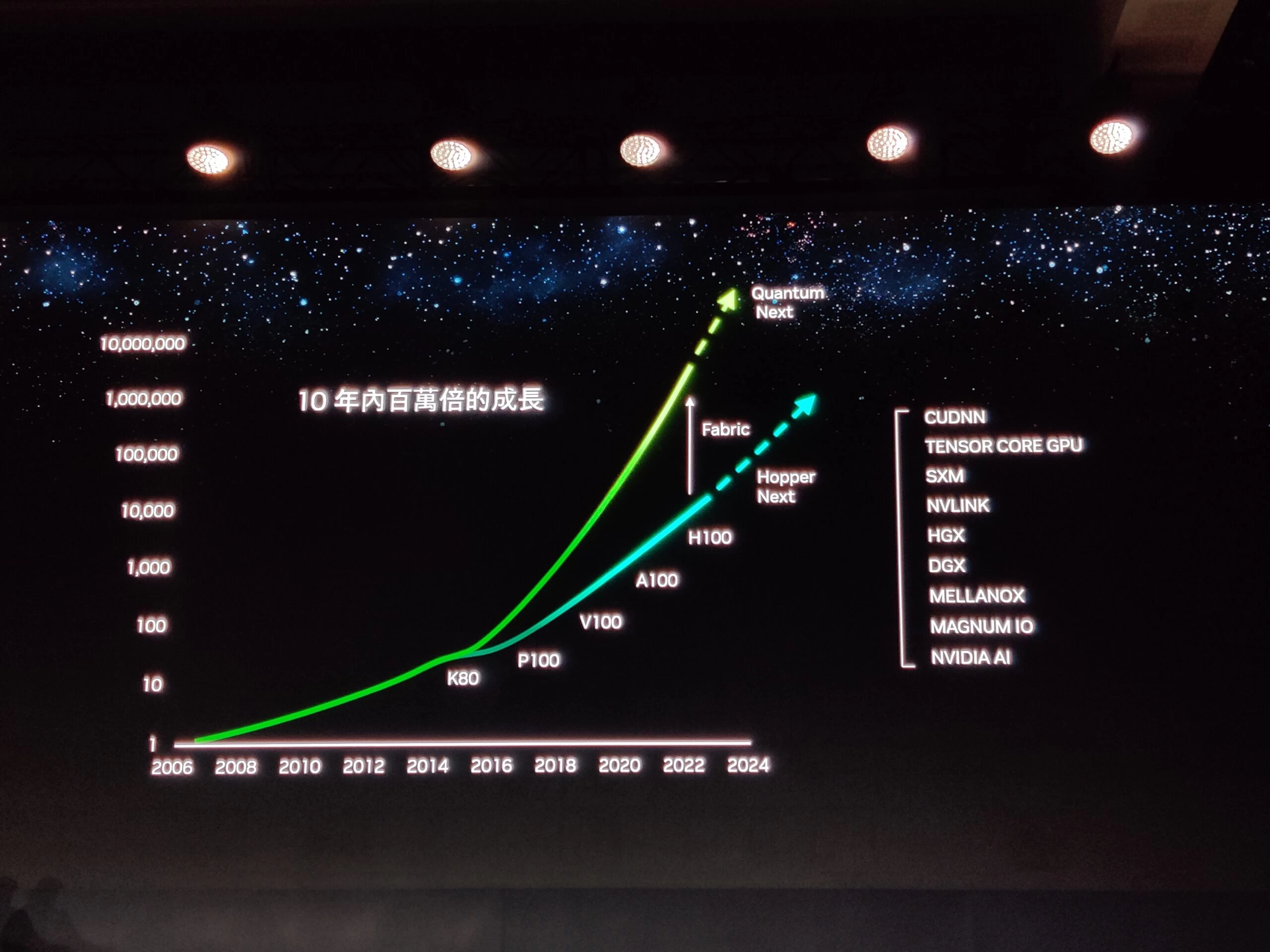
أكدت NVIDIA أيضًا سابقًا أن الشركة ملتزمة تمامًا بإطلاق بنية GPGPU رئيسية كل عامين، وتم إصدار Hopper هذا العام.
كان هذا استجابة للتطورات الجديدة المحتملة في عام 2023، وهو ما يؤكد أن بنية Blackwell GPU سيتم إطلاقها في عام 2024 (نظرًا لأننا نعلم أن هذه هي البنية التي ستخلف Hopper)، وهو الجدول الزمني المتوقع استنادًا إلى إيقاع NVIDIA التاريخي على أي حال.
أكد التسرب السابق وجود ما لا يقل عن اثنين من وحدات المعالجة الرسومية من الجيل التالي هما GB100 و GB102. من المرجح أن تحتفظ كلتا الوحدتين هذه بتصميم أحادي وربما تستخدم عقدة عملية 3 نانومتر الجديدة.
تُعد NVIDIA Hopper حاليًا أسرع معالجات رسومية بتقنية تصنيع 4 نانومتر في العالم، والأولى في العالم بذاكرة HBM3. وهي تتميّز بقدر مهول من القوة الحسابية للذكاء الاصطناعي، وتأتي مُصمّمة للجيل التالي من النماذج التوليدية مثل ChatGPT وما إلى ذلك.
وستستهدف Hopper-Next شريحة مماثلة بأداء أعلى مع التركيز بشكل أكبر على محركات الذكاء الاصطناعي المتخصصة.
يمكننا أن نتوقع مزيدًا من المعلومات حول الجيل التالي من NVIDIA Hopper-Next GPU في حدث GTC 2024 العام المقبل.
NVIDIA تخفض تكلفة تدريب وحدة المعالجة المركزية LLM من 10 ملايين دولار إلى 400 ألف دولار فقط عن طريق استخدام معالجاتها الرسومية
التقطت NVIDIA عددًا لا بأس به من الصور في صناعة المعالجات المركزية في Computex 2023. حيث احتل Jensen المسرح في أول عرض مباشر على الإطلاق بعد 4 سنوات وأعلن بجرأة (وبشكل صحيح تمامًا) عن مكانة الذكاء الاصطناعي التوليدي وتسريع الحوسبة في مستقبل الحوسبة.
قرأ Jensen تأبينًا للحكمة التقليدية لقانون مور، وأعلن أن الوقت الذي يمكنك فيه الحصول على سرعة 10x في 5 سنوات مع الحفاظ على القوة والتكلفة نفسها قد انتهى. في المستقبل، ستأتي معظم عمليات التعجيل من الذكاء الاصطناعي التوليدي والأساليب القائمة على الحوسبة المتسارعة.
NVIDIA تقدم تحليل Large Language Model (LLM) في Comptuex
ماذا يعني ذلك؟ لنبدأ بخط الأساس أولاً. لتدريب نموذج 1 LLM (نموذج لغة كبير)، تحتاج إلى خوادم مع 960 وحدة معالجة مركزية بقيمة 10 ملايين دولار.
أي أن NVIDIA قامت بحساب التكلفة الكاملة التي ستحتاج إليها لبناء مجموعة الخوادم اللازمة لتدريب نموذج لغة واحد كبير (بما في ذلك الشبكات، الهيكل، الوصلات البينية - وكل شيء)، ووجدت أن الأمر سيُكلّفك ما يقرب من 10 ملايين دولار أمريكي، واستهلاك طاقة 11 جيجاواط في الساعة لتدريب نموذج لغة واحد كبير.
من ناحية أخرى، إذا حافظت على نفس التكلفة واشتريت مجموعة GPU بقيمة 10 ملايين دولار، فيمكنك تدريب 44 نموذجًا للغة كبيرة بنفس التكلفة وجزء صغير من تكلفة الطاقة (3.2 جيجاوات ساعة).



إذا انتقلت بدلاً من ذلك إلى نظام طاقة ISO أو حافظت على استهلاك الطاقة كما هو (أي 11 جيجاواط)، فيمكنك في الواقع تحقيق 150 ضعف، من خلال تدريب 150 نموذج LLM مع نفس استهلاك الطاقة البالغ 11 جيجاوات في الساعة، ولكن بتكلفة 34 مليون دولار أمريكي. وستظل مساحة هذه المجموعة أقل بكثير من كتلة وحدات المعالجة المركزية.
وأخيرًا، إذا كنت ترغب في الحفاظ على عبء العمل كما هو تمامًا، فستحتاج فقط إلى خادم من المعالجات الرسومية بقيمة 400000 دولار أمريكي يستهلك 0.13 جيجاوات لكل ساعة لتدريب نموذج LLM واحد.
أي أن ما تريد NVIDIA أن تقوله بشكل أساسي أنه يمكنك تدريب نموذج LLM مع 4 ٪ فقط من التكلفة و 1.2 ٪ فقط من استهلاك الطاقة - وهو انخفاض كبير عند مقارنته بالخوادم القائمة على وحدات المعالجة المركزية!
الشخصيّات الفرعية ستُصبح أكثر ذكاءً في الألعاب...NVIDIA تكشف عن Avatar Cloud Engine (ACE)
كشفت NVIDIA اليوم عن تقنية Avatar Cloud Engine (ACE)، وهو نموذج AI مخصص يدمج الذكاء الاصطناعي في الشخصيات غير القابلة للعب والمعروفة باسم (NPCs) لتفاعلات لغة اللعبة الطبيعية. وهو ما سيُحداث ثورة في تجربة الألعاب بمساعدة الشخصيّات التي تم إنشاؤها بواسطة الـAI.
بمساعدة هذه الأداة، سيتمكن مطورو البرامج والألعاب من إنشاء نماذج فريدة للصوت والمحادثة والحركة ودمجها. يتم تنفيذ المشروع بالشراكة مع شركة Convai، وهي شركة تعمل على تطوير الذكاء الاصطناعي للمحادثة لبيئات الألعاب عبر الإنترنت.

وستقوم NVIDIA بتصميم هذا النموذج على مجموعة من الأُسس:
نموذج NVIDIA NeMo : لبناء النماذج اللغوية وتخصيصها ونشرها باستخدام البيانات الخاصة للشخصية. يمكن تخصيص نماذج اللغات الكبيرة بخلفيات تاريخية وشخصية وحمايتها من المحادثات التي تأتي بنتائج عكسية أو غير آمنة عبر NeMo Guardrails.
نموذج NVIDIA Riva : الذي يقوم بالتعرف التلقائي على الكلام، وتحويل النص المسموعة من اللاعب إلى كلام، وهو ما سيعمل على تمكين محادثة الكلام الحية بين اللاعبين والشخصيات داخل الألعاب.
نموذج NVIDIA Omniverse Audio2Face : لإنشاء رسوم متحركة معبرة لوجه الشخصيات داخل اللعبة على الفور لمطابقة أي مسار للكلام. ويتميز Audio2Face بموصلات Omniverse لـ Unreal Engine 5، بحيث يمكن للمطورين إضافة الرسوم المتحركة للوجه مباشرة إلى شخصيات MetaHuman.
عرضت NVIDIA أيضًا النموذج من خلال إظهار مثال على محادثة تم إنشاؤها بواسطة الـAI مع شخصية NPC. وكما ترون في الفيديو أدناه، تُجيب الشخصية على الأسئلة بناءً على الخلفية السردية من خلال مساعدة الذكاء الاصطناعي التوليدي.

تعد أداة NVIDIA الجديدة بمثابة تقدم كبير في صناعة الألعاب. نحن متحمسون لمعرفة كيفية دمج الذكاء الاصطناعي في الألعاب القادمة لأنه سيغير بشكل كبير تجربة لعب العناوين الجديدة، خاصة عند التعامل مع الشخصيات غير القابلة للعب.
وكما نرى يا سادة، تستفيد NVIDIA من الذكاء الاصطناعي في جميع المجالات، وتُعد الألعاب جزءًا أساسيًا حيث تقدم الشركة أيضًا تقنية الضغط العصبي الخاصة بها لتفاصيل تصل إلى 16x، وتدريب طرز DLSS 3 في خوادم NVIDIA للحصول على تفاصيل وجودة محسّنة، بجانب التقنية العتادية مثل تقنية ذاكرة التخزين المؤقت الجديدة التي تُحسّن أداء الـpath tracing في عناوين مثل Cyberpunk 2077 التي تستخدمها.