ميتا تكشف عن نموذج ذكاء اصطناعي يتعرف على عناصر لم يتدرب عليها من قبل!
كشفت ميتا عن نموذج ذكاء اصطناعي جديد بإسم «Segment Anything Model» يملك شبه وعي يمكّنه من التعرف على عناصر داخل الصور ومقاطع الفيديو حتى لو يدرب عليها من قبل!
مع تركيز مارك زوكربيرغ على تتويج نفسه ملكاً للميتافيرس ومحاولة إقناعنا بأهميتها، سارعت شركة ميتا المالكة لفيسبوك وإنستغرام إعادة حساباتها، لتنضم رسمياً إلى حرب الذكاء الاصطناعي الذي أصبح ترنداً ممتداً لشهور طويلة. حيث كشفت الشركة في الخامس من إبريل (ليست كذبة إبريل) عن نموذج ذكاء اصطناعي جديد قادر على تحديد العناصر الموجودة داخل الصور ومقاطع الفيديو المتنوعة؛ ليصبح بذلك النموذج الأول من نوعه القادر على القيام بمثل ذلك الأمر.
حيث نشر قسم الأبحاث في شركة ميتا ورقة بحثية تتحدث عن نموذج الشركة الجديد، والذي أطلقت عليه اسم "Segment Anything Model" أو "SAM" اختصاراً، ولعل الأمر الملفت فيه أنه سيتمكن من تحديد أي عنصر داخل الصور أو مقاطع الفيديو حتى لو كان ذلك العنصر خارج البيانات التي تدرب عليها.
يتيح نموذج ميتا الجديد إمكانية تحديد عناصر الصور عن طريق النقر عليها أو تحديدها نصياً، حيث يمكن على سبيل المثال كتابة "قطة" ليقوم SAM بتحديد جميع القطط الموجودة في الصورة عبر تحديد مربعات حولها، بل وشرح تفاصيل كل قطة كلون أذنيها.
جدير بالذكر أن النموذج الجديد دُرّب على قاعدة بيانات أطلقت عليها الشركة اسم "SA-1B" والتي تضم 11 مليون صورة مُرخّصة، تم تقسيمها إلى 1.1 مليار جزء باستخدام موديل SAM، كما صُمّم على الإستجابة اللحظية حتى في تلك الحالات التي يجد فيها عناصر جديدة، ما يجعله مثالياً في تطبيقات الواقع المعزز على سبيل المثال، التي يرتدي المستخدم فيها نظارة يتفقد من خلالها العناصر الموجودة في العالم الإفتراضي.
أتاحت ميتا تجربة النموذج الجديد عبر الموقع الرسمي ومن خلال تجربتنا له لاحظنا الدقة الشديدة في تحديد العناصر المختلفة، فنحن لا نتحدث هنا عن معرفة أن الصورة تضم شخصا أو اثنين، بل يمكن فعلياً فصل أجزاء دقيقة جداً من الصورة، فكما يظهر بالصورة التالية، تمكنا بواسطة زر بسيط من فصل جميع الطبقات الموجودة في الصورة -حتى أصغرها- وبدون أي تداخل بين طبقة والأخرى.

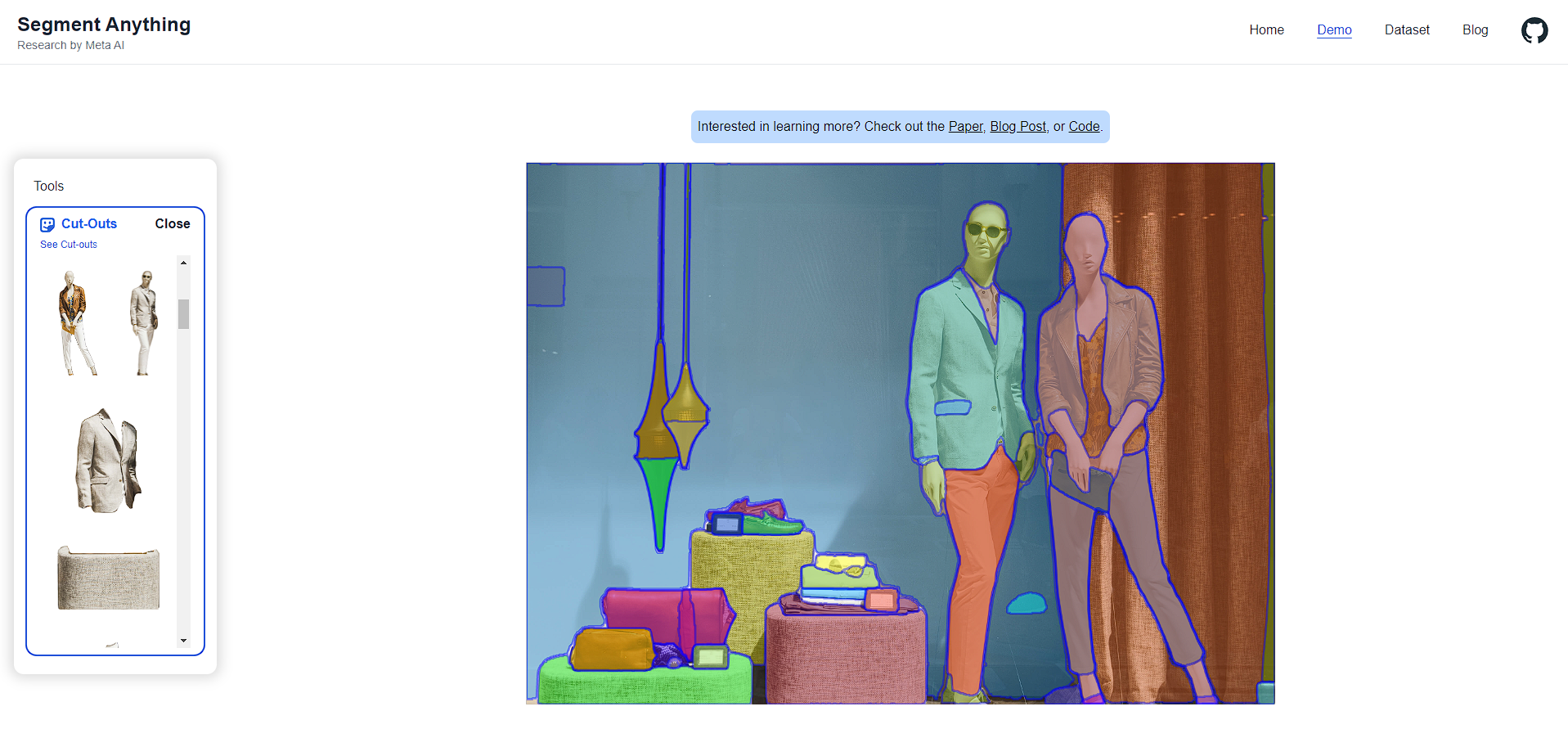
كل لون في الصورة يمثل طبقة منفصلة وعلى الجهة اليسرى تجد جميع تلك الطبقات مفصولة بشكل دقيق بنسبة 100%، السبب وراء تلك الدقة اللامتناهية يتمثل في أن أن نموذج سام يفصل العناصر وفقاً لتعرفه عليا، بطريقة أشبه بوعي بسيط مستند على كمية الصور المهولة التي درب، وعند المقارنة بأداة فوتوشوب من أدوبي على سبيل المثال، فعملية فصل العناصر خلالها تتم حسب فروقات الألوان والإضاءة بين كل طبقة والأخرى، وهي نفس الطريقة التي تعمل بها أي أداة فصل عناصر أخرى.
أوضحت ميتا أن الهدف وراء تطوير نموذج SAM هو تسهيل تسهيل تحليل الصورة أو معالجتها، وبالتالي سيكون استخدامها مفيداً في عدة مجالات منها تطبيقات الواقع المعزز بجانب فهم محتوى صفحات الويب وتحرير الصور وحتى في الدراسة العلمية عن طريق تعريف الحيوانات أو الكائنات تلقائيًا وتتبعها في مقاطع الفيديو.
نماذج تحليل وفصل الصور ليس بالأمر الجديد، ولكن المثير للإعجاب في نموذج ميتا هو إمكانية تعرفه على عناصر لم يُدرّب عليها من قبل!
يعتمد نموذج الذكاء الاصطناعي الجديد من ميتا على تقسيم الصورة المطلوب تجزئتها عبر شبكة نقطية، يتم من خلالها جمع جميع البيانات الظاهرة على كل نقطة بشكل منفصل، بالإستعانة بمكتبة البيانات الضخمة المُدرّب عليها، والتي بالمناسبة تتيحها ميتا للعامة ما يعني أننا قد نجد مشاريع أخرى مبنية على مكتبة بيانات ميتا بطريقة مشابهة لنموذج LaMDA اللغوي من جوجل.
جدير بالذكر أن هذه ليست محاولة ميتا الأولى للدخول إلى عالم الذكاء الاصطناعي، حيث أعلنت سابقاً عن أداة منافسة لـ ChatGPT تستطيع القيام بمشاريع كاملة، والتي استخدمتها لكتابة قصة أطفال بسيطة مع الرسومات المرفقة، وأوضحت طريقة عمل الأداة عبر فيديو نشرته على يوتيوب