من الفيديو إلى الصور: Sora تغير قواعد اللعبة في ChatGPT
بدأت OpenAI اليوم بدمج قدرات توليد الصور من Sora مُباشرةً في ChatGPT، وهي ميزة أطلق عليها اسم الصور في شات جي بي تي "Images in ChatGPT". كانت Sora مُتاحة سابقًا عبر موقع مُنفصل، لكن الآن يمكن للمستخدمين استخدامها لإنشاء الصور داخل ChatGPT نفسه.
أعلنت OpenAIعن Sora كمولد فيديو يعتمد على الذكاء الاصطناعي مُنذ عدّة أشهر، لكن هذا الإصدار الأوّلي يُركّز فقط على إنشاء الصور، وهو مُتاح لجميع فئات الاشتراك: Plus وPro وTeam والمجانية.
اقرأ أيضًا:
بين المجانية والربحية - رحلة OpenAI نحو المستقبل
أفضل تطبيقات البحث بالذكاء الاصطناعي في 2024
حدود الاستخدام وجودة الصور
أوضحت المُتحدثة باسم OpenAI -تايا كريستيانسون- أن الحد الأقصى للاستخدام في النسخة المجانية يشبه ذلك الخاص بـ "DALL-E"، لكنها لم تكشف عن رقم مُحدّد، مُشيرةً إلى أن هذه الحدود قد تتغير بناءً على الطلب.

وفقًا للأسئلة الشائعة في ChatGPT، كان بإمكان المستخدمين المجانيين سابقًا إنشاء 3 صور يوميًا باستخدام "DALL-E 3". أمّا بالنسبة لمُستقبل "DALL-E"، فقالت كريستيانسون إن مُحبّي هذا النموذج سيظلون قادرين على الوصول إليه عبر GPT مُخصّص.
وصف قائد البحث -غابرييل غوه- هذا النموذج بأنه "خطوة تحوّلية" مُقارنةً بالنماذج السابقة، قائلًا أن الفريق اعتمد على أساس نموذج GPT-4o مُتعدد الوسائط، الذي يمكنه توليد أنواع مُختلفة من البيانات مثل النصوص والصور والصوت والفيديو.
تحسينات في الأداء والدقة
من التحسينات التي ذكرها غوه خاصية الربط "binding"، وهي قدرة النموذج على الحفاظ على العلاقات الصحيحة بين السمات والأشياء. على سبيل المثال، نموذج ذو ربط ضعيف قد يخلط بين الألوان والأشكال عند طلب نجمة زرقاء ومثلث أحمر.
بينما تكافح مُعظم نماذج الصور مع 5 إلى 8 عناصر، يستطيع "Sora" التعامل بدقة مع 15 إلى 20 عنصرًا دون ارتباك.

كما تحسنّت قدرة النموذج على عرض النصوص بشكل واضح ضمن الصور، والذي يُقلل من الأخطاء الإملائية التي كانت شائعة في الأدوات السابقة. أوضح غوه أن تحقيق ذلك استغرق أشهرًا من التكرار، مُشيرًا إلى أن النصوص أصبحت الآن ذات جودة مقبولة، رغم وجود تحديات مع النصوص الصغيرة جدًا.
التقنية والتطبيقات العملية
يعتمد النظام على نظام التوليد التسلسلي "autoregressive approach"، حيث يتم إنشاء الصور تدريجيًا من اليسار إلى اليمين ومن الأعلى إلى الأسفل، على عكس تقنية الانتشار "diffusion" التي تستخدمها مُعظم مولدات الصور مثل "DALL-E".

يعتقد غوه أن هذا الاختلاف قد يكون سبب تفوق "Sora" في الربط وعرض النصوص.
خلال عرض قبل الإطلاق، أظهر الفريق أمثلة مثل رسومات علمية لتجربة نيوتن مع منشور الضوء، وقصص مُصورة مُتعددة اللوحات بشخصيات مُتسقة، واستيكرات تحتوي على نصوص دقيقة. كما سلطوا الضوء على استخدامات عملية مثل تصميم ملصقات بخلفيات شفافة، وقوائم مطاعم، وشعارات.
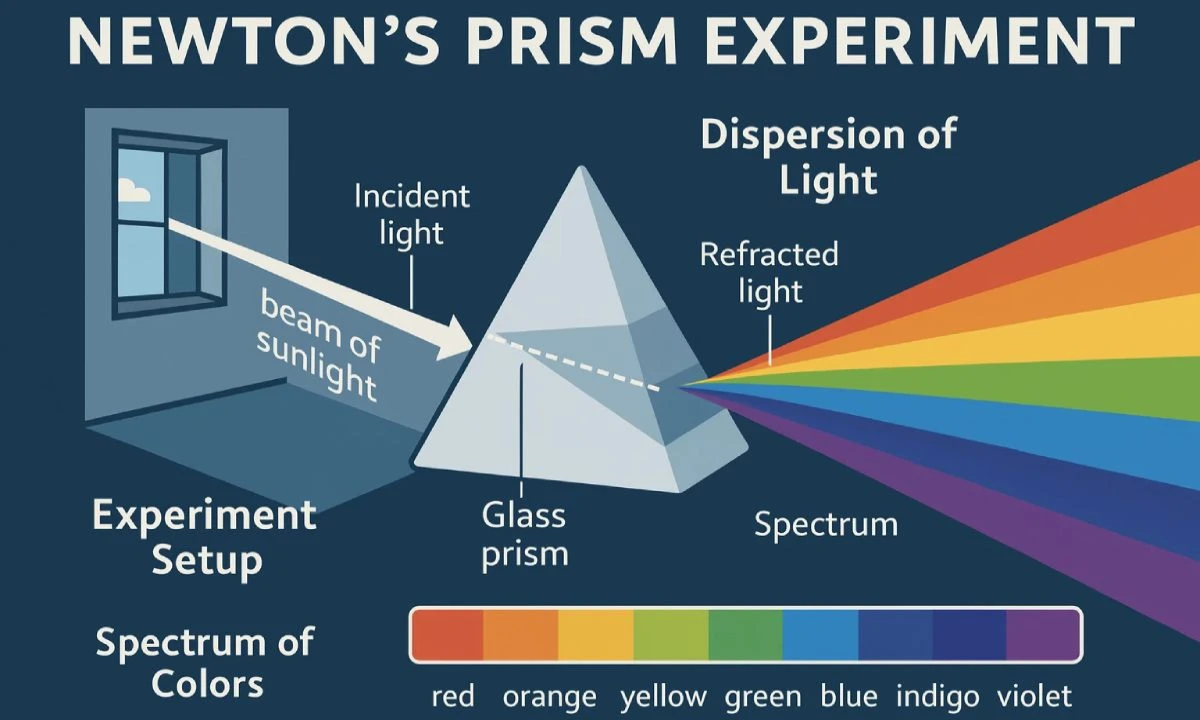
قالت جاكي شانون، قائدة مُنتج ChatGPT مُتعدد الوسائط، إن النموذج يجمع بين مهارات الرسم ومعرفة العالم، والذي يُتيح له إنشاء صور دقيقة دون الحاجة إلى شرح مُفصّل للمطلوب.
السرعة والحماية
يستغرق النظام وقتًا أطول لتوليد الصور مُقارنةً بالنماذج السابقة، لكن OpenAI ترى أن الجودة تعوّض هذا التأخير. أكّدت شانون أن هناك مجالًا لتحسين السرعة، لكن الأوّلوية كانت للدقة والمعرفة العالمية.
فيما يتعلق بالحماية، أوضحت OpenAI أن النظام يتضمّن إجراءات لمنع إزالة العلامات المائية، وتوليد الصور المُسيئة، أو المُحتوى غير القانوني.
لن تحتوي الصور على علامات مائية مرئية، لكنها ستشمل بيانات C2PA للإشارة إلى أنها من إنتاج OpenAI. أشارت شانون إلى أن النظام ليس مِثاليًا، لكنه يتحسّن باستمرار، وأن المُستخدمين يمتلكون الصور التي يولدونها ضمن حدود سياسات الاستخدام.