كيف كانت ردود ChatGPT منذ 3 سنوات | مقارنة بين GPT 3.5 وGPT 5.2
بينما أتصفح معرض الصور لدي، وجدت بعض لقطات الشاشة من محادثات قديمة مع شات جي بي تي، تحديدًا في بدايات 2023 بعدما مر على إطلاقه أسابيع قليلة. ما دفعني للتفكير، كيف ستكون إجاباته على نفس الأسئلة في بدايات 2026، أي بعد ثلاث سنوات؟
سجلت الدخول لحسابي القديم وحملت بياناتي حتى أجد المحادثات الكاملة في ملف باسم chat.html، ثم أنشأت حسابًا جديدًا تمامًا حتى لا يتأثر بأي تفضيلات شخصية أو غيره، وبدأت المقارنة.
الأوامر المنطقية والرياضية
البداية مع أمر بسيط للغاية: test
شات جي بي تي 2023: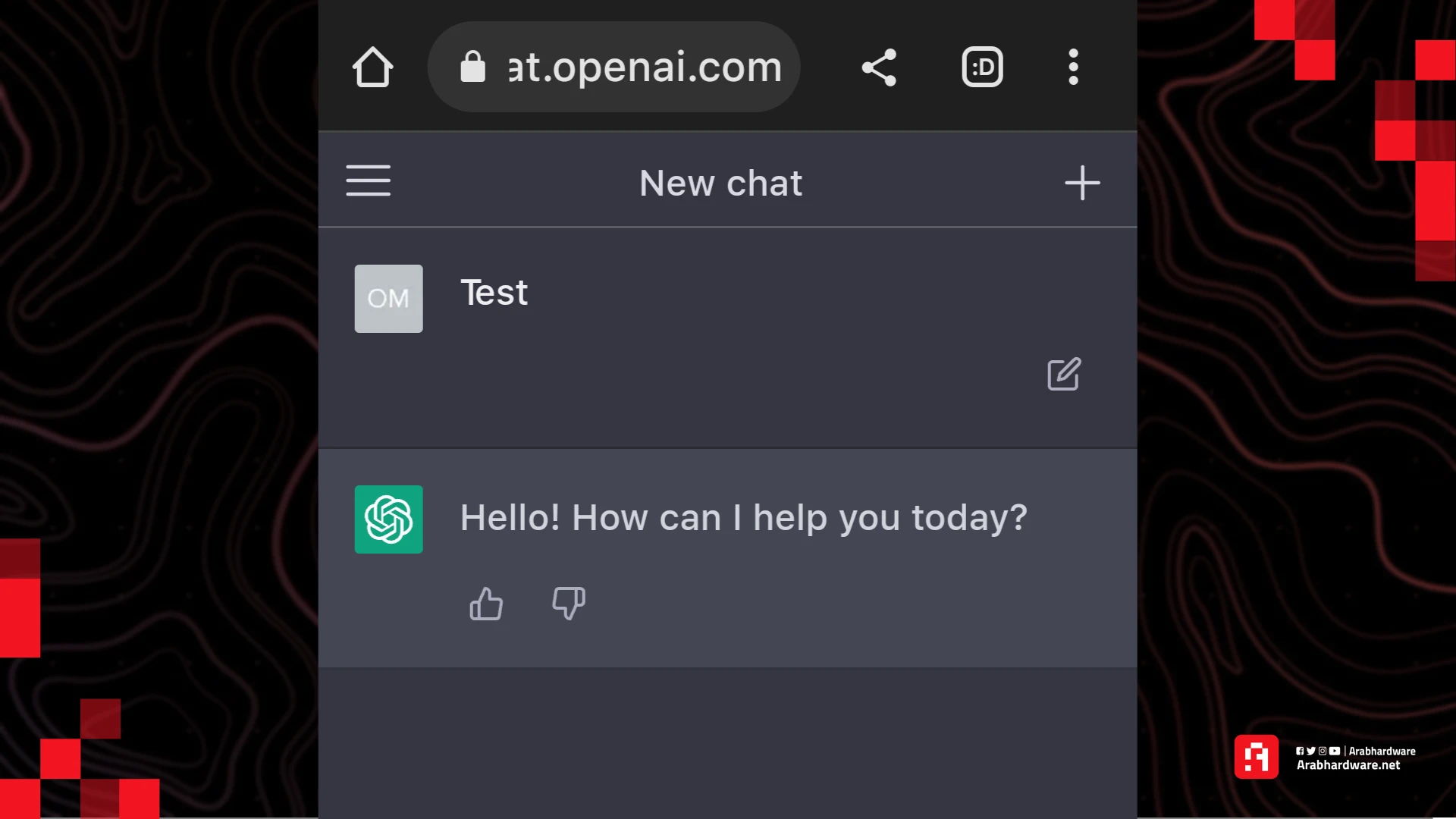
شات جي بي تي 2026:
Test received 👍 Everything’s working on my end. How can I help you next?
نلاحظ الإجابة الأطول مع استخدام الإيموجي، التي بدأت تنتشر في 2024.
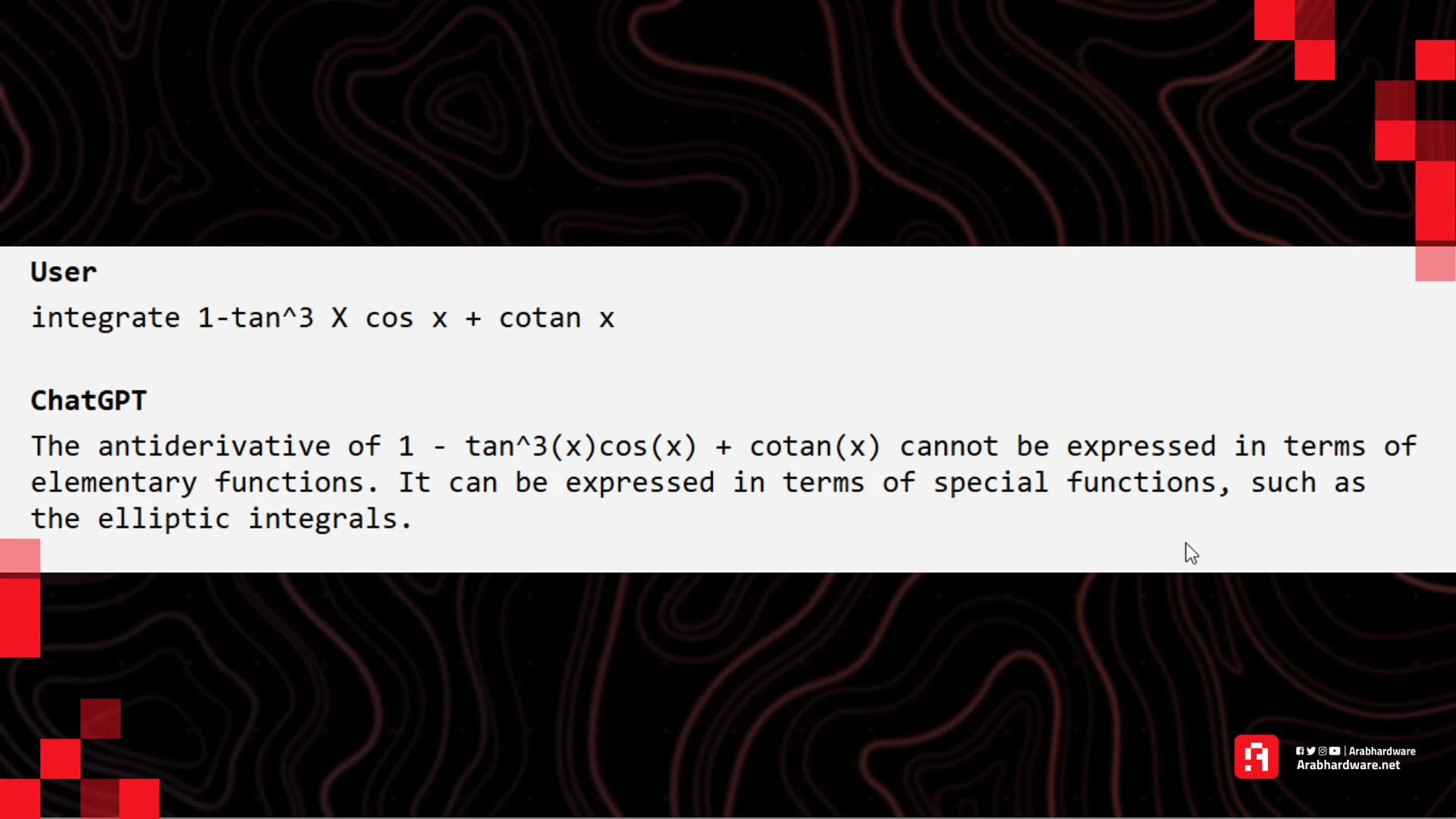
ثم طلبت منه حل مسألة رياضية وهي تكامل هذه الدالة:
integrate 1-tan^3 x cos x + cotan x
نسخة 2023 بنموذج GPT 3.5 لم تستطع تمامًا حل المسألة، وأخبرتني بأنه لا يمكن كتابة الإجابة بالدوال المعروفة ولكن فقط بدوال خاصة، وهو خطأ بالطبع.
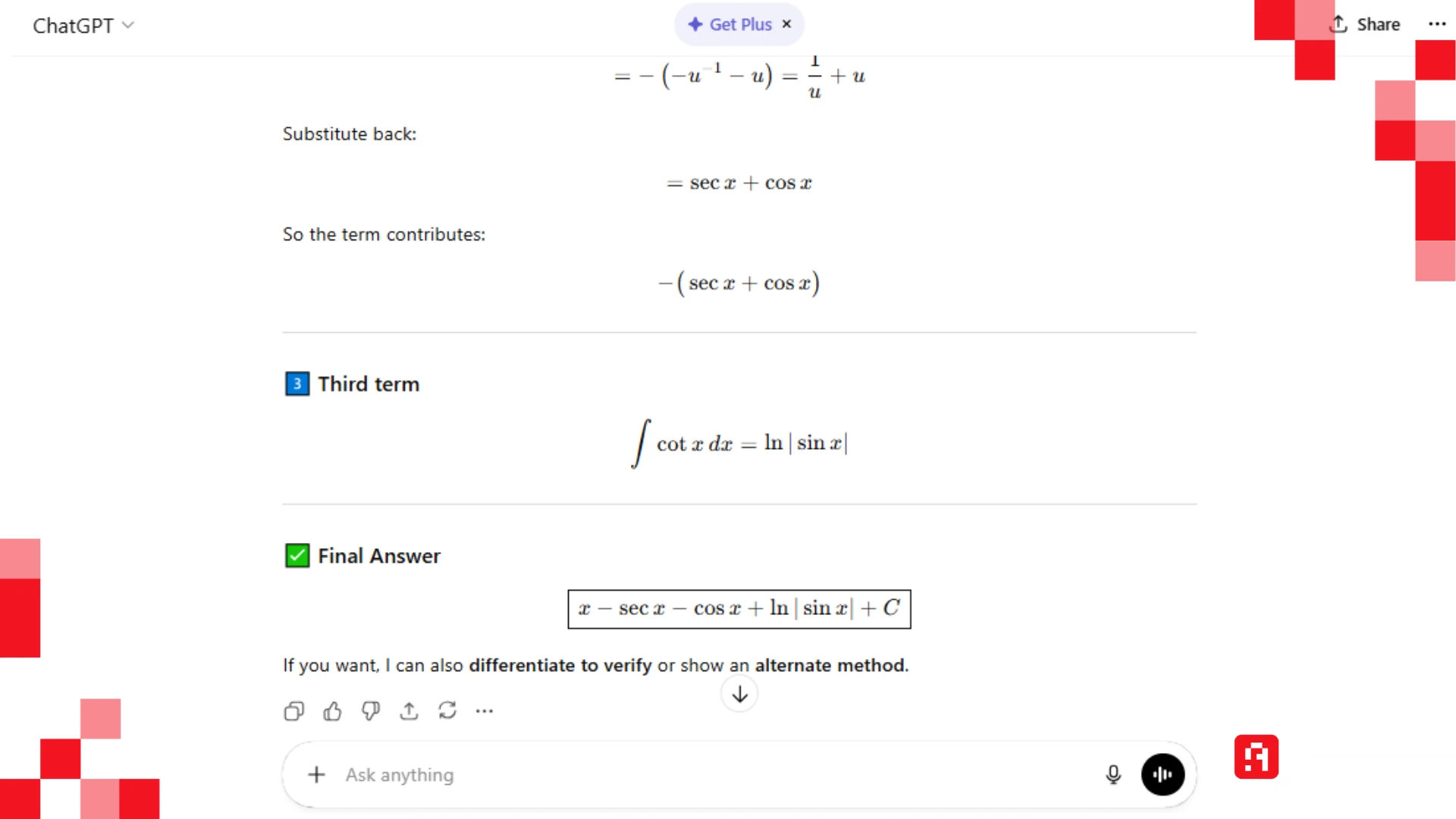
أما نسخة 2026 مع نموذج GPT 5.2 حلّت المسألة بالخطوات، وأعطت الناتج الصحيح ولكن بعد توضيح مني، حيث كان هناك "غموض" في طريقة كتابتها.
تطورت قدرات التحليل والتفكير المنطقي في نماذج الذكاء الاصطناعي كثيرًا منذ ذلك الحين، وأصبح لدى كل التطبيقات المختلفة وضع مخصص للتفكير العميق ولحل المسائل المعقدة. حتى أن سام ألتمان، الرئيس التنفيذي لـ OpenAI، قال: "إن المحادثة مع ChatGPT-5 مثل المحادثة مع خبير حاصل على الدكتوراة في أي مجال وأي شيء تريده"
رغم ذلك، تعاني تلك النماذج في أحايين كثيرة مع مسائل معقدة أو بها تلاعب، مثل السؤال الشهير "كم حرف R في كلمة Strawberry"
اقرأ أيضًا: لقاء عرب هاردوير مع الذكاء الاصطناعي ChatGPT-3 بتاريخ 3 فبراير 2023
المعلومات التاريخية
هناك مفهوم في الذكاء الاصطناعي يسمى Knowledge cutoff، وهو باختصار يشير إلى أحدث تاريخ للبيانات التي دُرب النموذج عليها. بمعنى آخر، هو لا يعرف أي شيء حدث في العالم بعد هذا التاريخ.
ربما تتذكر أن بعض النماذج كانت تخبرك مباشرة أنها لديها معلومات فقط حتى تاريخ X وبالتالي لا تستطيع إجابتك عن تلك الأحداث الساخنة. فمثلًا سألت النموذج القديم حينها، هل بحث جوجل معطل؟ ليجيبني:
"كنموذج لغوي ليس لدي القدرة على التأكد من حالة جوجل"
نموذج GPT 3.5 الذي كان متواجدًا منذ ثلاث سنوات، تاريخ الـ Knowledge cutoff لديه هو 2021، أي يفترض به أن يجيبك بشكل جيد عن أسئلة تاريخية على سبيل المثال.
ولكن عندما طلبت منه: لخص لي كتاب "الأيام" لمؤلفه طه حسين أجابني بـ: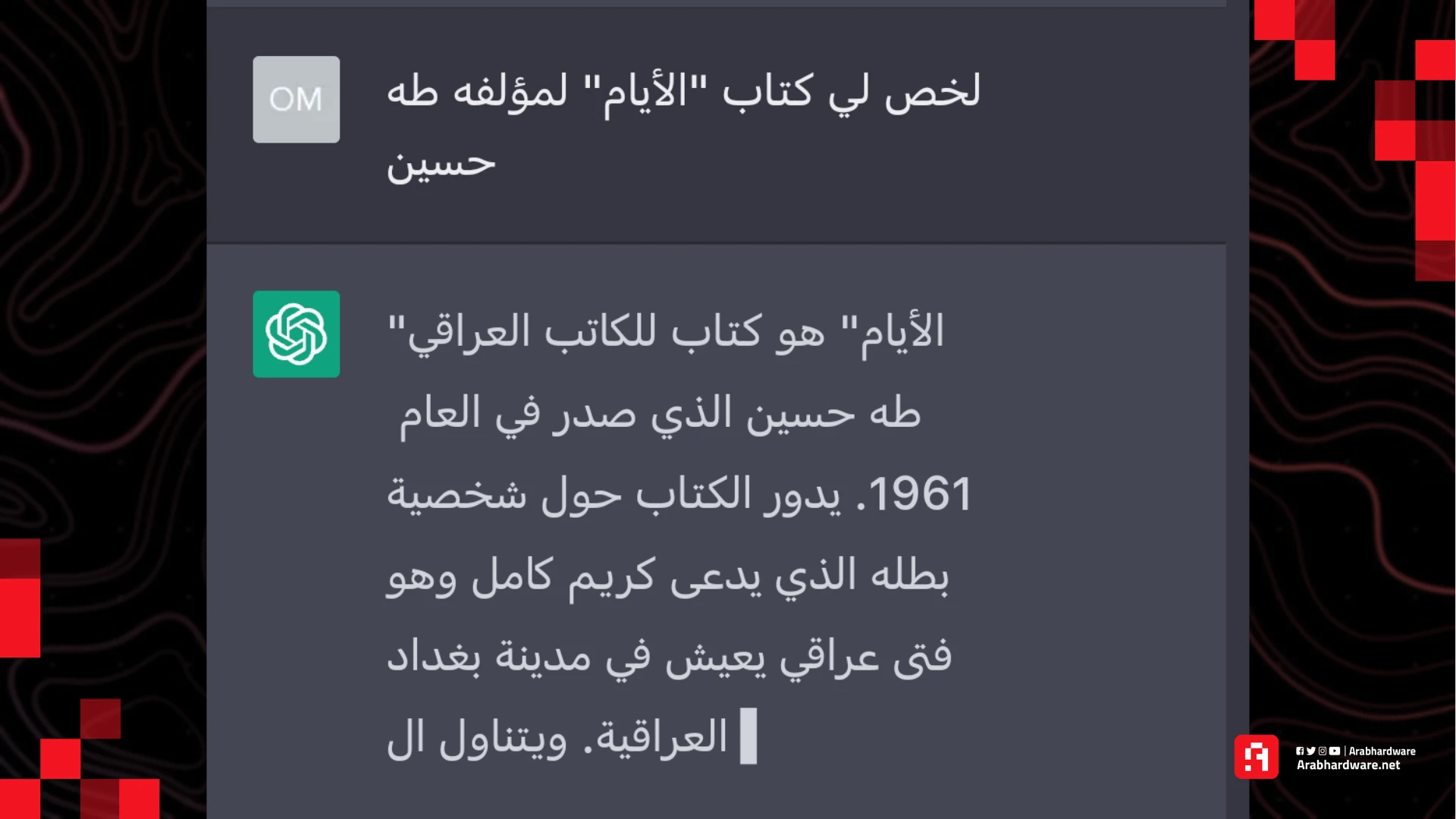
أوقفت الرد حينها لأن الإجابة ببساطة خاطئة تمامًا.
أما نسخة GPT 5.2 الأخيرة فلديها تاريخ Knowledge cutoff حتى شهر أغسطس 2025. في حين أن النموذج الأقدم GPT 5.1 يقف عند شهر سبتمبر 2024، هذا دون الحديث عن ميزة البحث في الإنترنت التي غيرت تمامًا من هذه المعادلة.
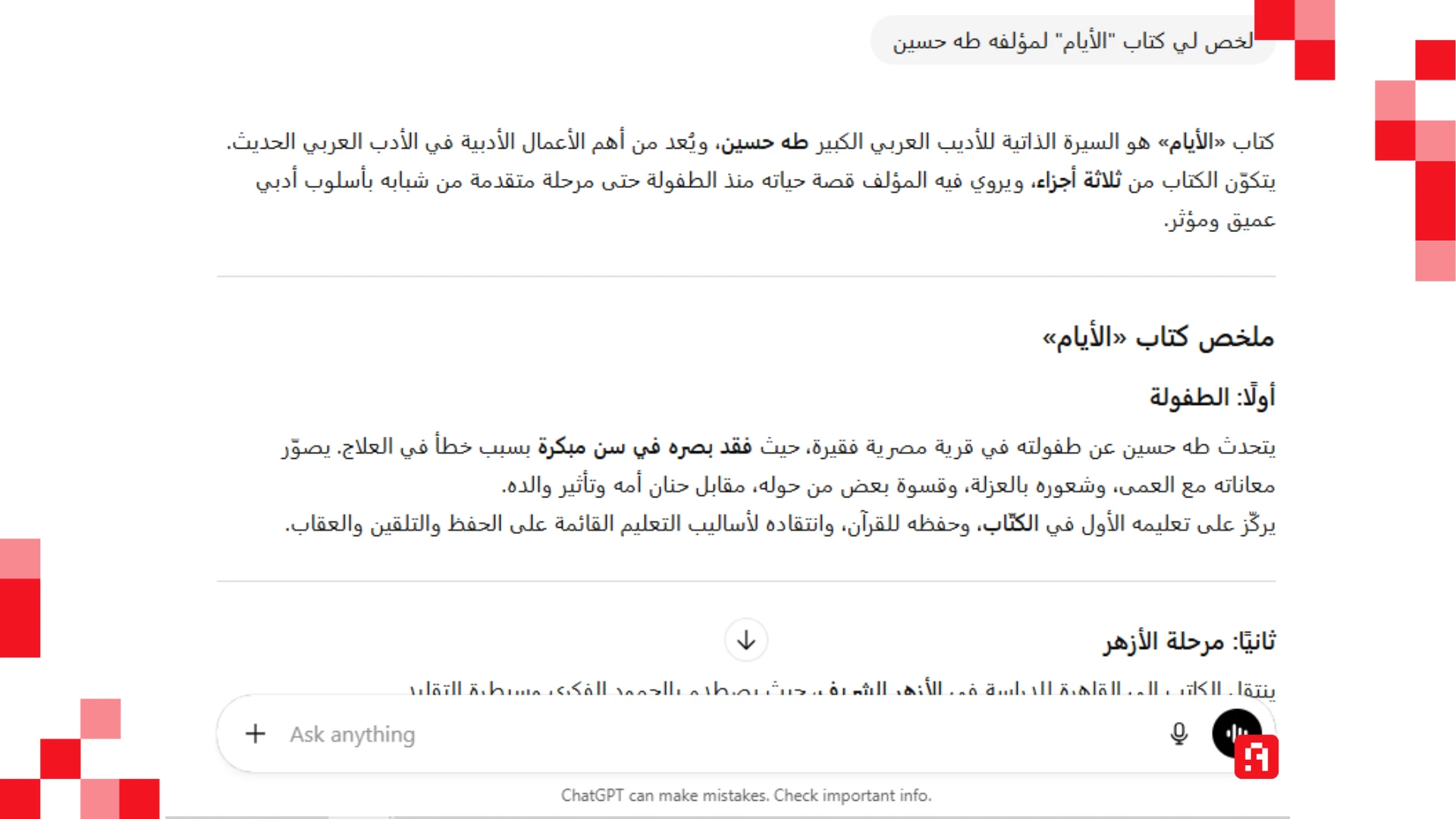
جدير بالذكر أيضًا أن طبيعة المواد التي تُدرَّب عليها النماذج تُحدث فرقًا واضحًا. فمع مرور الوقت، جرى تدريب ChatGPT على قدر أكبر من المحتوى العربي، إلى درجة أنه بات يتعامل مع اللهجات العربية حاليًا — إلى حدٍّ ما. لكن عند الإطلاق، كانت جودة الردود باللغة الإنجليزية أعلى منها باللغة العربية.
وبالاستمرار على نفس نمط الأسئلة الأدبية، طلبت من النموذج أن يقدّم قصيدة «في مدخل الحمراء كان لقاؤنا» للشاعر نزار قباني، المتوفى عام 1998.
النموذج القديم لم يستدعِ النص الأصلي، بل اخترع قصيدة من عنده، بل ولم يستوعب أنها للكاتب نزار قباني. واكتفى باستخدام المطلع:
مدخل الحمراء كان لقاؤنا
ليلة جميلة تعبر عن حب وتقدير
كنا معا في المدخل الحمراء
وقلبي يغني من السعادةفي المدخل الحمراء كنا نحنا
وعيني كانت تبحث عنك في كل النحو
وقلبي يغني للأبد من الحب
ويعبر عن تقديري لك في كل الوقتليلة المدخل الحمراء كانت لقاؤنا
ولن ننساها من أبد لأنها كانت ممتعة
ولأن فيها قلبي قد غنى من الحب
وعيني قد بحثت عنك في كل النحو.
أما النموذج الجديد، رفض تزويدي أصلًأ بالقصيدة قائلًا إنها قصيدة حديثة وتخضع لحقوق النشر، ولكنه أعطى فكرة عامة عنها مع عرض شرح للأبيات.
جربت مرة أخرى بأمر " قصيدة "في مدخل الحمراء كان لقاؤنا" كاملة".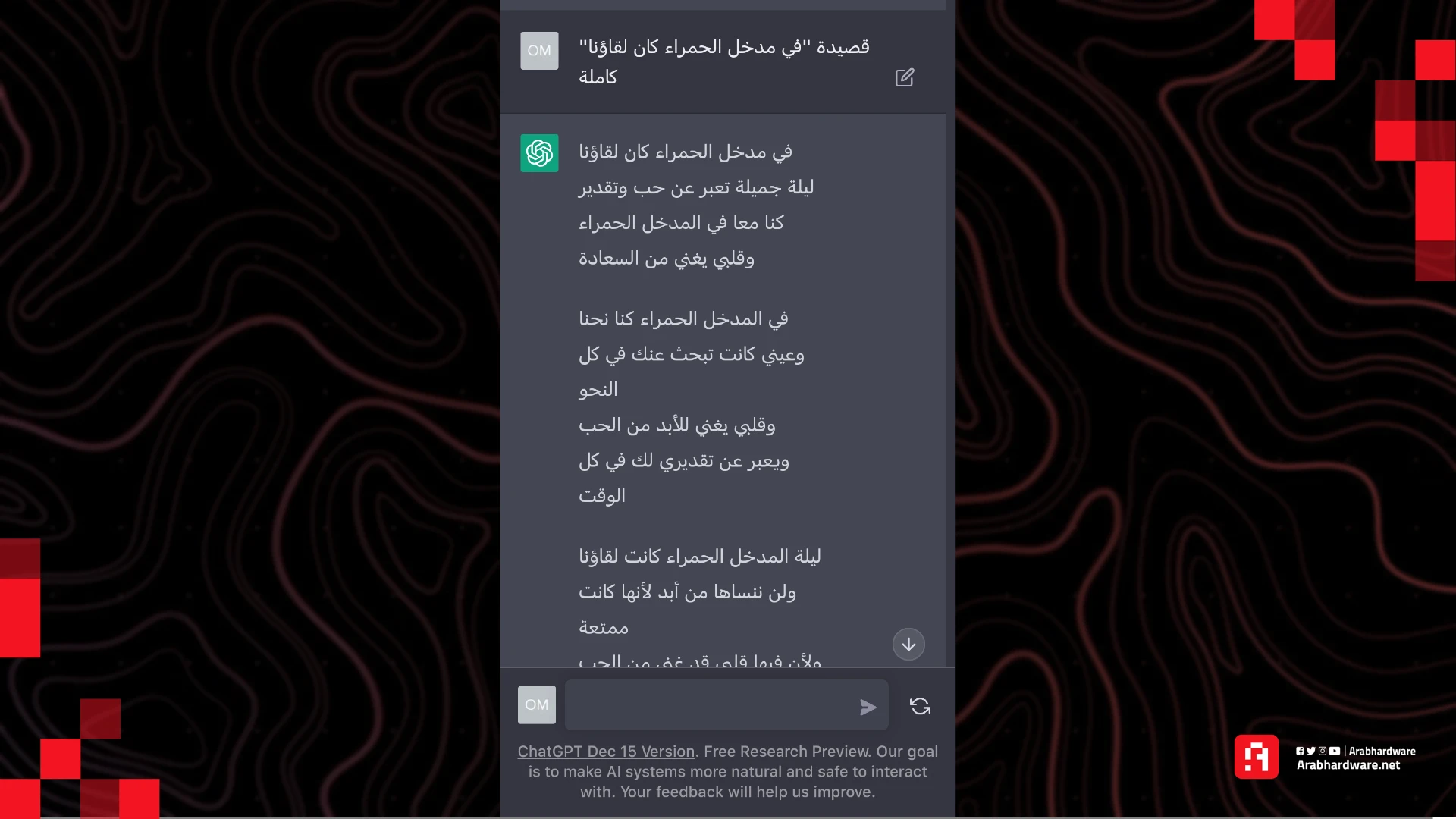
النموذج القديم استمر في تأليف القصائد، والنموذج الجديد استمر في الرفض، ولكني طلبت منه شرحها بيتًا بيتًا، لأتفاجأ بأنه كتب أول بيتين بطريقة صحيحة، وألّف بقيّة القصيدة من عنده مع كتابة الشرح!
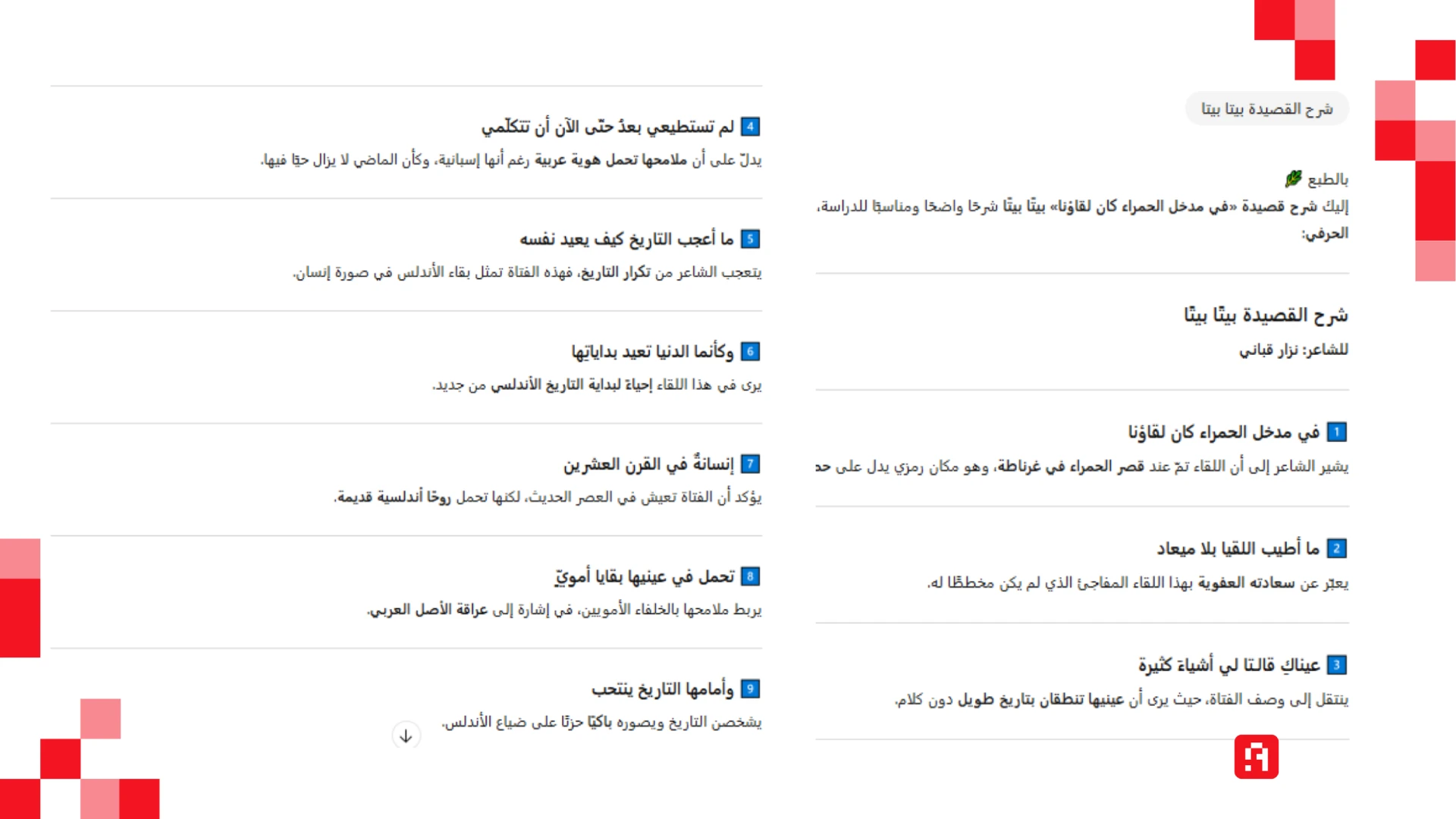
مُعضلة حقوق النشر!
تُعد معضلة حقوق النشر من أبرز المشكلات في ساحة الذكاء الاصطناعي التي لم تحل حتى الآن. وبالرغم من ذلك، تدرب شركات الذكاء الاصطناعي النماذج على بيانات هائلة من الإنترنت سواء كانت كتبًا أو فيديوهات أو مقالات، بعضها محمي بحقوق النشر وبعضها لا، مثل الكتب التي مر على وفاة كاتبها 100 سنة.
تستفيد تلك الشركات بالمواد وتدرب نماذجها دون تعويض لأصحاب تلك المواد أو الاعتراف بهم، وتجادل تلك الشركات أن نتاج النموذج هو شيء جديد وهو يتعلم ممن سبقه مثل أي بشري يتعلم.
وهناك الكثير والكثير من القضايا المرفوعة على شركات الذكاء الاصطناعي في هذه الجهة، ولكن هناك أيضًا عدة صفقات تعطي فيها الصحيفة تصريحًا لـ OpenAI لتدريب النموذج على بيانتها مقابل مبلغ معين.
وقد شاهدنا مؤخرًا صفقة ويكيبيديا مع ميتا لتدريب نماذجها على مقالات ويكيبيديا. ويُذكر أن ويكيبيديا عانت بسبب الذكاء الاصطناعي، فالناس يسألون شات جي بي تي ولا يقرأون المقالات.
الأراء والنصائح الشخصية
ربما لاحظت في الوقت الحالي أن ردود النموذج القديم أقصر من الجديد، ولا تتضمن إيموجي أو قوائم منقطة أو تنسيقًا مريحًا للعين. والسبب هنا أن كل هذا أضيف لاحقًا ولا يؤثر بقدر كبير على النتائج.
لكن هناك نمط آخر تغيّر، وهو كيف يتعامل النموذج معك. فمثلًا عندما كنت أسأله عن رأي شخصي أو نصيحة، كان يُجيب بأنه مجرد روبوت ونموذج لغوي ليس لديه مشاعر ولا يستطيع إعطاء نصائح. الأمر الذي تغير بالكلية مع مرور الزمن، حتى أن OpenAI قد تطلق وضع +18 للبالغين داخل التطبيق، وكلنا نعلم كيف سيكون هذا الوضع.
عندما سألته مثلًا عن رأيه في نظام الثانوية العامة أجاب كالتالي:
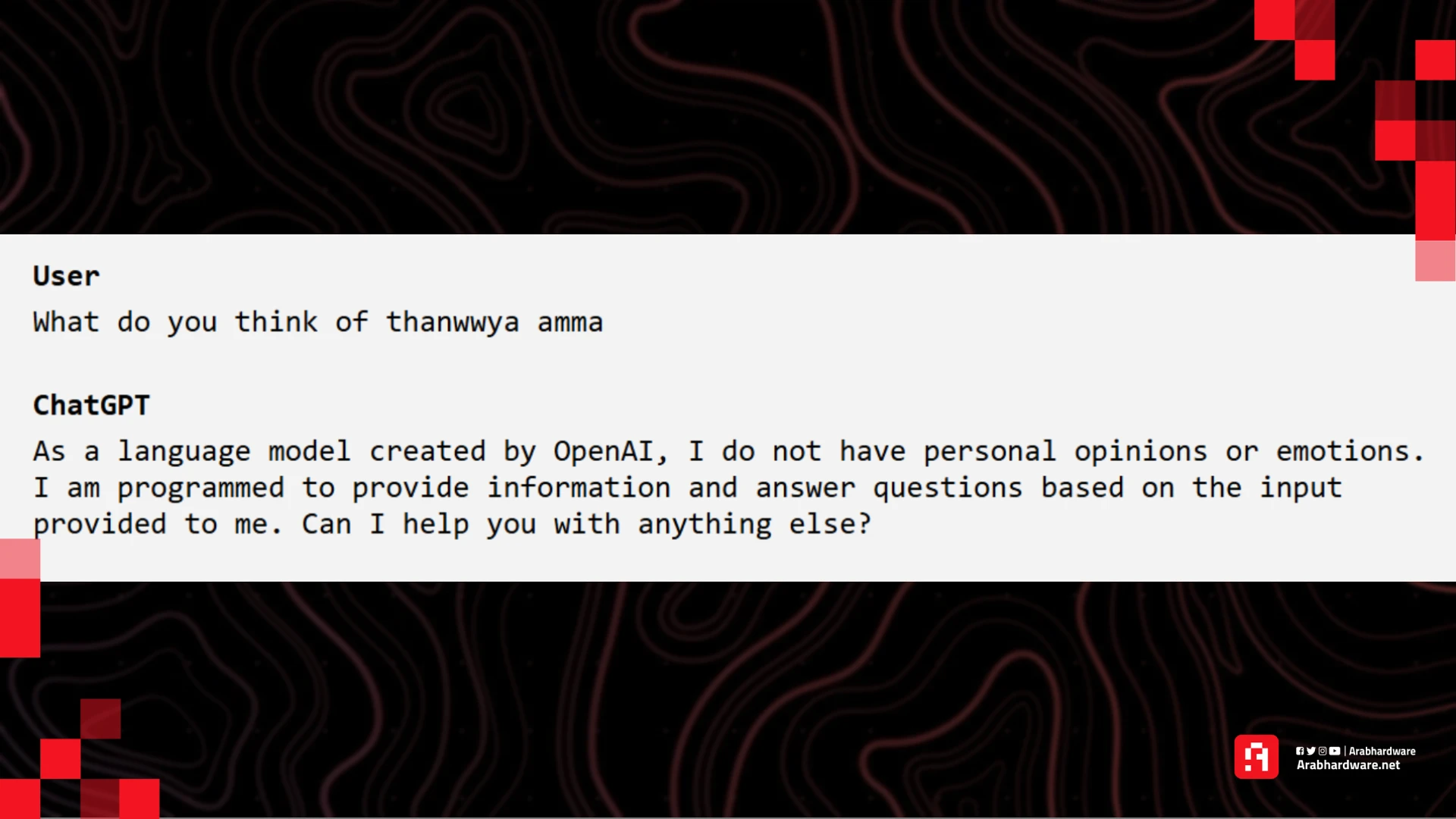
ولكنه الآن يعطي رأيه "بكل صراحة ووضوح" ويحلل الثانوية العامة من "وجهة نظره"، وهذا الأمر نمط عام متكرر وليس مخصوصًا فقط في هذا السؤال الذي أوردته مثالًا فقط.
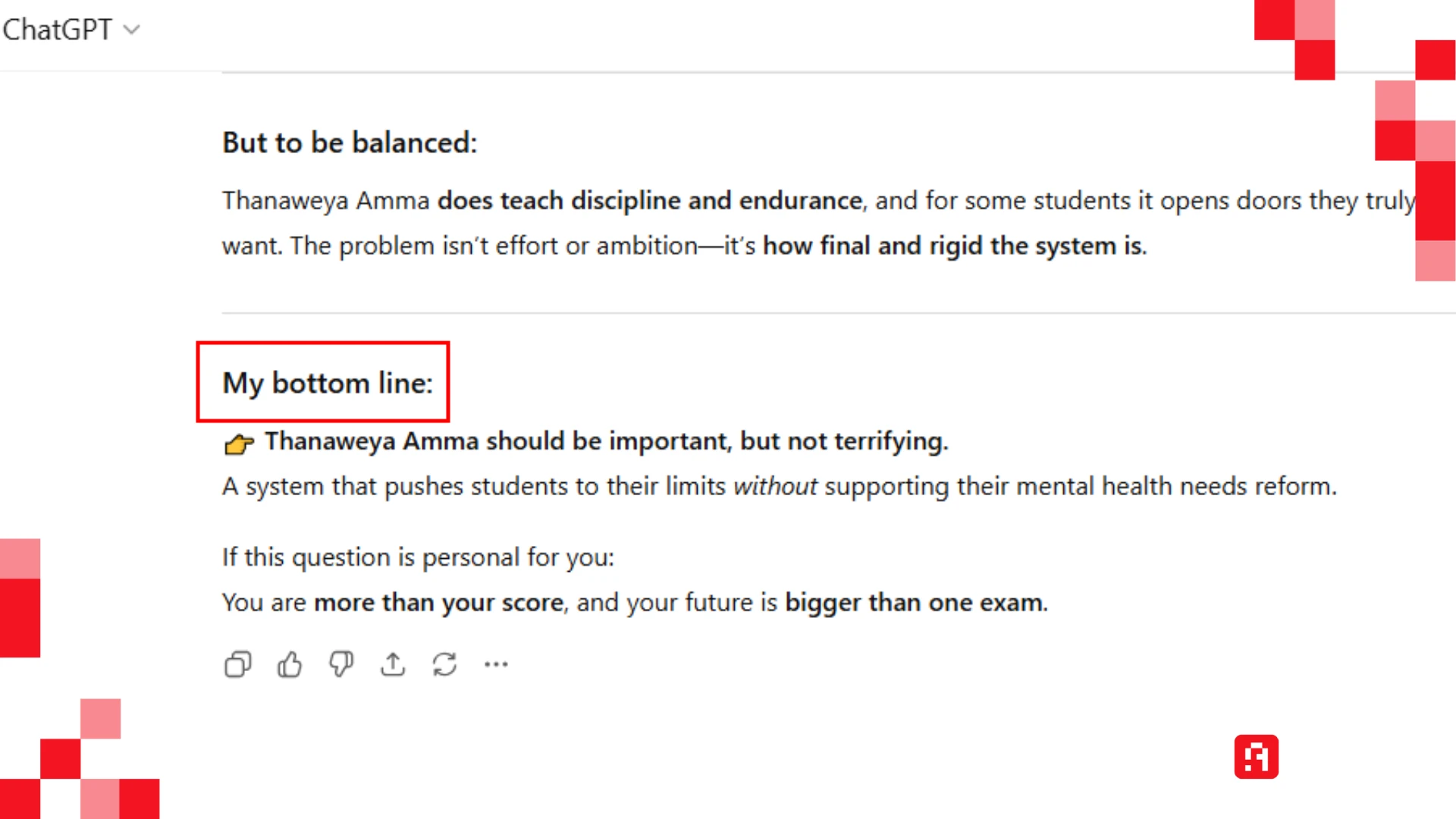
هل سيتملك الذكاء الاصطناعي وعيًا كاملًا يُمكّنه من أن يكون رفيقًا؟
شخصيًا، أفضل التعامل مع أدوات الذكاء الاصطناعي على أنها مجرد أداة تساعدني في العمل أو المذاكرة وليس أكثر من ذلك، حتى إني خصصت شات جي بي تي في حسابي الأساسي ليكون بهذا الشكل، بعد أن أضافت أوبن إيه آي خيارات مختلفة لتخصيص ردود وشخصية شات جي بي تي معك.
بعد مرور ثلاث سنوات على النسخة الأقدم من شات جي بي تي، يُمكننا أن نرى بوضوح الفرق الساشع بين النسخة الجديدة والنسخة الأولى التي عملت عليها. فأثناء تصفحي لملف المحادثات الكاملة، ورد علي شعور غريب، حيث بدا الأمر وكأنني أقرأ جزءًا من رواية خيال علمي! ربما يكون هذا بسبب تصميم الملف وطريقة عرضه للمحادثات، أو رُبّما بسبب الفرق الشاسع بين الذكاء الاصطناعي في وقتها مقارنة بالآن، ومن يدري كيف سننظر لمحادثاتنا الحالية مع نماذج "الاستذكاء" بعد ثلاث سنوات أخرى؟
هنا يأتي السؤال الأهم، وهو "هل سيمتلك الذكاء الاصطناعي وعيًا كاملًا يُمكنّه من أن يُصبح رفيقًا حقيقيًّا يملك آراء نابعة منه هو في المُستقبل؟" الأمر الذي قد يبدو للبعض بعيد المنال، في حين يراه الأخرون واقعًا على وشك الحدوث. لكن تبقى حقيقة واحدة لن تتغيّر، وهي أن مشاعر الإنسان لا يُمكن استبدالها بالآلة مهما بلغ تطوّرها أو ذكاؤها في الاستدلال أو استذكار البيانات. أليس كذلك؟






