
Computex26: كل ما أعلنت عنه NVIDIA في مؤتمرها | مفهوم الحوسبة تغير!
لم يعد الأمر مجرد رقاقات أسرع أو كروت رسومية أقوى أو مجرد تحديثات سنوية روتينية لزيادة الأرقام في اختبارات الأداء. ما حدث في مؤتمر NVIDIA GTC ضمن فعاليات معرض Computex 2026 - المستمر حتى الآن - لم يكن قفزة تكنولوجية اعتيادية، بل كان إعلانًا رسميًا عن إعادة اختراع الحوسبة من نقطة الصفر.
تخيل عزيزي القارئ أنك مقبل على عالم لا يخاطب فيه العتاد البشر، بل يُخدم من خلال ملايين الوكلاء الأذكياء المستقلين الذين يطلبون تريليونات من البيانات في أجزاء من الثانية. عالم تُلغى فيه الكابلات النحاسية لكسر قوانين الفيزياء، وتتحول فيه مراكز البيانات إلى مصانع ضخمة تستهلك طاقة المدن لتوليد الذكاء الرقمي.
من الشبكات السحابية الخارقة المزودة بمعمارية Vera Rubin ومصانع طاقة DSX، مرورًا بالأجهزة الشخصية التي تعمل بقوة RTX Spark بالشراكة مع MediaTek، وصولًا إلى بث الروح والوعي الفيزيائي في الآلات والروبوتات عبر Cosmos 3، وضعت NVIDIA الجميع أمام حقيقة واحدة وهي: لقد انتهى عصر المساعدين الرقميين التقليديين، وبدأ رسميًا عصر العتاد الخارق المصمم من أجل الذكاء المستقل. فكيف تبدو ملامح هذا العالم الجديد؟ لنغص في التفاصيل التي أعلنتها NVIDIA في مؤتمرها.
كيف أعادت NVIDIA صياغة قوانين الفيزياء والذكاء في Computex؟
الذكاء الاصطناعي الوكيل VS الذكاء الاصطناعي التقليدي
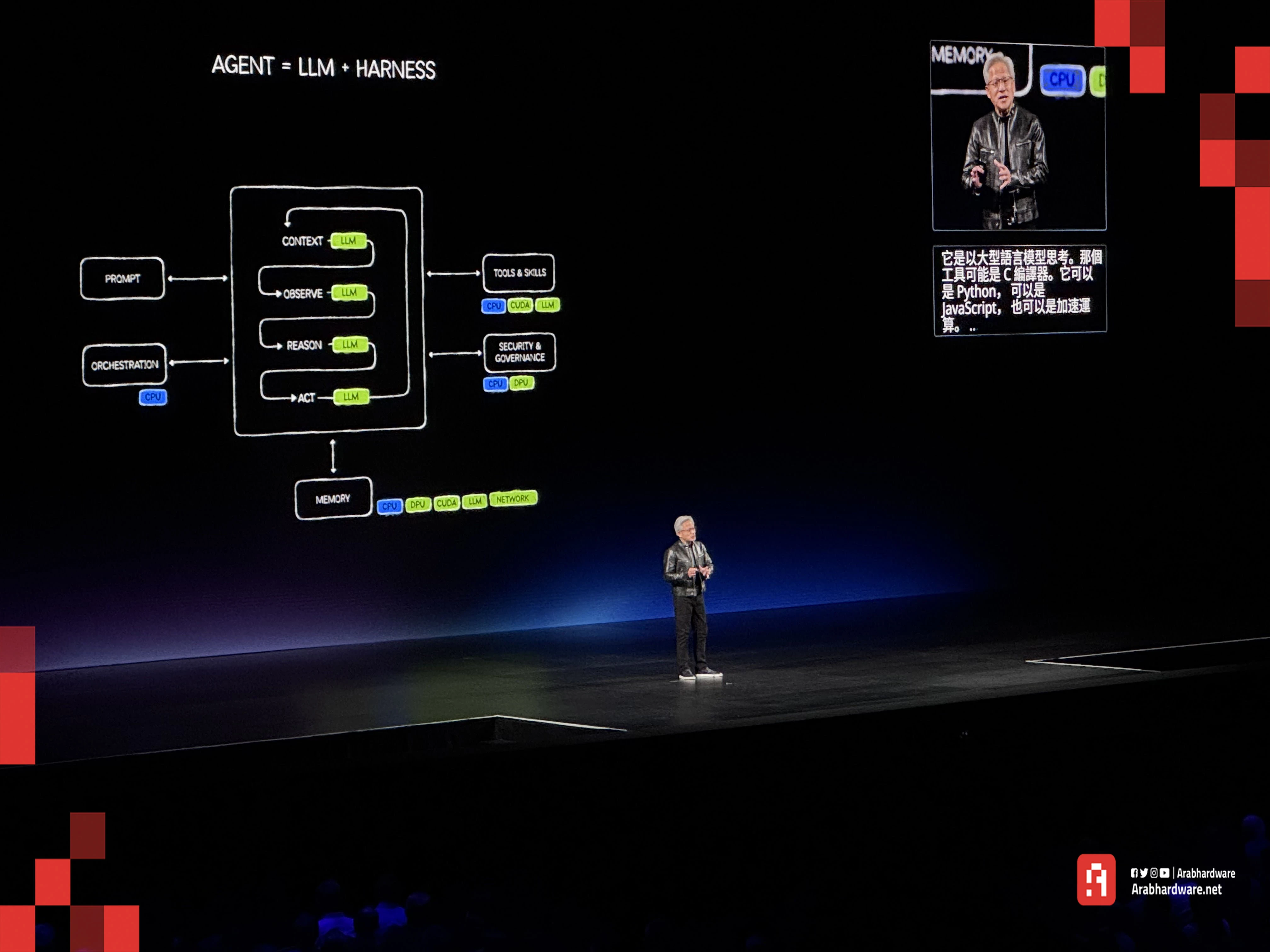 لإدراك حجم هذه النقلة، يجب أولًا فهم الفرق بين الأنظمة التفاعلية التقليدية والأنظمة المستقلة ذاتية التوجيه. فالذكاء الاصطناعي التقليدي، مثل ChatGPT أو Gemini، يعتمد في الأساس على الاستجابة للمدخلات التي يتلقاها من المستخدم، إذ يولّد مخرجاته بناءً على الطلب الحالي وسياق المحادثة.
لإدراك حجم هذه النقلة، يجب أولًا فهم الفرق بين الأنظمة التفاعلية التقليدية والأنظمة المستقلة ذاتية التوجيه. فالذكاء الاصطناعي التقليدي، مثل ChatGPT أو Gemini، يعتمد في الأساس على الاستجابة للمدخلات التي يتلقاها من المستخدم، إذ يولّد مخرجاته بناءً على الطلب الحالي وسياق المحادثة.
وفي كثير من الحالات، يحتاج هذا النوع من الأنظمة إلى تدخل المستخدم باستمرار لتوجيهه وتصحيح مساره. فعلى سبيل المثال، إذا اقترح كودًا برمجيًا يحتوي على خطأ، فإن اكتشاف الخطأ ومعاودة المحاولة يعتمد غالبًا على قيام المستخدم باختبار الكود وإعادة تزويده بالملاحظات أو رسائل الخطأ.
أما الذكاء الاصطناعي الوكيل (Agentic AI)، فينقل الذكاء الاصطناعي من دور المساعد الذي ينتظر التعليمات إلى دور المنفذ القادر على إدارة سلسلة من المهام لتحقيق هدف محدد. ويعتمد ذلك على حلقات مستمرة من التخطيط، وتقييم النتائج، ومراجعة الأداء، والاستفادة من الأدوات والخدمات الخارجية عند الحاجة، مما يمنحه قدرًا أكبر من الاستقلالية مقارنة بالأنظمة التفاعلية التقليدية.
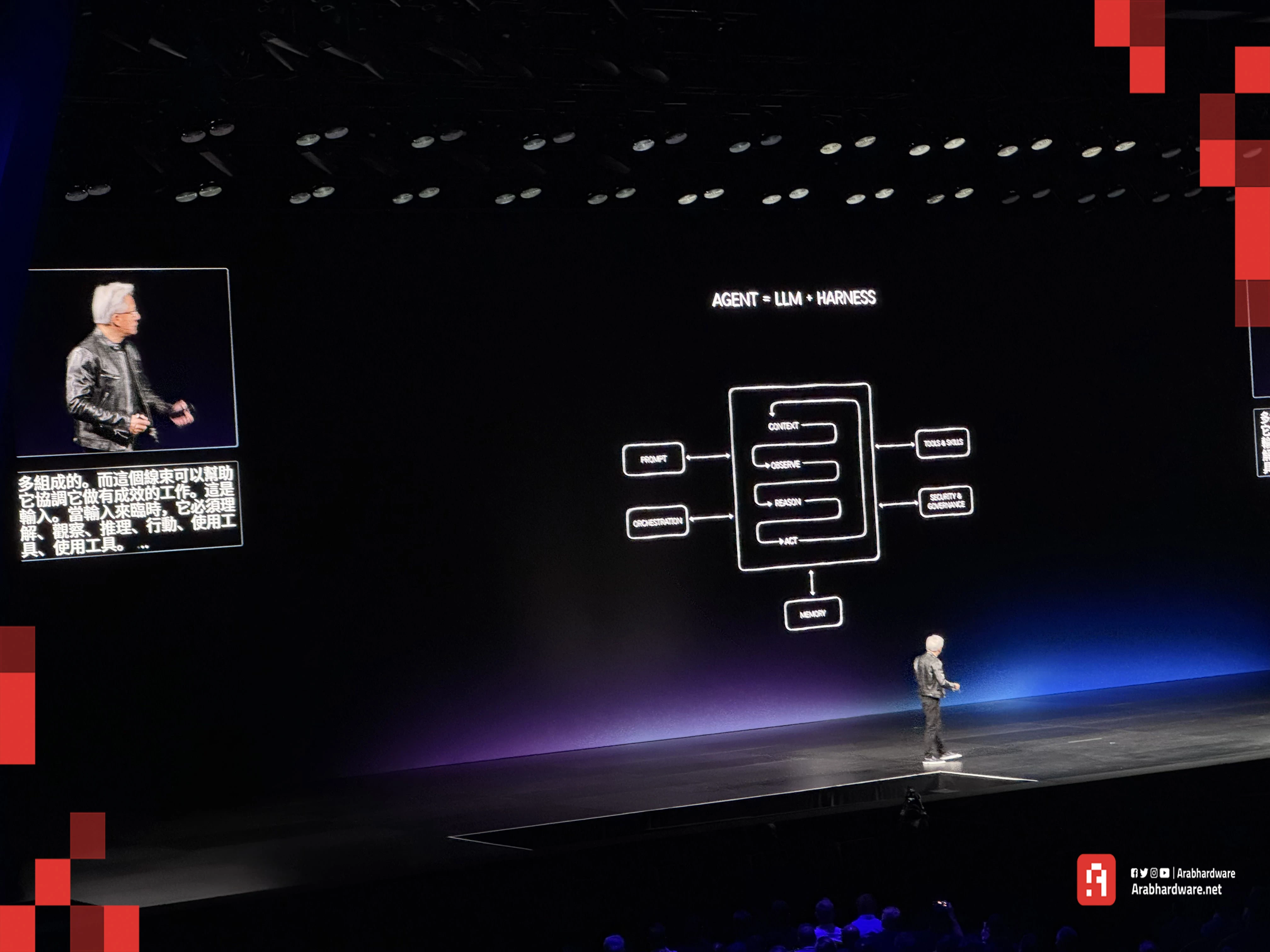
كيف يعمل عمليًا؟ عند إعطائه هدفًا عامًا، يشغل الوكيل نموذج التفكير لتفكيك الهدف إلى شجرة مهام. بعد ذلك، يُنشئ وكلاء فرعيين على سبيل المثال: وكيل يكتب الكود، ووكيل يختبر الكود في بيئة معزولة، ووكيل يراجع التصميم البصري. إذا فشل الاختبار، يعيد الكود تلقائيًا للتعديل دون إزعاج المستخدم البشري، ولا يعود إليك إلا بالمنتج النهائي الجاهز.
وكشف هوانغ أيضًا، أن NVIDIA تعمل على بناء الأدوات والنظام البيئي المخصص للوكلاء الرقميين منذ أكثر من عقد من الزمان، والآن دُمجت كل شيء بدءًا من النماذج ووصولًا إلى الأدوات في حزمة متكاملة تُدعى حزمة أدوات وكلاء NVIDIA ضمن مشروع OpenShell. الهدف من ذلك تمكين المطورين والشركات حول العالم من بناء وكلاء رقميين مخصصين، يملكون القدرة على الوصول إلى الأدوات والملفات وحل المشكلات المعقدة بصورة مستقلة.
بالعمل مع NVIDIA، ستدخل شركة Cadence، العملاق العالمي الأول في مجال برمجيات أتمتة التصميم الإلكتروني، الوكلاء الخارقين لتصميم الشرائح في فريق عملها، إذ يستطيع الوكيل الرقمي محاكاة وتجربة ملايين الاحتمالات الهندسية لمسارات السيليكون في الوقت نفسه، واختيار التصميم الأكثر كفاءة واستهلاكًا للطاقة واختصار الوقت الإجمالي للتصميم من أسابيع طويلة إلى ساعات معدودة.
معمارية الفئة العليا Vera Rubin ومنظومة NVL72

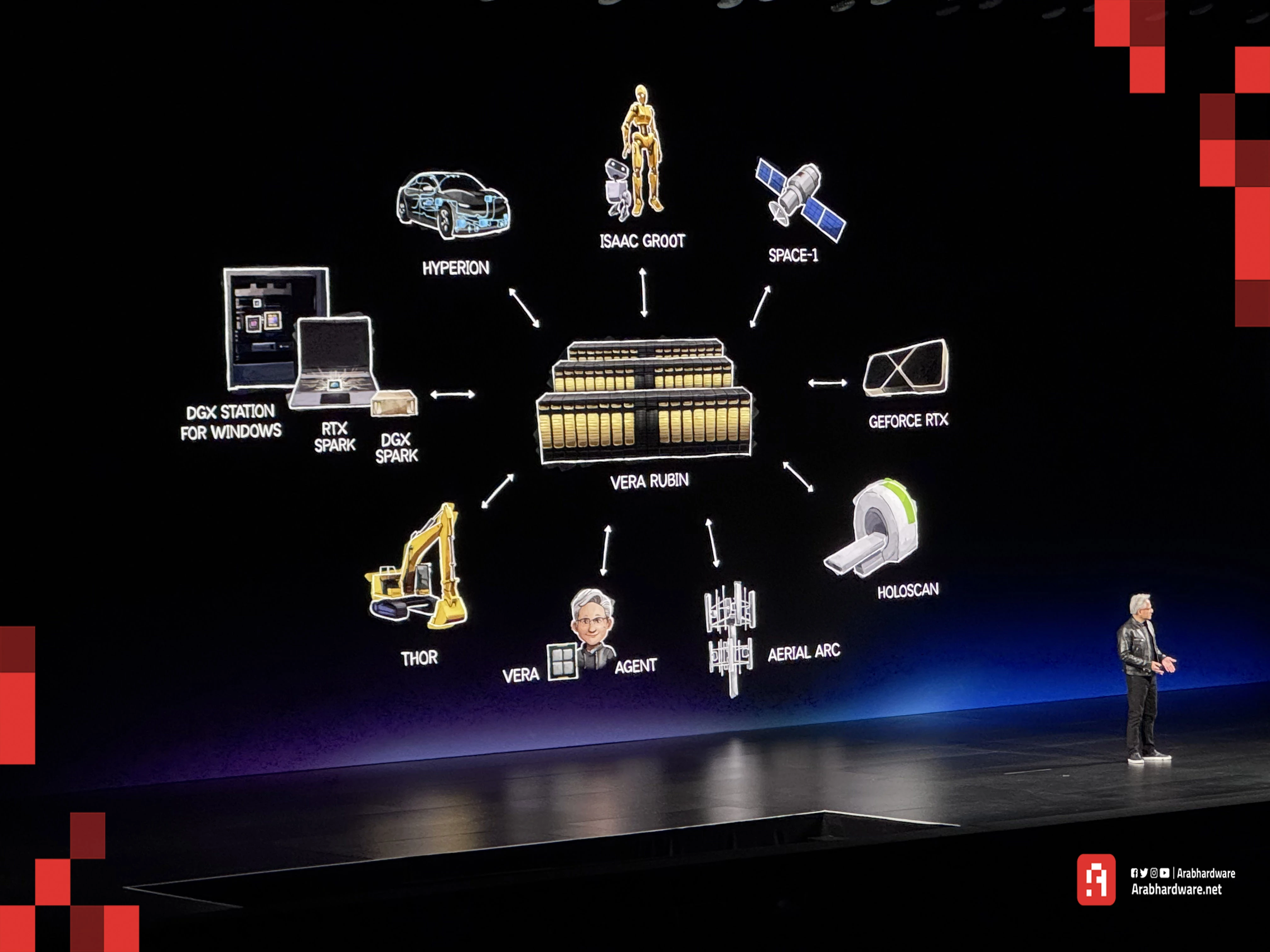
بعد الطفرة الهائلة التي حققتها معمارية Blackwell، تأتي معمارية Vera Rubin لتنقل مراكز البيانات إلى مستوى حوسبة يكسر الحدود الفيزيائية الحالية فهي تمثل منصة الجيل القادم الخارقة لتشغيل نماذج الذكاء الاصطناعي العملاقة. سُميت المعمارية تيمنًا بعالمة الفلك الأمريكية الشهيرة فيرا روبين التي ساهمت في إثبات وجود المادة المظلمة.
قدم "هوانغ" لنا معمارية Vera Rubin NVL72 مؤكدًا دخولنا لعصر جديد من الحوسبة فائقة التكامل. لا تمثل الأرقام والمكونات المذكورة مجرد ترقية عادية، بل هي إعادة تعريف شاملة لكيفية بناء الحواسيب الفائقة.
تتميز أنظمة NVIDIA Vera Rubin NVL72 باحتوائها على المعالج المركزي الجديد NVIDIA Vera، والمسرّع NVIDIA Groq 3 LPX، ووحدات التخزين NVIDIA Vera BlueField-4 STX، بالإضافة إلى رفوف شبكات الإيثرنت NVIDIA Spectrum-6 SPX، حيث تتكامل كل هذه المكونات معًا داخل نظام واحد موحد.

ويضم اللوح الإلكتروني الواحد أكثر من 18 ألف مكون، بينما يحتوي الرف الواحد (Rack) على أكثر من مليون مكون تقني! إنه حقًا إنجاز هندسي مذهل يفوّق الوصف. بعرض نطاق ترددي يصل إلى 40 بيتابايت، فإن منصة Vera Rubin تمثل مستوى آخر تمامًا من القوة التقنية.
ماذا يعني غياب الكابلات؟ في مراكز البيانات التقليدية تُربط الرفوف والخوادم ببعضها عبر غابات متشابكة من كابلات النحاس أو الألياف الضوئية، هذه الكابلات تسبب معضلتين: الأولى حرارية حيث تعيق تدفق الهواء للتبريد، والثانية فيزيائية حيث تفقد الإشارات الرقمية جزءًا من قوتها وسرعتها أثناء انتقالها عبر السلك، مما يسبب مشكلة في زمن الاستجابة.
ماذا كان الحل الهندسي؟ كشف هوانغ أن منظومة Vera Rubin NVL72 تخلصت من الكابلات تمامًا داخل أدراج الحوسبة، حيث أصبحت المعالجات الرسومية والمركزية موضوعة مباشرة على لوحات مطبوعة تتصل بلوحة خلفية ضخمة وموحدة مدمجة في هيكل واحد. تتصل تلك القطع عبر كتل نحاسية صلبة وممرات هندسية متطورة للغاية تتيح لـ 72 معالجًا رسوميًا العمل وكأنها رقاقة واحدة عملاقة مشتركة الذاكرة، مما يرفع النطاق الترددي لتبادل البيانات إلى مستويات مذهلة خالية من أي هدر أو تأخير.
تخلص التصميم الجديد مع Vera Rubin من المراوح الميكانيكية المزعجة والمستهلكة للطاقة، واستبدل نظام خراطيم التبريد السائل التقليدية بقنوات تبريد مدمجة ومباشرة. كما استبدل آلاف كابلات بلوحة دوائر مطبوعة عملاقة ومركبة في المنتصف تُعرف تقنيًا بـ Backplane أو Midplane.
تُعد منصة Vera Rubin المشروع الأكثر طموحًا في تاريخ شركة NVIDIA كما يقول هوانغ، فلقد شارك في العمل عليها جميع المهندسين لتقديم النظام الأكثر تعقيدًا على الإطلاق في تاريخ التصميم الهندسي. يصفها هوانغ بأنها النظام الأكثر تعقيدًا؛ لأن تصميمها لم يعد يقتصر على رقاقة سيليكون صغيرة، بل يمتد لتصميم رفوف خوادم (Racks) ومراكز بيانات كاملة متصلة ببعضها عبر شبكات فائقة السرعة تتصرف وكأنها رقاقة واحدة عملاقة.
معالجات Vera المركزية...الخطوة المنتظرة منذ زمن!

كشف Jensen Huang عن المعالج المركزي الجديد NVIDIA Vera، والذي صُمم خصيصًا لدعم تطبيقات الذكاء الاصطناعي الوكيل، مؤكدًا أنه يمثل إحدى أكثر منصات المعالجة المركزية تقدمًا التي طورتها الشركة حتى الآن. ومع هذا الإعلان، تؤكد NVIDIA مجددًا طموحها في توسيع حضورها داخل سوق المعالجات المركزية، إلى جانب مكانتها الراسخة في قطاع المعالجات الرسومية.
وتعكس هذه الخطوة فلسفة NVIDIA الهندسية في تقديم بدائل قادرة على منافسة معالجات x86 التي تطورها كل من Intel وAMD. وهنا يبرز مصطلح Chiplet Tax أو «ضريبة الشرائح المصغرة»، وهو تعبير غير رسمي يُستخدم في الأوساط التقنية للإشارة إلى التكلفة أو التأخير الإضافي الناتج عن اعتماد تصميم الشرائح المتعددة.
فبدلًا من تصنيع المعالج على هيئة قطعة سيليكون واحدة ضخمة، تعتمد شركات مثل AMD وIntel على تقسيمه إلى عدة شرائح أصغر (Chiplets)، مثل وضع أنوية المعالجة في شريحة منفصلة ووحدة التحكم بالذاكرة في شريحة أخرى، ثم ربطها معًا داخل الحزمة نفسها. ويمنح هذا الأسلوب مزايا كبيرة من حيث خفض تكاليف التصنيع وتحسين معدلات الإنتاج.
لكن في المقابل، عندما تنتقل البيانات بين هذه الشرائح المختلفة، فإنها تحتاج إلى المرور عبر وصلات اتصال داخلية، وهو ما يضيف قدرًا من زمن الاستجابة مقارنة بالتصميمات الأحادية. وهذا التأخير المحدود هو ما يُشار إليه اصطلاحًا باسم Chiplet Tax، رغم أن تأثيره الفعلي يختلف باختلاف التصميم ونوع أعباء العمل التي ينفذها المعالج.

رفضت NVIDIA هذا التصميم في معالج Vera وعادت إلى تصميم القالب الموحد الذي يعرف بـ Monolithic Design. هذا المفهوم يعتمد على تصميم المعالج بالكامل كقطعة سيليكون واحدة حتى أقصى حدودها الهندسية التي تسمح بها آلات الطباعة الضوئية بالأشعة فوق البنفسجية الفائقة.
ما هي الفائدة من هذا التصميم؟ غياب خطوط الفصل الداخلية مما يعني أن جميع الأنوية، وممرات الذاكرة المخبأة، وممرات نقل البيانات تعمل بتناغم فوري وسرعة قصوى. النتيجة هي تحقيق أعلى معدل IPC، وهي تعني عدد العمليات أو التعليمات البرمجية التي يستطيع المعالج تنفيذها في دورة الساعة الواحدة، في العالم مع زمن استجابة شبه منعدم.
هذا المفهوم مهم وجوهري لأن الوكلاء الرقميين يحتاجون لاتخاذ مئات القرارات المنطقية المتتالية فورًا، وأي تأخير في المعالج المركزي سيعطل المنظومة بأكملها.
كما تطرق هوانغ لحديث مهم عن الوكلاء الرقميين، فهؤلاء يفكرون بالنانوثانية - وهي جزء من مليار جزء من الثانية - ما يعني الحاجة إلى السرعة الفائقة لتتخذ بها الخوارزميات قراراتها. إذا طلب المستخدم من الوكيل تنفيذ مهمة مالية معقدة فإن الوكيل قد يقوم بآلاف العمليات المنطقية والتأكد من البيانات في جزء من الثانية.
ومن المثير للاهتمام من الناحية التقنية أن نرى NVIDIA تعتمد على ذواكر LPDDR5X، وهي فئة تُستخدم عادةً في الأجهزة ذات الكفاءة العالية في استهلاك الطاقة مثل الهواتف الذكية والحواسيب المحمولة الخفيفة وأجهزة الألعاب المحمولة، داخل منصة موجهة لمراكز البيانات. ويعود ذلك إلى إمكانية دمج هذه الذواكر بالقرب من المعالج، ما يسمح بتقليل مسافات الاتصال ورفع عرض النطاق الترددي إلى مستويات هائلة تصل إلى 1.2 تيرابايت في الثانية، وهو رقم يتجاوز بفارق كبير ما توفره ذواكر DDR5 التقليدية في الحواسيب المكتبية.
ولا يتوقف الأمر عند هذا الحد، إذ يعتمد معالج Vera Rubin أيضًا على واجهة PCIe Gen6، التي توفر سعات نقل بيانات ضخمة تصل إلى 1.4 تيرابايت في الثانية. وتساعد هذه السرعات على تسريع تدفق البيانات بين المعالج والذاكرة ووحدات التخزين والمعالجات الرسومية، بما يقلل احتمالية ظهور اختناقات في أعباء العمل الضخمة المرتبطة بالذكاء الاصطناعي والحوسبة عالية الأداء.
ومع الوصول إلى هذه المستويات المرتفعة من الأداء، يصبح زمن الاستجابة عاملًا بالغ الأهمية. ففي الأنظمة العملاقة المخصصة للذكاء الاصطناعي، قد يؤدي أي تأخير بسيط في انتقال البيانات بين الذاكرة ووحدات المعالجة إلى الحد من الاستفادة الكاملة من الموارد المتاحة. ولهذا صُممت منصة Vera مع التركيز على تقليل زمن الوصول إلى أدنى مستوى ممكن، لضمان الاستفادة القصوى من قدراتها الحاسوبية.
منصة مصانع الذكاء الاصطناعي NVIDIA DSX

عندما يقفز استهلاك طاقة مراكز البيانات من بضعة ميجاوات إلى 1 جيجاوات - وهي طاقة كافية لإنارة مدينة كاملة - فإن إدارة هذه الطاقة لا يمكن أن تتم عبر برمجيات عادية. هنا يأتي دور منصة NVIDIA DSX التي تعمل بمثابة نظام تشغيل وتحكم ذكي للمصنع.
ماهو دور تقنية DSX MaxLPS؟ في مصانع الذكاء الاصطناعي يتبدل سحب الطاقة بين جزء من الثانية والآخر بناءً على طبيعة المعالجة التي تحدث في اللحظة نفسها مثل عمليات التدريب التي تستهلك طاقة قصوى، بينما عمليات الاستدلال قد تستهلك أقل.
تعمل تقنية MaxLPS كمنظم طاقة ديناميكي جبار حيث تراقب العتاد وتوزع الجهد والتيار بدقة ميكروية لتضمن تشغيل أكبر عدد ممكن من الخوادم بأقصى كفاءة دون أن يتخطى مركز البيانات السقف الحراري والكهربائي المستهدف، مما يمنع حدوث قفزات تيار مفاجئة تؤدي لتلف المكونات.
ماذا عن تقنية DSX Flex؟ هذه التقنية تمثل وعيًا بيئيًا واقتصاديًا متقدمًا حيث ترتبط المنصة برمجيًا مع مزودي شبكات الكهرباء المحلية. إذا تعرضت المدينة لضغط أحمال أو نقص في توليد الطاقة مثل فترات الصيف الحارة، يقوم نظام DSX Flex تلقائياً وبشكل مرن بـتقليص استهلاك مركز البيانات للطاقة عبر خفض ترددات العتاد أو تأجيل مهام التدريب الثانوية، وموازنة العمل ليتماشى مع المتاح من الشبكة دون أن يتسبب في انقطاع الكهرباء عن المصنع أو المدينة.
ثورة الحوسبة الشخصية: مشروع RTX Spark
هذا الإعلان المشترك بين NVIDIA ومايكروسوفت يمثل الزلزال الأكبر في تاريخ الحواسيب الشخصية منذ عقود، فهو لا يمثل مجرد إطلاق معالج جديد بل هو إعلان رسمي عن ولادة منصة حوسبة برؤية هندسية مغايرة تمامًا تقودنا إلى عصر جديد.
لأول مرة، نرى هذا الاتحاد الاستراتيجي لكسر هيمنة تحالف (Intel و AMD)، فشركة NVIDIA ستقدم المعمارية الرسومية الأقوى في العالم Blackwell وخبرتها في الذكاء الاصطناعي. وستقدم مايكروسوفت الدعم البرمجي الكامل عبر نظام Windows on Arm، لضمان تشغيل الألعاب والبرامج بسلاسة مطلقة ومن دون مشكلات توافقية.
سنخبركم بكل ما نعرفه، فلقد جمعت NVIDIA بين قوتها الخارقة في تصميم المعالجات المركزية وحزم برمجيات الذكاء الاصطناعي، وبين خبرة شركة MediaTek العريقة في تصميم معالجات الهواتف والرقاقات المدمجة عالية الكفاءة المستندة إلى معمارية Arm.
النتيجة هي مواصفات استثنائية لشريحة NVIDIA N1X، إذ نجح مهندسو NVIDIA في دمج 20 نواة معالجة مركزية مع 6144 نواة CUDA رسومية ضمن شريحة واحدة مصنعة بدقة 3 نانومتر وموجهة للحواسيب المحمولة. ويُعد هذا المستوى من التكامل لافتًا للغاية بالنسبة إلى معالج مدمج، إذ يضعه نظريًا في فئة أداء تقترب من بعض البطاقات الرسومية المنفصلة المخصصة للحواسيب المحمولة، مثل NVIDIA GeForce RTX 5070 Laptop GPU.
وإذا انعكست هذه المواصفات على الأداء الفعلي كما هو متوقع، فقد نشهد جيلًا جديدًا من الحواسيب المحمولة يجمع بين التصميمات النحيفة والخفيفة وكفاءة الطاقة المرتفعة، مع تقديم مستوى أداء ينافس أجهزة الألعاب الأكبر حجمًا. كما توفر هذه المواصفات قدرة كبيرة على معالجة تطبيقات الذكاء الاصطناعي محليًا، وهو ما قد يمنحها أفضلية واضحة مقارنة بالحد الأدنى من المتطلبات الحالية لأجهزة Copilot+ PC.

كما ستدعم هذه المنصة ذاكرة موحدة بسعة تصل إلى 128 جيجابايت، إلى جانب تقنية ربط بيني عالية السرعة تتيح للمعالج المركزي والمعالج الرسومي مشاركة البيانات بكفاءة كبيرة. ووفقًا لما أعلنته NVIDIA، يمكن أن توفر هذه المنظومة قدرة معالجة للذكاء الاصطناعي تصل إلى 1 بيتافلوب، وهو مستوى من الأداء كان حكرًا على الحواسيب الخارقة قبل سنوات قليلة، قبل أن يبدأ بالوصول إلى أجهزة أصغر حجمًا.
ومن الناحية العملية، تعتمد العديد من أدوات الذكاء الاصطناعي الحالية على المعالجة السحابية، حيث تُرسل البيانات إلى خوادم بعيدة قبل إعادة النتائج إلى المستخدم. أما مشروع RTX Spark فيهدف إلى نقل جزء كبير من هذه القدرات إلى الجهاز نفسه، مما يتيح تشغيل نماذج لغوية متقدمة وتطبيقات ذكاء اصطناعي محلية دون الاعتماد الكامل على الاتصال الدائم بالإنترنت، مع الاستفادة من مزايا الخصوصية وتقليل زمن الاستجابة.
ولا يقتصر الأمر على تطبيقات الذكاء الاصطناعي فقط، إذ تهدف المنصة أيضًا إلى تقديم أداء قوي في التطبيقات الاحترافية والألعاب مع الحفاظ على كفاءة مرتفعة في استهلاك الطاقة، وهو ما قد ينعكس إيجابًا على عمر البطارية في الحواسيب المحمولة.
وكشف Jensen Huang كذلك أن العمل جارٍ على تحسين توافق تطبيقات احترافية مثل Adobe Premiere Pro وAdobe Photoshop مع حواسيب RTX Spark العاملة بنظام ويندوز، مع التركيز على الاستفادة من قدرات الذكاء الاصطناعي والوكلاء الرقميين لتسريع سير العمل الإبداعي وزيادة الإنتاجية.

بفضل دعم الوكلاء الرقميين لن يقتصر دور الذكاء الاصطناعي على توليد صورة أو مسح عنصر بل ستمنح الوكيل أمرًا معقدًا مثل: راجع هذا المقطع المصور مدته ساعة واقترح لي أفضل اللقطات الحماسية وقصها على إيقاع الموسيقى، وصحح الألوان تلقائيًا. سيتولى الوكيل فتح الأدوات والجدول الزمني وتطبيق التعديلات في ثوانٍ مستغلاً قوة 1 بيتافلوب للرقاقة في حاسوبك المحمول
حتى عالم الحواسيب الصغيرة (Mini PC) سيتغير، فلقد رأينا أولى الحواسيب الصغيرة من MSI تعمل برقاقة RTX Spark مما يمثل تهديدًا مباشرًا لأجهزة الحواسيب الصغيرة الاحترافية في السوق. هذه الأجهزة التي كشف عنها هوانغ ستقدم أداء يضاهي الحواسيب المكتبية الضخمة بحجم صندوق صغير جدًا، وبكفاءة طاقة مذهلة بفضل معمارية ARM مما يجعلها الخيار المثالي للمكاتب المنزلية ومحطات العمل التي لا تتحمل ضوضاء المراوح أو استهلاك الطاقة المرعب.
منصة الروبوتات Cosmos 3 و Isaac GROOT

الخطوة الأخيرة في رؤية NVIDIA هي نقل الذكاء الاصطناعي من العالم الرقمي وتجسيده في العالم المادي، فالذكاء الاصطناعي التقليدي أعمى عن قوانين الطبيعة التي نعرفها، فهو لا يعرف أن الكوب إذا سقط سيتكسر، أو أن السير على سطح زلق يتطلب تقليل السرعة.
منصة Cosmos 3 هي نموذج تأسيسي متطور تدرب على مئات الآلاف من ساعات المحاكاة الفيزيائية والفيديوهات الحقيقية ليصبح قادرًا على فهم وتوقع القوانين الفيزيائية للعالم. عندما تقود سيارة ذاتية القيادة مدعومة بهذا النموذج، فإنها لا تتبع الخطوط على الطريق فقط، بل تستنتج وتفكر في سلوك المشاة وتتوقع حركة الأجسام المحيطة بها بناءً على فهمها الفيزيائي للواقع.
تضع NVIDIA المخطط الأساسي لصناعة الروبوتات البشرية، مثل روبوت Isaac GR00T. ويجمع هذا الروبوت المرجعي بين أحدث ما توصلت إليه الهندسة الحركية، من مفاصل وأيدٍ فائقة المرونة طورتها شركة Unitree والقادرة على الإمساك بالأجسام الدقيقة بحرفية عالية، وبين العقل الحاسوبي المتمثل في شريحة Jetson Thor.
هذا المعالج الصغير والخارق مصمم خصيصًا ليدمج بيانات الحساسات مثل معالجة الكاميرات، وحساسات اللمس، والرادارات في الوقت نفسه وتغذية نموذج الذكاء الاصطناعي بها لحظيًا، ليتحرك الروبوت ويتعلم ويتفاعل مع البشر بيسر وأمان.
حينما يمتزج العتاد الخارق بالذكاء المستقل

لم تكن هذه مجرد إعلانات تقنية اعتيادية من العملاق الأخضر NVIDIA، بل كانت إعلان ملامح الثورة الصناعية القادمة التي تقودها NVIDIA بكفاءة منقطعة النظير. إن الانتقال من الذكاء الاصطناعي التفاعلي إلى الذكاء الاصطناعي الوكيل فرض إعادة هندسة شاملة لكل شيء.
فالهيكلية الجديدة أدت إلى التخلص الشركة من الكابلات في الرفوف الخاصة بالخوادم، وكسرت مفهوم الرقاقات مع معالجات Vera، وقدمت حلول طاقة ذكية لأضخم مصانع البيانات في العالم.
ولم يتوقف الطموح عند الخدمات السحابية المتطورة، بل هبطت هذه القوة الخارقة إلى غرف منازلنا عبر منصة RTX Spark لتمنح حواسبنا الشخصية عقولًا مستقلة وآمنة، وصولًا إلى منح الروبوتات والسيارات وعيًا فيزيائيًا حقيقيًا عبر Cosmos 3. باختصار، تضع NVIDIA اليوم حجر الأساس لعالم لن نكون فيه نحن البشر المستخدمين الوحيدين للتكنولوجيا، بل سنعيش ونعمل جنبًا إلى جنب مع ملايين الوكلاء الأذكياء والروبوتات المستقلة بفضل سيليكون أخضر لا يرحم المنافسين.





