
الربط بين المعالج المركزي والرسومي: كيف تخطط AMD لمستقبلها؟
شركة AMD هي الشركة الوحيدة التي تقوم بتصنيع معالجات x86 المركزية والمعالجات الرسومية أيضاً حتى يتم إصدار معالجات Intel Xe. هذا الأمر أعطى العملاق الأحمر فرصة كبيرة لإستغلال هذا الأمر في تقنيات التوصيلات الخاصة بها والتي نفعت مستخدميها في نواحي الحوسبة عالية الأداء كما نرى في مؤتمر Rice Oil and Gas HPC الذي تم عقده في الأمس.
أعلنت AMD في عام 2018 في حدث Next Horizon عن نيتها في مد تقنيات الـ Infinity Fabric بين معالجات MI60 Radeon Instinct الرسومية لكي تربط بينهم بسرعة 100 جيجابت في الثانية مثل NVLink. لكن مع الإعلان عن جهاز Frontier الخارق في الشهر الماضي، وضحت AMD أنها ستقوم بإستخدام تصويلاتها بين المعالجات المركزية والمعالجات الرسومية.
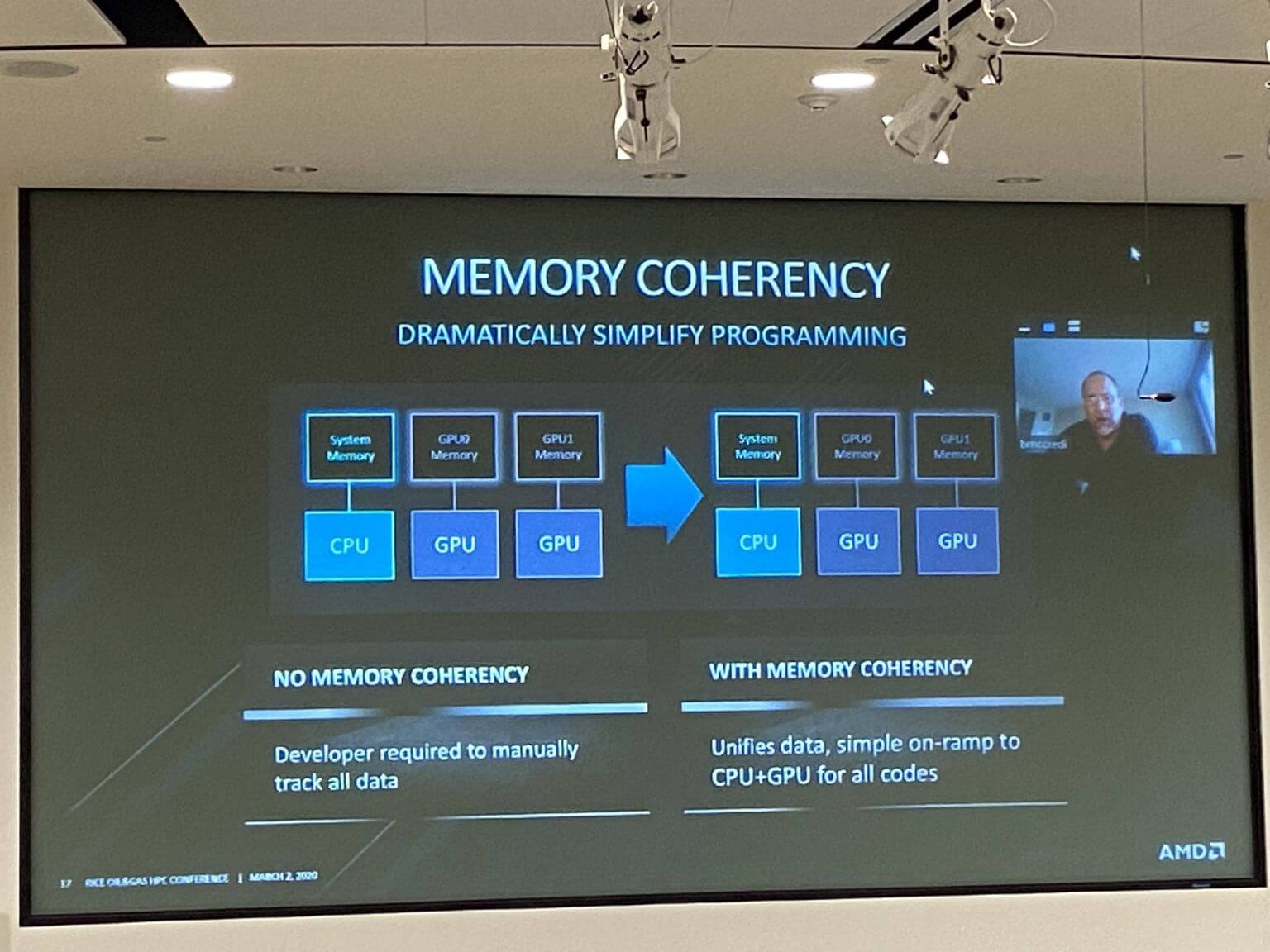
مؤتمر Rice Oil and Gas HPC لم ينتهي بعد، لكن على حسب تغريدة من محلل Intersect 360 -السيد " Addison Snell"- ليلة أمس، أعلنت AMD أن الأجيال القادمة من Epyc و Radeon ستأتي بتوصيلات بين الذواكر العادية والمخفية بين المعالج الرسومي والمعالج المركزي من خلال بساطها السحري وهو Infinity Fabric.
https://twitter.com/HatemLtaief/status/1234572914432839687
بالطبع كعادتنا في عرب هاردوير، نحتاج دائماً إلى شيء ملموس. في هذه الحالة نرى تغريدة من السيد "حاتم لطيف" وهو أحد العلماء الكبار في "Extreme Computing Research Center" لكي نستعرض بعض المعلومات من خلال هذه التغريدة في الأعلى.
من الواضح في تقارير AMD أنها تريد أن تقوم بالفصل بين فعالية الطاقة الخاصة بالمعالجات المختلفة ومعالجات الـ x86 بأنويتها من خلال الحديث عن معدلات الأداء التي يتم قياسها بوحدات الـ FLOPS من خلال المقارنة بين الطاقة المستهلكة مع المساحة المستخدمة من السليكون للوصول إلى هذا الأداء.
من الأرشيف: العصر الذهبي لـ AMD: إصدار أقوي معالج مكتبي في التاريخ بـ64 نواة!
قد يبدو الأمر تقنياً لأبعد حد، لكن تبسيطه ليس بالصعب. الفكرة كلها تكمن في أن المعالجات المركزية متأخرة في هذا الأمر. لكن إستخدام أكواد معتمدة على الـ Vectors من خلال خطوط الـ SIMD تستطيع أن تقوم بتحسين الأداء في الناحيتين. لكن سيظل الأمر واضحاً في المعالجات الرسومية التي تعتبر الأفضل في نفس الناحيتين سواء كانت المساحة المستهلكة من السليكون أو الطاقة.
أين تقع مجهودات AMD في هذه الناحية؟
الرفع من التوصيلات الخاصة بالمعالجات وما يشابهها من وحدات معالجة مثلما تفعل الشركة مع المعالجات ذات الرسوميات المدمجة يسمح للناحيتين بالتلاقي في نقطة ما. هذا الأمر يساهم في توحيد البيانات الخاصة بالرسوميات والأوامر النابعة من خلال الشريحتين.
قامت AMD أيضاً بعرض بعض الأكواد التي يجب إستخدامها من أجل العمل على معالج رسومي بدون ذواكر موحدة لكي توضح وجهة نظرها في أن معماريات الذاكرة الموحدة تساهم كثيراً في التخلص من الأكواد التي سيكون المطورين في غنى عنها في المستقبل.
يظهر مجهود AMD في العمل على تبني معمارية HSA الشبيهة للغاية بإستخدام الـ Infinity Fabric للربط بين عالم الأوامر والرسوميات. تقوم هذه المعمارية بتزويد القطع المستخدمة للتوصيل بينها وبين الباقي بذاكرة إفتراضية مشتركة للقضاء على عملية نقل البيانات بين هذه القطع لتقليل الوقت الذي تأخذه لنقل البيانات والرفع من معدلات الأداء.
على سبيل المثال الذي سنشرحه على لعبة لتبسيطه. لنقول أن لعبة FIFA تقوم بالعمل على المعالج والبطاقة الرسومية بشكل مشترك وأنت تقوم الآن بالضغط على زرٍ ما من أجل نقل الكرة من لاعب للأخر. هذا الأمر يحتاج من المعالج القيام بمعالجة أمر التمرير ويحتاج المعالج الرسومي لكي يقوم بعرض التمريرة نفسها.
هناك تمريرة تحدث بين المعالج والبطاقة الرسومية، كيف؟ المعالج يقوم بتمرير البيانات التي قام بإنتاجها عند تمرير الكرة إلى ذاكرة المعالج الرسومي لكي يقوم بعرض التمريرة نفسها ثم إرجاعها إلى المعالج المركزي. هذا الأمر يتسبب في تأخير وصول البيانات ويتأخر بالأداء. لكن إن كانت هناك ذاكرة مشتركة بين المعالج الرسومي للدخول على نفس الذاكرة التي يستخدمها هذا المعالج، سيكون الأمر أفضل من نواحي الأداء وأسهل من نواحي البرمجة أيضاً.
الطاقة والمعالجة وجهان لعملة الأداء!
نقل البيانات قد يستهلك طاقة أكثر من الطاقة التي يتم إستهلاكها من أجل معالجة البيانات نفسها. لهذا الأمر سيكون تحسين الأداء والرفع من إستخدام الطاقة وكفاءتها أمر ملحوظ إن قام نظامٍ ما بالجمع بين ذواكر المعالجات المركزية والرسومية في مكانٍ واحد. ليس هذا فقط بل وسيعطي أيضاً مساحة أكبر لـ AMD لفرض نفسها على السوق بشكل واضح وصريح.
في نفس الوقت، Intel تعمل على معمارية Ponte Vecchio التي ستقوم بتشغيل جهاز Aurora الخارق في معمل Argonne الوطني الخاص بقسم الطاقة في الحكومة الأمريكية. تقوم عمليات Intel بالإعتماد على برمجيات OneAPI التي تقوم بالربط بين ذواكر المعالج المركزي والرسومي أيضاً تحت إسم Rambo Cache. سيكون من المثير أن نرى كيف سيكون أداء هذه التقنيات مقارنةً بتوصيلات الـ Infinity Fabric.




