
وعود بتحطيم المنافسين مع Zen 6/7: فما هي خطة AMD؟
تقود شركة AMD نقلة نوعية وغير مسبوقة في عالم المعالجات المكتبية والمحمولة إلى جانب معالجات APU، إذ تستعد للمرحلة المقبلة من تطوير معمارية Zen الثورية، التي غيرت قواعد اللعبة في عالم المعالجات المركزية بعد سيطرة شركة Intel عليها لمدة طويلة.
خلال فعالية يوم المحللين الماليين (Financial Analyst Day) لشركة AMD، وهو اجتماع سنوي تستضيفه الشركة لإطلاع المحللين والمستثمرين والمستشارين الماليين على آخر مستجدات الشركة وخططها المستقبلية التي ستعمل عليها خلال المرحلة المقبلة، كشفت الشركة عن خارطة الطريق التي تخطط للعمل عليها خلال عام 2026 و 2027 سواء للمعالجات المركزية أو للكروت الرسومية.
الخطة التي تعمل عليها AMD أزعجت بشدّة العملاق الأزرق Intel، لأن حجم صدى ما أعلنت عنه الشركة وصل لكل الوسائل الإعلامية المكتوبة والمسموعة والمرئية.
البداية كانت مع معمارية Zen 6 إلى جانب معمارية الجيل القادم Zen 7 وتشكيلة معالجات APU الحديثة، والجيل القادم من الكروت الرسومية RX XXXX، بالإضافة إلى مسرعات Instinct MI400. شخصيًا أنا سعيد بحجم هذا التنافس بين الشركات الكبرى، لأن القاعدة المشهورة تقول: عندما تكون المنافسة شرسة، يصبح العميل هو الفائز الأكبر، إذ تُجبرُ الشركات على تقديم أفضل المنتجات بأقل الأسعار.
لأول مرة AMD تعتمد على دقة تصنيع 2nm

الخطة تتحدث عن نفسها، فهي تشير بكل وضوح إلى الاعتماد في صناعة المعالجات المركزية على معمارية Zen 6 ولكن هذه المرة باستخدام دقة تصنيع أفضل وهي 2 نانومتر من مسابك العملاق التايواني TSMC. وهذا بدلًا من الاعتماد على دقة تصنيع 4 و 3 نانومتر التي استخدمت مع المعالجات المركزية المستندة على معمارية Zen 5.
وفقًا للمعلومات الرسمية، ستُطلق المعالجات المستندة على معمارية Zen 6 في عام 2026، إذ أشار مارك بيبرماستر المدير التقني لشركة AMD، إلى أن كلًا من المعالجات المركزية المستندة على معمارية Zen 6 و Zen 6c ستستفيدان من تحسينات في IPC -عدد التعليمات أو الأوامر خلال النبضة الواحدة للتردد- وهذا يعني تحقيق أداء أعلى. بالإضافة إلى مزايا متطورة أكثر للذكاء الاصطناعي من خلال مجموعات تعليمات موسعة ومسارات إضافية مخصصة للذكاء الاصطناعي، التي ستستهدف سلسلة معالجات Ryzen و EPYC من الجيل القادم.
ما يمكن أن نؤكده لك عزيزي القارئ أن معمارية Zen 6 ستنقسم إلى قسمين: التصميم القياسي للأنوية سيحمل المسمى نفسه Zen 6 وسيكون موجها لتحقيق أقصى أداء ممكن، في حين سيكون تصميم Zen 6C موجّهًا لتحقيق كفاءة أفضل في استهلاك الطاقة.
ماهي المعالجات المستهدفه مع معمارية Zen 6؟
كما ذكرنا قبل قليل، سيكون استخدام معمارية Zen 6 مع تشكيلة كبيرة من المعالجات المركزية. إذ يتوقع بداية أن تستهدف معالجات الخوادم EPYC بالاسم الرمزي Venice، بالإضافة إلى المعالجات المكتبية Ryzen القادمة بالإسم الرمزي Olympic Ridge، ومعالجات Ryzen Mobile بالاسم الرمزي Medusa Point المخصصة للحواسيب المحمولة.
من الواضح أن الهدف من وراء معمارية Zen 6 هو التوسع في استهداف عدد أكبر من خطوط إنتاج الشركة، لتستهدف الحواسيب المحمولة وصولًا إلى أنظمة مراكز البيانات. وقد أكدت الشركة بالفعل تحسينات على مستوى التعليمات الخاصة بالذكاء الاصطناعي وتحسّن في أداء العمليات الرياضية للمصفوفات، مما يساعد المعالجات على التعامل مع أعباء عمل التعلم الآلي بكفاءة كبرى دون الاعتماد على مسرّعات خارجية.
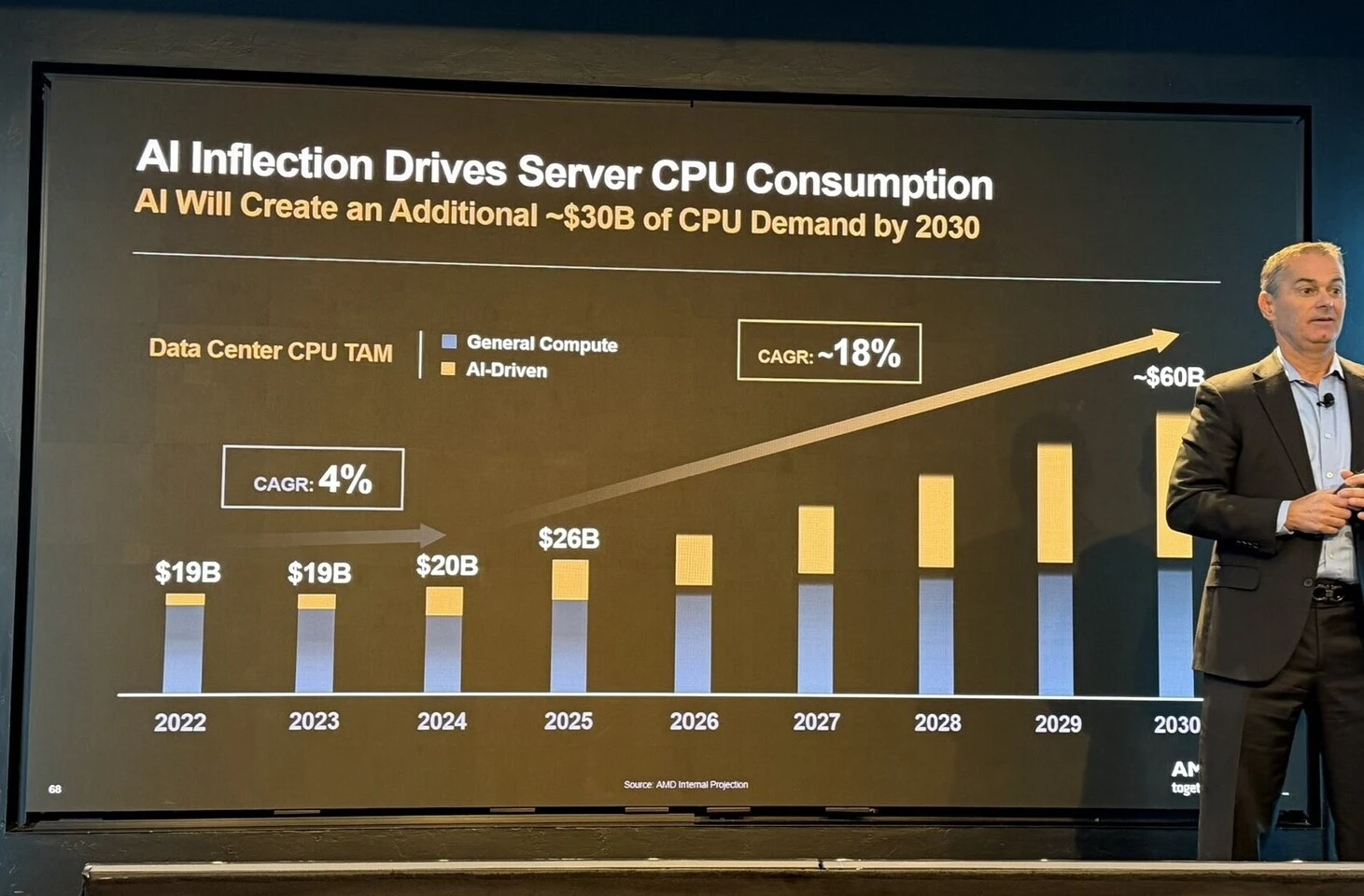
ستكون كفاءة الطاقة من الأمور الأبرز التي سيلاحظها المستخدم، وذلك بفضل الانتقال نحو دقة التصنيع الجديدة 2 نانومتر. ليس ذلك فحسب، بل ستشمل الفائدة حصولنا على تحسينات في نظام الذاكرة المخبأة وتصميم الوصلات البينية. إذ تتوقع AMD -وفقأ لتصريحها الرسمي- أداءً أفضل لكل واط في جميع سيناريوهات الإستخدام، من أجهزة الحاسوب المكتبية عالية الأداء إلى الخوادم السحابية ومراكز البيانات المتنوعة. في حين يُتوقع من أنوية Zen 6C -المُخصصة لتقديم كفاءة طاقة أفضل- دورًا كبيرًا في مراكز البيانات، إذ تكون الكثافة وقيود الطاقة أكثر أهمية من الحصول على ترددات مرتفعة.
معمارية Zen 7 ستعتمد على دقة تصنيع مختلفة!
ما يعجبني شركة AMD أنها تطبق مقولة: لا ننظر إلى الوراء لمعرفة من يلحق بنا، بل ننظر إلى الأمام لمعرفة كيف نبتعد عنهم أكثر. فمعمارية الجيل القادم ستحمل اسم Zen 7 ولا يُعرف حتى الآن متى ستكون جاهزة لترى النور. ربما في عام 2027، لكن ما نعلمه أنها ستعتمد على دقة تصنيع مستقبلية، وربما تدور الخيارات بين 1.5 نانومتر وواحد نانومتر. لكن المؤكد بلا شك أن العملاق التايواني TSMC سيعاني كثيرًا للوصول إلى دقة التصنيع هذه، فالقيود والصعوبات التقنية ستكون حاضرة بقوة في مراحل التصنيع.
الهدف الأبرز من هذه المعمارية -كما يبدو لنا- التركيز على جعل التكامل مثاليًا بين قدرات المعالجات المركزية ووحدات المعالجة العصبية المخصصة للذكاء الاصطناعي، إذ يمكن لأعباء العمل المستقبلية ومن خلال هذا التكامل الاستفادة بشكل أفضل من قوة المعالجة التسلسلية للمعالجات المركزية.

المعلومات الرسمية تشير إلى أن معمارية Zen 7 ستحصل على محرك مصفوفات جديد وستوسع نطاق التعامل مع تنسيقات بيانات الذكاء الاصطناعي بكفاءة هائلة، مما يمثل تحولًا نحو تكامل أعمق للذكاء الاصطناعي داخل أنوية المعالج القياسية وهذا أمر تسعى AMD لتحقيقه بكل ما تستطيع من قوة.
تجدر الإشارة إلى أن هناك تقنيتان رئيسيتان وهما تعليمات AVX10 و ACE التي ستكون متاحة في معمارية Zen 7. البداية مع AVX10 التي ستوحد تعليمات AVX-512 و AVX2 في وقت واحد لتحسين الأداء والتوافق عبر أعباء العمل التي تعتمد بكثافة على العمليات الرياضية للمتجهات وتعرف كذلك بـ Vector Math. أما ACE فهي تمثل مجموعة تعليمات رياضية قياسية يمكن أن تكون ذات صلة بكل جهاز بدءًا من الهواتف الذكية وصولاً إلى الخوادم.
من بين الإضافات الأخرى لمجموعة التعليمات في معمارية Zen 7، سيكون هناك اعتماد على ميزة FRED، كما يفترض أن تحصل معمارية Zen 7 على تقنية ChkTag x86 Memory Tagging لمواجهة عدة أنواع من الثغرات الأمنية على مستوى الذاكرة الناتجة عن تجاوز سعة المخزن المؤقت وأخطاء استخدام الذاكرة بعد تحريرها.
معالجات APU قد تحقق أداء رسومي يصل إلى كارت RTX 5070 Ti!
تُعد وحدة المعالجة المُسرّعة (اختصار لـ APU) تركيبة تجمع المعالج المركزي و المعالج الرسومي على رقاقة واحدة في قالب واحد. الهدف منها هو توفير رقاقة متكاملة قادرة على تشغيل كل شيء دون الحاجة إلى كارت رسومي منفصل. طريقة الدمج المُتبعة تعتمد بالدرجة الأولى على نجاح ما قامت به AMD في عام 2011 مع معالجات Fusion التي قدمت أُولى التجارب حول هكذا رقاقات قادرة على تشغيل المهام اليومية بشكل سلس وتشغيل الألعاب الخفيفة دون الحاجة لكارت رسومي منفصل.
هدفها الأساسي لم يكن استبدال الكارت الرسومي بل كان الاستنغاء عن المعالج الرسومي المدمج في داخل اللوحات الأم وهذا ما نجحت به فعلًا. لكن مع الوقت تغير هذا المفهوم ليصبح الآن مرتكزًا أكثر حول إمكانية الاستغناء عن شراء كارت رسومي من الفئة المنخفضة والمتوسطة.

التاريخ الذي واكبناه منذ عام 2011 لهذه المعالجات الفريدة من نوعها قد مرت بحالات خجولة للتطوير ووصلت لمرحلة أفضل مع الوقت لتصل اليوم لأفضل مراحلها على الإطلاق مع توقعات بأن تكون السنوات المقبلة لهذا النوع من المعالجات أكثر قوة مما سيخدم فئة كبيرة من اللاعبين على منصة الحاسوب، والأجهزة المحمولة وكذلك أجهزة الكونسول التي تعتمد على هكذا نوع من المعالجات المصممة بشكل رقاقات SoC، ليرتفع مستوى الكونسول نحو مرحلة لربما كنا نحلم بها.
الجيل الأول حمل إسم Llano من معمارية K10 المصنعة بدقة 32nm من GlobalFoundries. هذه المعالجات كانت الأولى من نوعها التي تحتوي معالجا مركزيا مع معالج رسومي مدمج في نفس القالب لتكون نقلة نوعية في تصميم رقاقات الحاسوب. ذلك الجيل الأول كان يعمل على لوحات أم بسوكيت FM1. وفي العام نفسه أُطلق الإصدار المحمول مع تشكيلة Desna، Ontario، Zacate التي أتت من معمارية Bobcat بدقة تصنيع 40nm من TSMC لتعمل على سوكيت FT1 المخصص للأجهزة المحمولة فائقة الرفع وذات الطاقة الاستهلاكية المنخفضة.
مرحلة متطورة في عالم معالجات APU
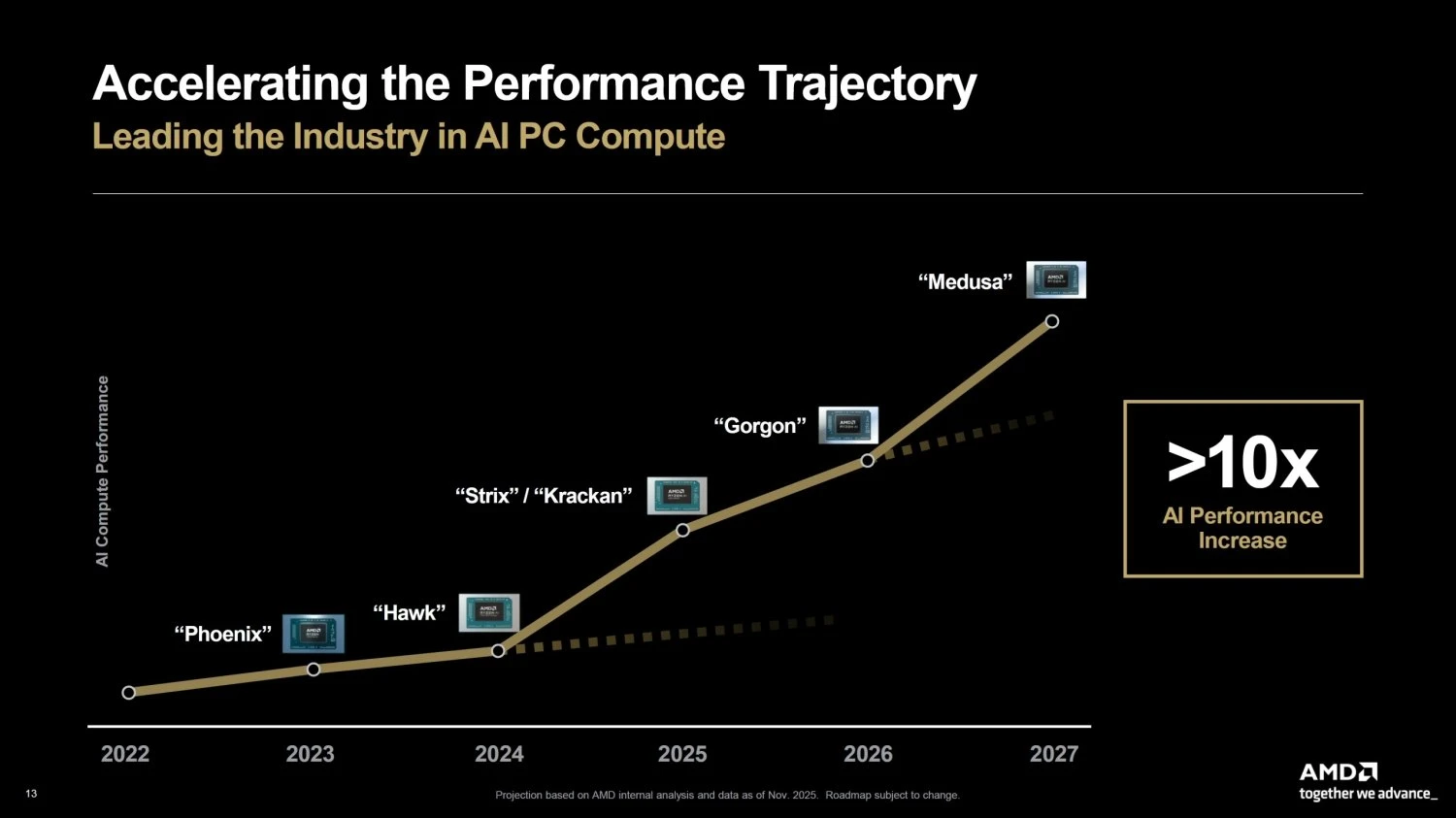
من المنتجات التي تخطط AMD للعمل عليها هي معالجات APU من الجيل الجديد المدمج فيها كارت رسومي من معمارية RDNA 5 وقدرات ذكاء اصطناعي متقدمة. إذ يُتوقع أن يُطلق الجيل الجديد بالإسم الرمزي Gorgon في عام 2026 يليه Medusa في عام 2027.
المعلومات التي حصلنا عليها تشير إلى أن معالجات Gorgon Point APU ستستند على معارية Zen 5 الحالية، لكنها ستأتي بكارت رسومي مدمج من معمارية RDNA 3.5. في حين معالجات أن Medusa APU، التي يتوقع أن تنقسم إلى فئة Medusa Point وفئة Medusa Halo، ستعتمد على أنوية من معمارية Zen 6 من الجيل التالي، وكارت رسومي مستند على معمارية RDNA 5، ووحدة XDNA من الجيل التالي لأعباء عمل الذكاء الاصطناعي.

القوة المفرطة التي ستكون متضمنة في فئة معالجات Medusa Halo مدهشة صراحة، إذ يُتوقع أن تأتي مع 24 نواة و 48 مسار، و 48 وحدة حوسبة رسومية مستندة على معمارية RDNA 5، مع وحدة تحكم في الذاكرة من نوع LPDDR6 وربما LPDDR5X.
التسريب الأبرز والأهم من وجهة نظرنا، الغير مؤكد بعد، أن مستوى أداء المعالج الرسومي المدمج قد يصل إلى مستوى أداء الكارت الرسومي المنفصل RTX 5070 Ti، فإن حصل ذلك فعلًا فسيكون تطورًا مدهشًا وغير مسبوق في عالم وحدات المعالجة المسرعة مما يفتح قيود الأداء في الحواسيب المكتبية الصغيرة و أجهزة الكونسول من الجيل التالي.
شخصيًا أتوقع أداءً رسوميًا من معالجات APU يعادل تقريبًا كارت RTX 5060 لتشغيل الألعاب دون الحاجة لأي كارت رسومي منفصل. الوصول إلى هذه المرحلة يعني أن وحدة المعالج المسرع من الجيل التالي ستحطم القيود الرسومية للكارت المدمج في قالب الرقاقة نفسها. فمن كان يتابع أو جرب مستوى أداء هذه المعالجات منذ أن أطلقت في عام 2011 سيعلم عن ماذا نتحدث.
مسرعات ذكاء اصطناعي جديدة من AMD لمنافسة العملاق الأخضر
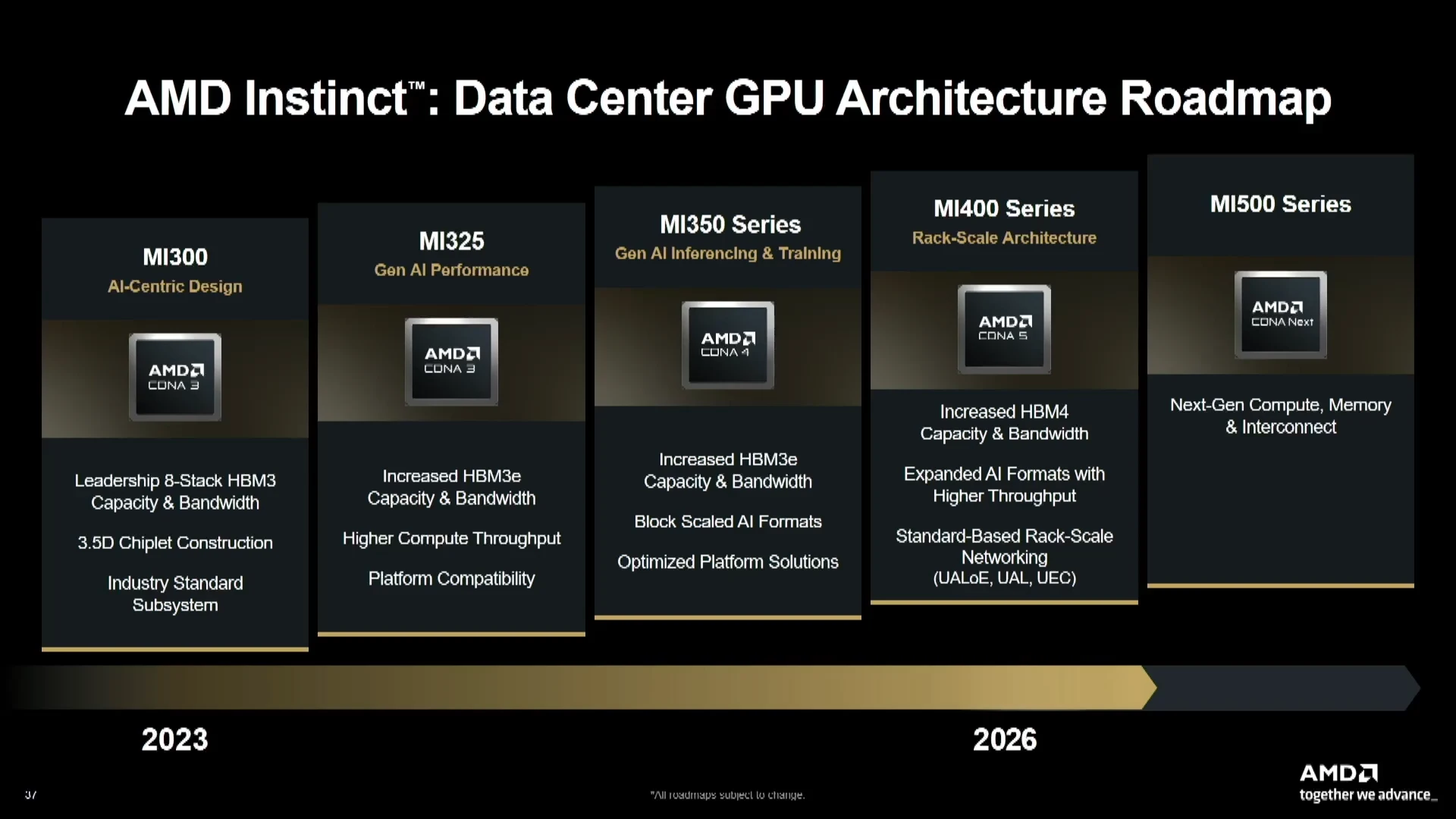
لمنافسة العملاق الأخضر NVIDIA، قررت AMD الإنطلاق في خطواتها التالية في سوق مسرعات الذكاء الاصطناعي والحوسبة عالية الأداء كاشفةً عن سلسلة Instinct MI400 التي تعتمد على معمارية CDNA 5 لمضاعفة أداء الحوسبة مقارنة بسلسلة MI350.
وفقاً لـ AMD، ستصل سلسلة وحدات معالجة الرسوميات المسرعة إلى قوة حوسبة تبلغ 40 بيتافلوبس بتنسيق FP4، و 20 بيتافلوبس بتنسيق FP8. إذ تهدف هذه التحسينات إلى توفير أداء أكثر توازنًا لكل من مهام استدلال الذكاء الاصطناعي وأعباء عمل المحاكاة العلمية. وتعتزم AMD وضع مسرعات MI400 في منافسة مباشرة ضد مسرعات Vera Rubin المرتقبة من NVIDIA.

وقد أكدت الدكتورة ليزا سو، المدير التنفيذي لشركة AMD، أنها تخطط لشحن مسرعات MI400 للشركاء والعملاء في يوم الإطلاق، لتجنب تأخيرات التوريد لجميع الشركات والجهات المتعاقدة معها. ووفقًا للمعلومات الرسمية من المقرر إطلاقها في عام 2026.
كما ستأتي ذاكرة HBM4 بحجم جنوني يصل إلى 432 جيجابايت أي بزيادة عن 288 جيجابايت من الجيل السابق. ويشهد النطاق الترددي للذاكرة أيضاً تفوقًأ كبيرًا، إذ يرتفع من 8 تيرابايت/ثانية إلى 19.6 تيرابايت/ثانية، وذلك بفضل الرابط التوسعي جديد للذاكرة بقدرة 300 جيجابايت/ثانية.
المعلومات الرسمية تشير إلى أن سلسلة مسرعات Instinct MI400 ستستند على نموذجين رئيسيين، النموذج الأول Instinct MI455X وهو مصمم لمهام التدريب والاستدلال المخصص للذكاء الاصطناعي واسع النطاق. أما النموذج الثاني Instinct MI430X يلبي احتياجات الحوسبة عالية الأداء ومبادرات الذكاء الاصطناعي التي تركز عليها الجهات الحكومية.
هل من مزايا فريدة من نوعها؟

نعم، على سبيل المثال يتميز نموذج MI430X بدمج وحدات المعالجة ذات تنسيق FP64 مع دعم هجين لوحدات المعالجة المركزية والرسومية، مما يمكنه من التعامل مع الحسابات العلمية دون الاعتماد كليًا على موارد وحدة المعالجة الرسومية فقط.
كما يعتمد كلا النموذجين على نظام الذاكرة الفرعي HBM4 وكليهما يستخدمان تقنية تغليف CoWoS-L الجديدة، التي تحل محل طريقة CoWoS-S المستخدمة مع الأجيال السابقة. هذا التغيير في طريقة التغليف يحسن من الكفاءة الحرارية ويقلل من تعقيد عملية التصنيع، لأنه حل هجين أكثر مرونة وأقل تكلفة مما يسمح ببناء حزم أكبر من خلال استبدال الوسيط السيليكوني الباهظ الثمن بطبقة RDL الأقل تكلفة.
الجدير بالذكر أن المسرع الرسومي Instinct MI450X أجبر NVIDIA على رفع قدرة استهلاك الطاقة للمسرع Rubin VR200 لفتح مستوى الأداء، إذ كانت مسرعات Rubin في السابق بقدرة 1800 واط، لكنها الآن تصل إلى 2300 واط لمنافسة MI450X التي كانت مصممة بقدرة 2300 واط، لكنها عُدلت مؤخرًا لتصل إلى 2500 واط.
مسرعات MI500 قادمة في عام 2027؟
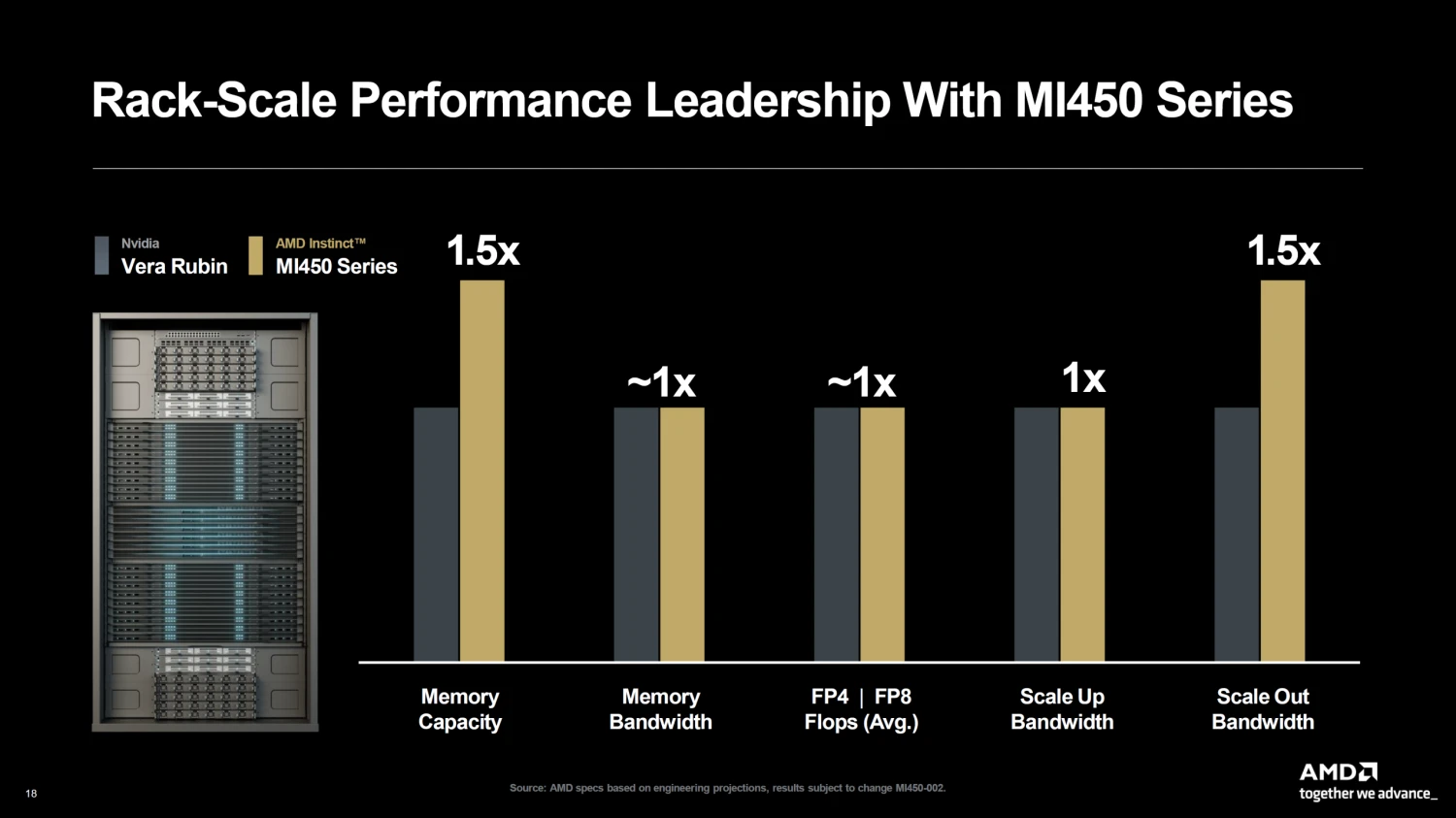
ضمن خارطة الطريق التي كشفت عنها AMD، أكدت المعلومات الرسمية أن تطوير سلسلة Instinct سيتبع إيقاعًا سنويًا لتحسين الأجيال في كل عام للحاق بركب ما تقوم به NVIDIA في عالم مسرعات الذكاء الاصطناعي. فسلسلة MI500 موجودة بالفعل في مرحلة التصميم، ومن المتوقع إطلاقها في عام 2027. للأسف لا تزال التفاصيل حول سلسلة MI500 محدودة وخجولة، لكن من المتوقع أن تستمر في استخدام ذاكرة HBM4 مع حصولها على تحسينات في بنية معمارية CDNA.
الجيل القادم من كروت Radeon سيركز على تتبع الأشعة و AI
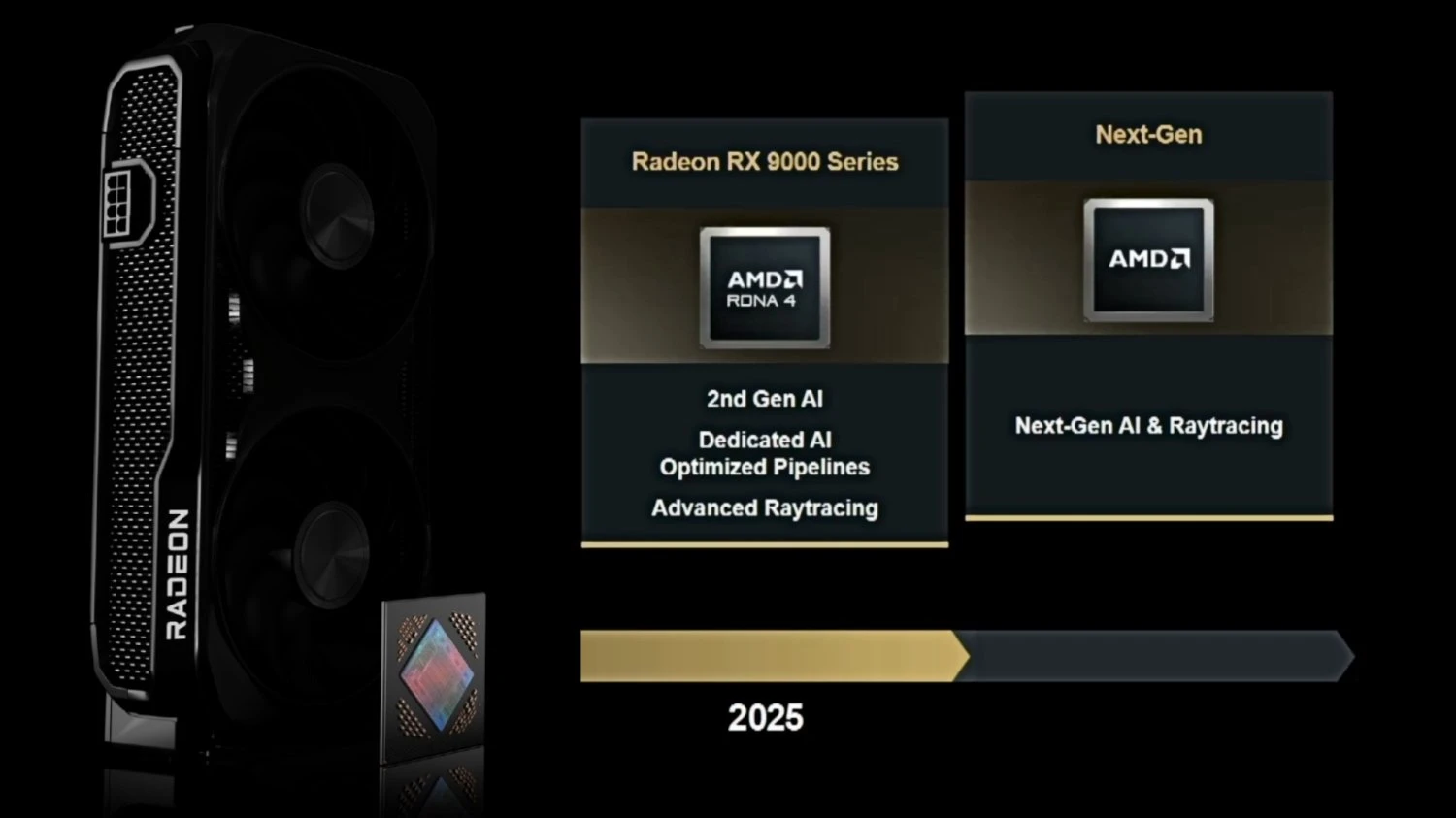
فيما يتعلق بقسم الكروت الرسومية المخصصة للاعبين، فهناك مفاجأة لهم في القريب العاجل، إذ تؤكد AMD أن هناك خطة لتحديث خط إنتاجها بسلسلة جديدة من كروت Radeon. ليس هناك تفاصيل دقيقة حول خارطة الطريق ولكن ما يمكن لنا تأكيده، وفقًا للمعلومات الرسمية، أن الجيل القادم من كروت Radeon سيركز على أمرين رئيسيين: أولهم تطوير معمارية المعالج الرسومي سواء كانت RDNA أو UDNA لتحسين أداء تتبع الأشعة وثانيًا تحسين مستوى أداء الذكاء الاصطناعي.
وقد أشار مارك بيبرماستر، المدير التقني لشركة AMD، إلى أن الهدف من تطوير الجيل القادم هو حصولنا على كروت رسومية ترتقي بمستوى تتبع الأشعة نحو الأفضل، وفي الوقت نفسه تحسين تجربة الذكاء الاصطناعي. فلقد ذكر ضمن حديثه تقنية FSR 4 الحالية المدعومة بالذكاء الاصطناعي، والمقتصرة حاليًا على سلسلة كروت Radeon RX 9000، باعتبارها تقنية مغيّرة لقواعد اللعبة فيما يخص تحسين دقة الصورة ورفع مستوى الأداء.
بكل تأكيد سيكون الشغل الشاغل لمطوري كروت Radeon تحقيق مستوى أداء ملحوظ مقارنة بالجيل الحالي، ولكن من الواضح أن توفير أجهزة قوية للذكاء الاصطناعي مخصصة تحديداً للألعاب وتصيير المرئيات المعقدة المعتمدة على تتبع الأشعة هو النقطة المركزية لخطط AMD المستقبلية مع الجيل الجديد من الكروت.
حتى اللحظة لا نعلم كيف ستكون تسمية الجيل الجديد، فربما تنتقل سلسلة RX إلى إسم آخر، مثل RXD 1000، لأن الجيل الحالي وصل إلى نهايته من ناحية الأرقام RX 9000، ونستبعد رؤية سلسلة كروت Radeon الجديدة باسم RX 10000.
في ختام هذا الملخص لكل ما لدى AMD من جديد في خارطة طريقها المختلفة والمتنوعة، نستطيع التأكيد على رغبة ليزا سو مواجهة NVIDIA بكل ما لديها من قوة خاصة في مجال الذكاء الاصطناعي والمسرعات الرسومية.
لغة النجاح لم تعد تهدف فقط إلى تحسين تجربة اللاعبين، بل إنتقلت إلى كيف نستطيع تحسين تجاربنا المختلفة على الحاسوب الذي يحتوي على كارت رسومي ومعالج مركزي من خلال تقنيات حديثة ومتطورة مثل الذكاء الاصطناعي، ففي سباق الذكاء الاصطناعي، المنافسة شرسة جدًأ لدرجة أن الراحة تعني التخلف لسنوات ضوئية.






