
تعرف على تفاصيل البنية الرسومية Intel Xe بفئتيها HPC و HPG
بعد أن استمر الأمر لفترة طويلة للغاية في مطحنة الإشاعات، أعلنت شركة Intel الأسبوع المنصرم أخيراً بشكل رسمي عن العلامة التجارية لمنتجاتها الرسومية الاستهلاكية عالية الأداء القادمة والتي ستكون معروفة تُجارياً باسم Intel Arc . وكما أخبرتنا انتل، ستغطي علامة Arc الجديدة الأجهزة والبرامج والخدمات، وستمتد عبر أجيال متعددة من الأجهزة والعتاد. حيث سيأتي الجيل الأول، مستندًا إلى الهندسة الدقيقة Xe HPG، التي تحمل الاسم الرمزي Alchemist ، والمعروفة سابقًا باسم DG2. كما وكشفت إنتل أيضًا عن الأسماء الرمزية للأجيال القادمة تحت العلامة التجارية Arcوهي Battlemage و Celestial و Druid.

وقال روجر تشاندلر ، نائب رئيس إنتل والمدير العام لمنتجات وحلول رسوميات العُملاء :" يُمثّل اليوم لحظة مهمة في رحلة الرسوميات التي بدأناها قبل بضع سنوات فقط. إن إطلاق العلامة التجارية Intel Arc وكشف أجيال الأجهزة المستقبلية يدل على التزام إنتل العميق والمتواصل للاعبين والمبدعين في كل مكان. لدينا فرق تقوم بعمل مذهل لضمان تقديم تجارب من الدرجة الأولى وبدون احتكاك عندما تكون هذه المنتجات متاحة في وقت مبكر من العام المقبل.
من ناحية التصميم، ستعتمد المنتجات الرسومية Intel Arc القادمة على الهندسة المعمارية الدقيقة Xe-HPG، وهي مزيج بين معماريات Intel Xe-LP و HP و HPC الدقيقة. والتي ستوفر قابلية كبيرة للتوسّع وكفاءة حوسبة عالية مع ميزات رسومية مُتقدّمة. وطبقاً لإنتل، سوف تتميز مُنتجات Alchemist- الجيل الأول من معمارية Intel Arc- بخاصية تسريع تتبع الأشعة العتادي، وتقنيات تعظيم الصورة المبنية على الذكاء الاصطناعي، كما ستقدم الدعم الكامل لمعيار DirectX 12 Ultimate .
خط البطاقات الرسومية الخاصة بالأداء والمستخدمين الاستهلاكيين Xe HPG
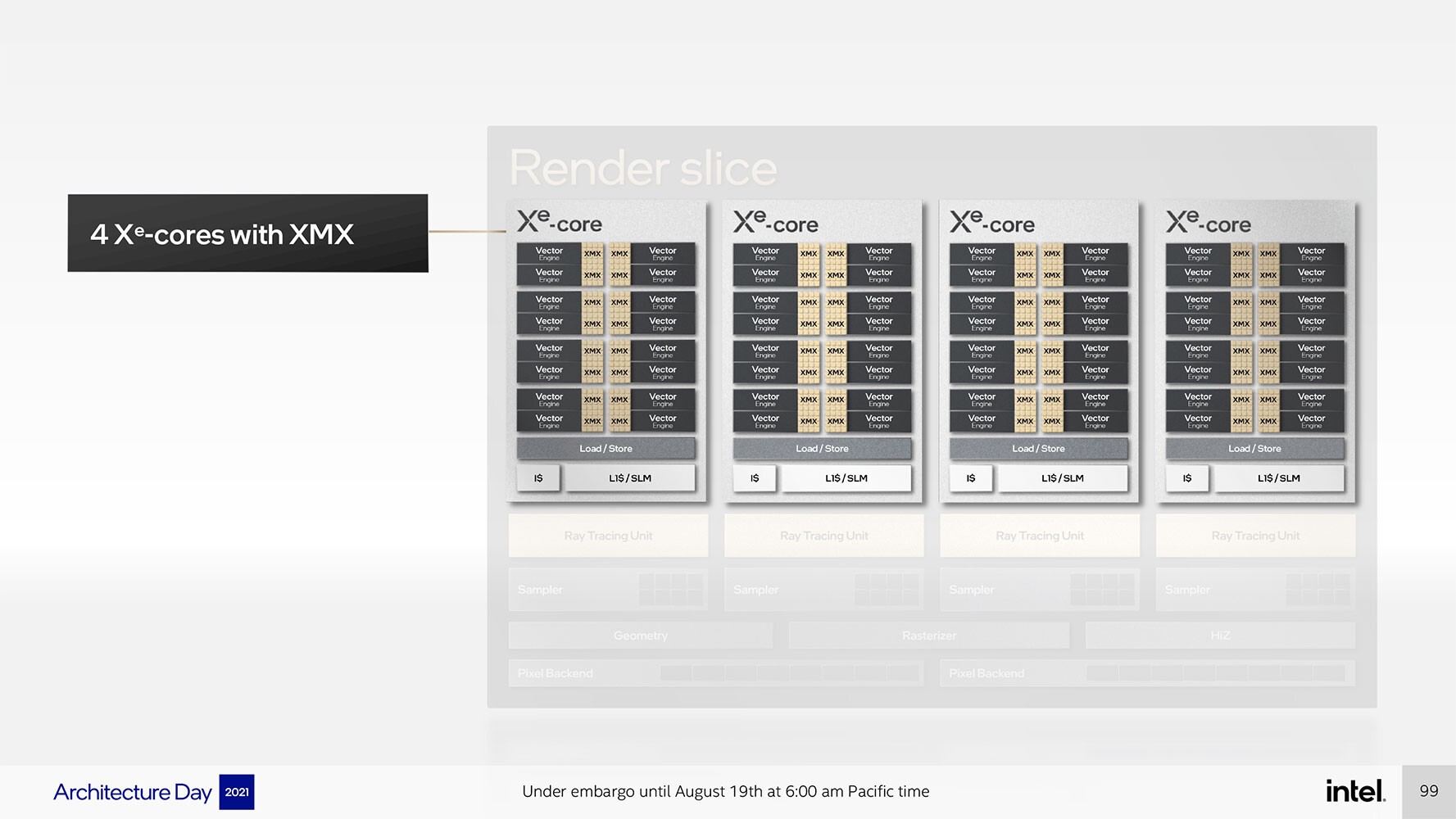
تماماً مثل وحدات الحوسبة Compute Units الموجودة في وحدات المعالجة الرسومية من AMD، ومعالجات التدفق التعددية Streaming Multiprocessors الموجودة في بطاقات NVIDIA، صممت Intel بنية أجهزة حوسبة هرمية قابلة للتطوير لمعمارية Xe HPGالخاصة بها. وتبدأ هذه البنية مع نواة Xe-core . وهي عبارة عن لبنة بناء حسابية غير قابلة للتجزئة تحتوي على 16 محركًا متجهًا vector engine بقدرة 256 بت، ومحركات مصفوفة matrix engines بسعة 1024 بت لكل نواة. يأتي ذلك جنبًا إلى جنب مع أجهزة التحميل / التخزين الأساسية وذاكرة التخزين المؤقت L1. الجدير بالذكر هنا أن وحدة المتجهات أو الـ vector unit قابلة للتبديل مع وحدات التنفيذ ، وتحتوي نواة Xe-core على 16 منها.
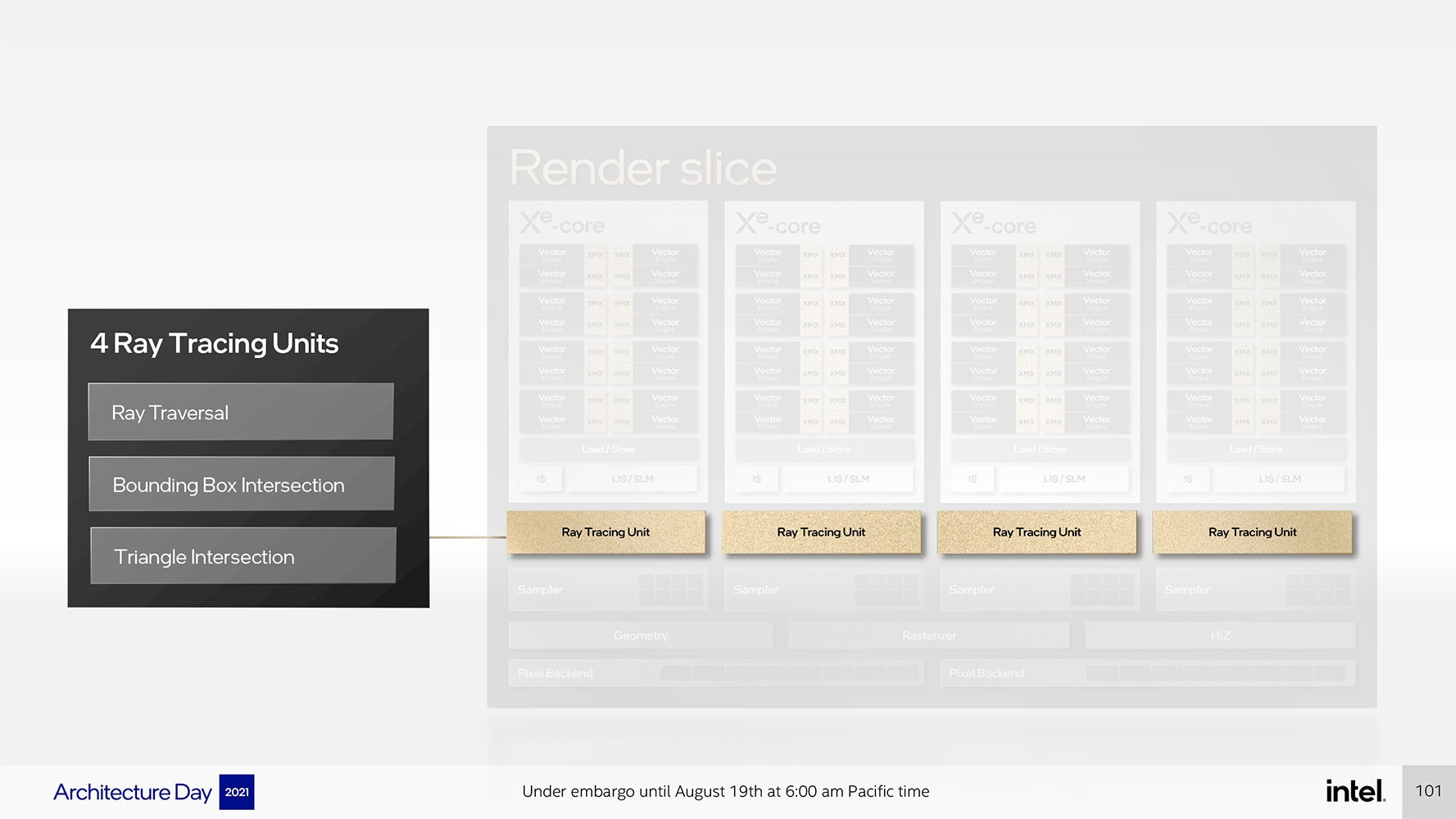
وبهذا تتكون شريحة التقديم أو الريندر (Render Slice وهي عبارة عن المكون المسؤول عن عملية الرندر للرسوم) من مجموعة مكونة من أربعة أنوية Xe ، وأربع وحدات عتادية لتسريع تتبع الأشعة Raytracing ؛ وغيرها من الأجهزة ذات الوظائف الثابتة الشائعة التي تشمل خط الأنابيب الهندسية، وخط أنابيب التنقيط، ووحدات أخذ العينات (geometry pipeline, rasterization pipeline, samplers, and pixel-backends).



وبالانتقال إلى مستوى الأعلى من تصميم المعالج إلى ما بعد شريحة التصيير أو الريندر Render Slice ، نرى أمامنا مُعالج Global Dispatch ونسيج ذاكرة المعالج الرسومي، والتي تبدأ بذاكرة التخزين المؤقت من المستوى الثاني أو L2. وهذا هو المكان الذي يمكن أن تقوم فيه Intel بتوسيع نطاق وقدرات وحدات المعالجة الرسومية الخاصة بها..



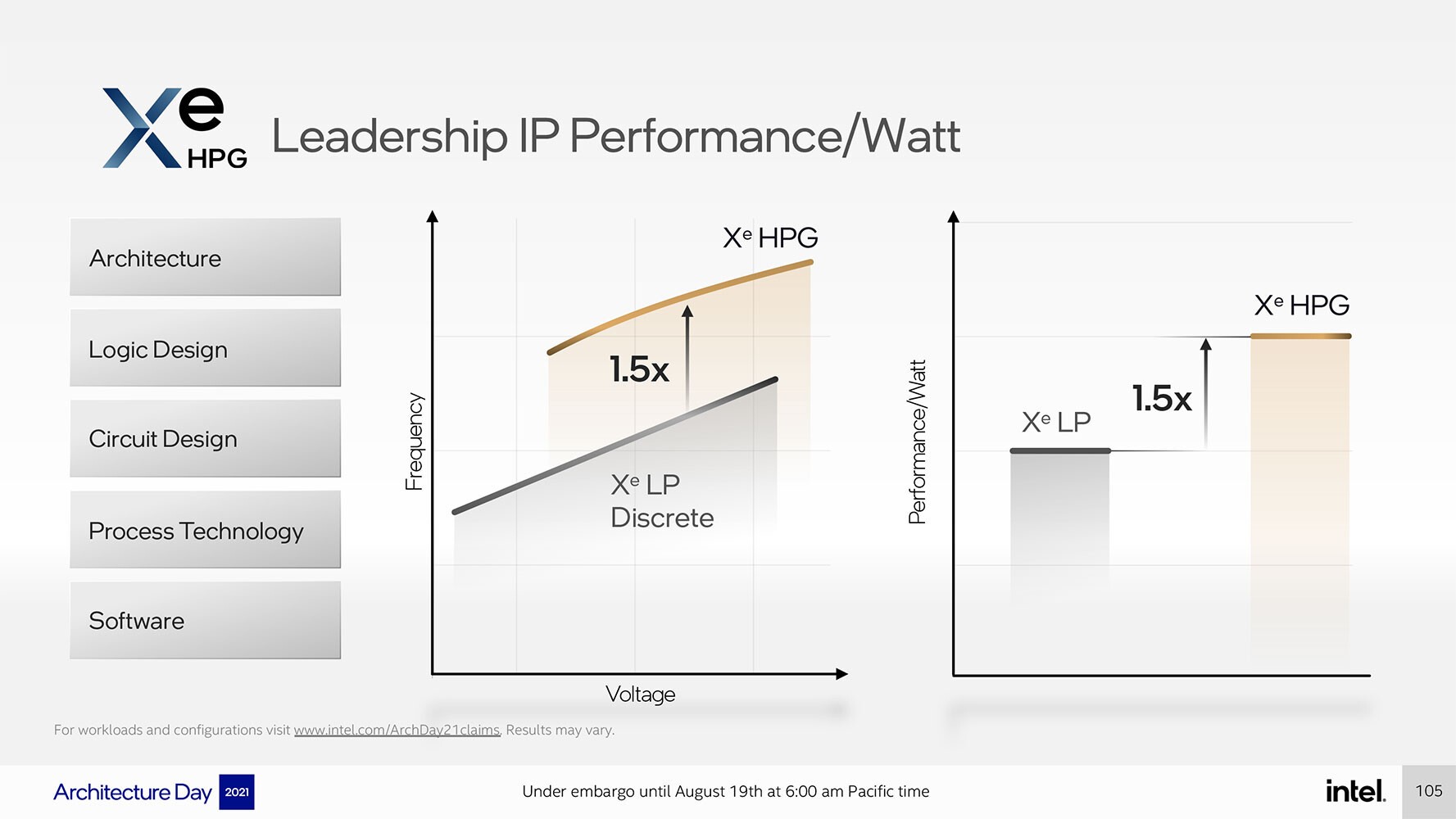
تتميز شريحة السيليكون "Alchemist" بدقة تصنيع 6 نانومتر مع ثماني شرائح تصيير أو ريندر تشترك في النظام الفرعي للذاكرة ووحدات الـ Global Dispatch. وهو ما يعني أن Intel يمكنها ان تقوم باشتقاق المتغيرات عن طريق إزالة شرائح Render بالكامل ، أو ربما حتى عن طريق إزالة وحدات Xe-cores الفردية. وعلى كل حال في نهاية المطاق، فيُمكننا الآن معرفة إجمالي عدد وحدات التنفيذ ووحدات التظليل الكُلية للمعالج الرسومي. فمع 16وحدة EU لكل Xe-core ، و 4 وحدات Xe-core لكل شريحة Render، وعدد 8وحدات Render Slices ، نصل إلى إجمالي 512 وحدة تنفيذ ، أو 4096 معالج تظليل قابل للبرمجة. ونظرًا لتصميم Xe HPG المُصنّع على عملية تصنيع شرائح السيليكون TSMC N6 أي 6 نانومتر، تدعي شركة إنتل تحقيق زيادة بنسبة 50٪ من الأداء لكل وات مقابل حلول Xe LP المبنية على عقدة Intel SuperFin ذات الـ 10 نانومتر ، مثل حلول DG1 و Iris Xe MAX.
وباعتبارها وحدة معالجة رسومية منفصلة من فئة الأداء المرتفع، تتمتع "Alchemist" بمعيار طاقة أكبر بكثير ، وبالتالي فهي تعمل بترددات أعلى بكثير من الحلول السابقة. وعلى الرغم من عدم ذكرها في عرض Intel التقديمي، فقد تم الإبلاغ على نطاق واسع أن "Alchemist" أو (DG2 ) تتميز بواجهة ذاكرة GDDR6 بعرض 256 بت. لم تحدد الشركة حجم الذاكرة بعد، ولكن ونظرًا لسرعات الذاكرة المتوفرة في السوق (14 جيجابت في الثانية و 16 جيجابت في الثانية و 18 جيجابت في الثانية) ، يمكن أن ينتهي عرض النطاق الترددي للذاكرة في أي مكان بين 448 جيجابايت / ثانية إلى 576 جيجابايت / ثانية.
وبالنظر إلى أن البطاقة تأتي مُسلّحة بما يصل إلى 512 × 1024 بت من أنوية المصفوفات المدعومة بامتدادات Xe Matrix "Alchemist" ، فمن المتوقع أن تكون قوة معالجة البطاقة لتطبيقات الذكاء الإصطناعي أو الـ AI واضحة للغاية. وهو ما سيُفيد Intel تحديداً مع ميزة تحسين الأداء وتعظيم الصورة XeSS، بالإضافة إلى تطبيقات التصيير أو الريندر الأخرى في الوقت الفعلي ، مثل تقنيات إزالة الضوضاء لخط أنابيب Raytracing .

من المتوقع أن يتم طرح Intel Arc "Alchemist" في السوق في الربع الأول من عام 2022. كما أن الشركة على ما يبدو جاهزة بخريطة طريق مع ثلاثة من خلفائها على الأقل وهي أجيال ، Xe2 Battlemagومن ثم جيل Xe3 Celestial وبعد ذلك يأتي جيل "XeNext" أو Druid . ولكن مع عدم وجود مقياس زمني مذكور في الشريحة، لا نعرف بالضبط ما إذا كانت Intel ستقوم بتنفيذ قفزة جيلية للبنيات الجديدة على أساس سنوي أم لا.
تقنية تعظيم الصورة بالذكاء الاصطناعي XeSS
في محاولتها لمجاراة سوق المعالجات الرسومية بشكل كامل، ستُطلق شركة Intel كما أخبرنا في السابق تقنيتها الخاصة بتعظيم الصورة استناداً على تقتنيات الذكاء الاصطناعي. وستُطلق الشركة على هذه التقنية اسم XeSS (Xe SuperSampling). حيث أنه من المحتمل أن التسمية جاءت مُلهمة من Xe، حيث قد تكون الشركة تُخطط لتوسيع التكنولوجيا لتدعم حتى وحدات المعالجة الرسومية المُدمجة من فئتي Iris Xe MAX ووحدات Xe LP المنفصلة من الفئة الدُنيا.
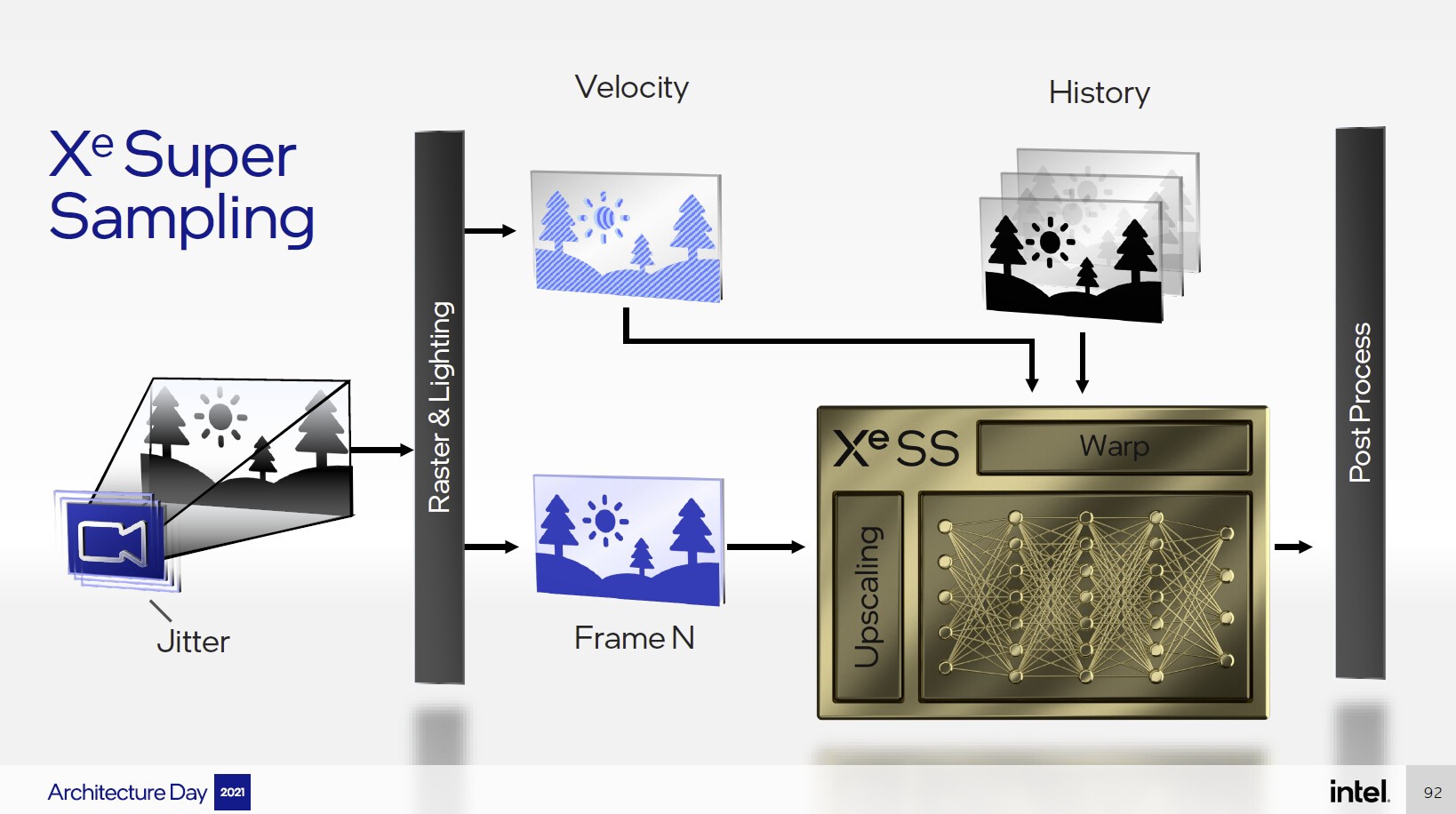
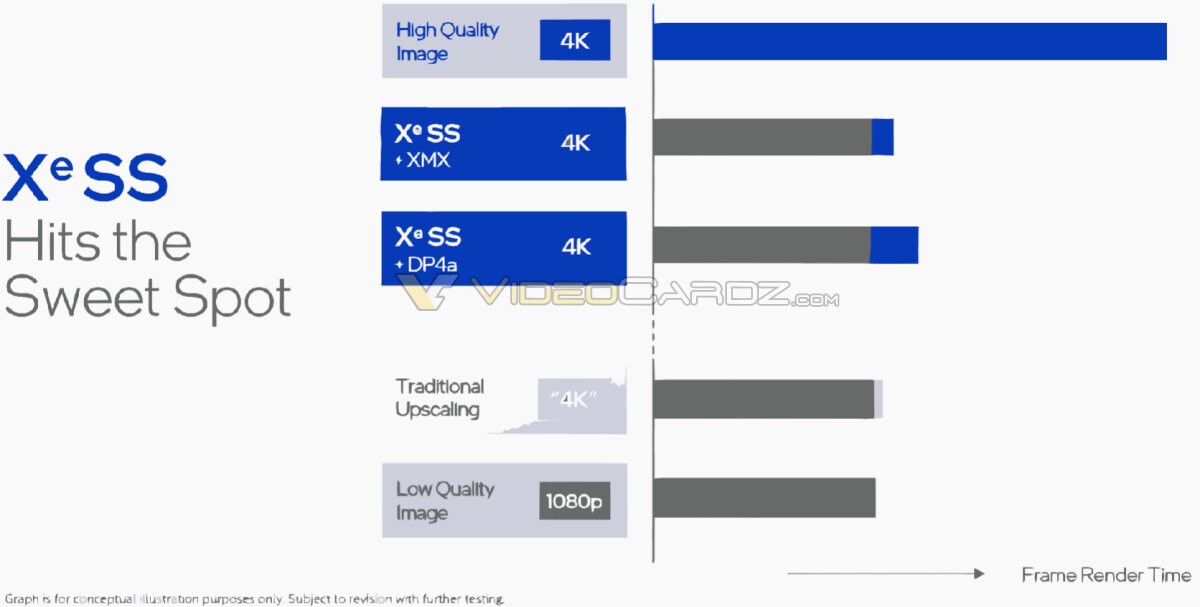



تدعي Intel أن تقنية XeSS الجديدة الخاصة بها تُقلل أوقات عرض الإطارات بدقة 4K بمقدار النصف. لذا وبكل الحسابات، يبدو أن 1440p هي حالة الاستخدام المستهدفة لأعلى بطاقات "Alchemist" . كما أنها ستجعل دقة 4K ممكنًا (على سبيل المثال، يمكن الوصول لدقة العرض المحددة 4K ، من خلال الريندر على دقة عرض أقل ومن ثم تعظيم الصورة، مع استخدام الذكاء الاصطناعي لاستعادة التفاصيل). وقد كشفت الشركة أن XeSS ستستخدم تقنية temporal upscaling القائمة على الشبكة العصبية والتي تتضمن متجهات الحركة. لذا وفي خط أنابيب العرض، ستجلس XeSS قبل معظم مراحل المعالجة البعدية post-processing، وذلك على غرار AMD FSR.
الجدير بالذكر هُنا هو أنه بينما تعتمد تقنية FSR من AMD على التظليل البحت، يمكن لخوارزمية Intel إما استخدام وحدات التسريع XMX (وهي الوحدات الجديدة والموجودة في وحدات Intel Xe HPG)، أو تعليمات DP4a (المتوفرة تقريبًا في جميع وحدات المعالجة الرسومية من AMD و NVIDIA الحديثة). يرمز XMX إلى إختصار لمُسمّى Xe Matrix Extensions وهو في الأساس إصدار Intel من أنوية Tensor Cores من NVIDIA، والتي تعمل على تسريع رياضيات المصفوفة، والتي تُستخدم في العديد من المهام المتعلقة بالذكاء الاصطناعي.
وعلى كل حال، ستتوفر Intel XeSS SDK هذا الشهر ، بشكل مفتوح المصدر باستخدام عتاد XMX، فيما سيكون إصدار DP4a متاحًا "في وقت لاحق من هذا العام".
خط البطاقات الرسومية الخاصة بالخوادم والتطبيقات الاحترافية
على الجانب الآخر، ومن ناحية البطاقات الاحترافية، تدعم بنية Intel Xe HPC (بنية الحوسبة عالية الأداء) أقوى جهاز حوسبة متجه للشركة حتى الآن vector compute device، والذي يحمل الاسم الرمزي "Ponte Vecchio". تم تصميم المعالج الجديد لتطبيقات حوسبة عالية الأداء HPC والذكاء الاصطناعي AI الضخمة ، ولكنه يتميز أيضًا بالقدرة على مُعالجة الرسوميات النقطية raster graphics، وأجهزة تتبع الأشعة في الوقت الفعلي، مما يمنح الشركة القدرة على استخدامها بشكل مزدوج كوحدة معالجة رسومية لخدمات الألعاب السحابية.
غطّينا في الجزء الأول من المقال هندسة Xe HPG ، وتحدثنا عن الأساسيات التي قامت Intel على أساسها بتصميم وحدات المعالجة الرسومية المنفصلة للعميل. ولكن بنية Xe HPC تتوسع وتتدرج من ذلك طولياً وعرضياً. حيث تختلف وحدة Xe-core ، والتي تُعتبر الوحدة الفرعية الأساسية والغير قابلة للتجزئة، الخاصة بهندسة Xe HPC عن تلك الموجودة في هندسة بطاقات العُملاء Xe HPG. فبينما تحتوي أنوية Xe HPG على ستة عشر محركًا متجهًا بسعة 256 بت جنبًا إلى جنب مع ستة عشر محرك مصفوفة بحجم 1024 بت؛ تتميز أنوية Xe HPC بثمانية محركات متجهية بسعة 512 بت ، بالإضافة إلى ثمانية محركات مصفوفة بسعة 4096 بت !. كما أنها تتميز بإنتاجية تحميل / تخزين أعلى ، وذاكرة تخزين مؤقت من المستوى الأول L1 أكبر بسعة 512 كيلوبايت.
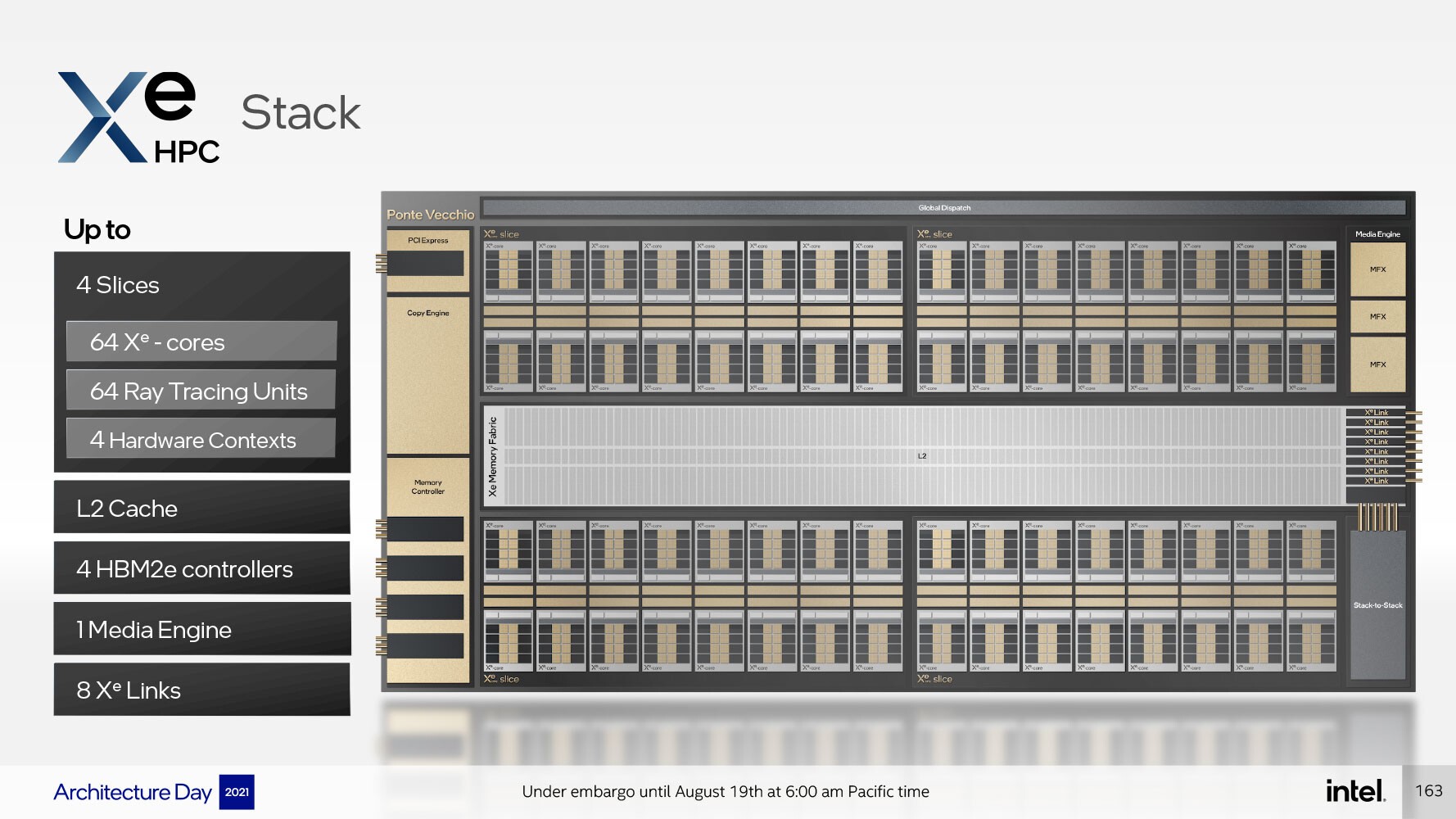



تم تصميم وحدة المتجهات vector unit الأساسية في بنية Xe HPC من أجل توفير أداء FP64 الكامل مع 256 عملية لكل ساعة ، وهو ما يتطابق مع معدل نقل FP32الخاص بها. كما أنه يوفر 512 عملية / ساعة لحسابات FP16.أما وحدة المصفوفة من ناحية أخرى، تحزم 2048 عملية / دورة لحساباتTF32 ، ويمكنها الوصول حتى 4096 عملية تشغيل / دورة لحسابات FP16 و BFloat16، و 8192 عملية تشغيل / دورة لحسابات INT8.
الجدير بالذكر أن شريحة Xe HPC هي عبارة عن مجموعة من 16 نواة Xe HPC ، جنبًا إلى جنب مع 16 وحدة تتبع أشعة مخصصة لها نفس القدرة الحسابية كتلك الموجودة في بطاقات Xe HPG . كما وتحتوي شريحة Xe HPC Slice بشكل تراكمي على 8 ميجابايت من ذاكرة التخزين المؤقت L1 بمفردها.

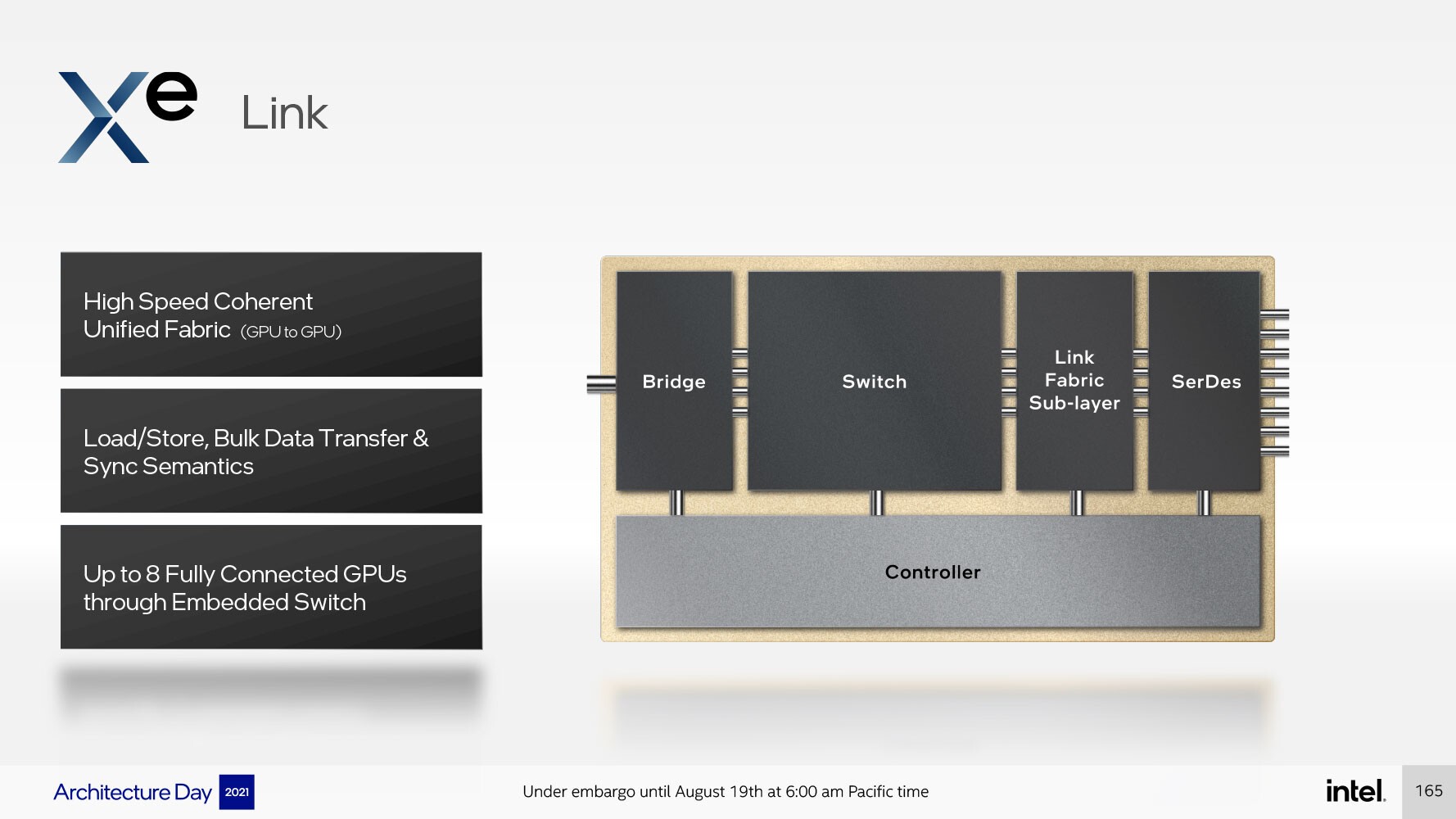
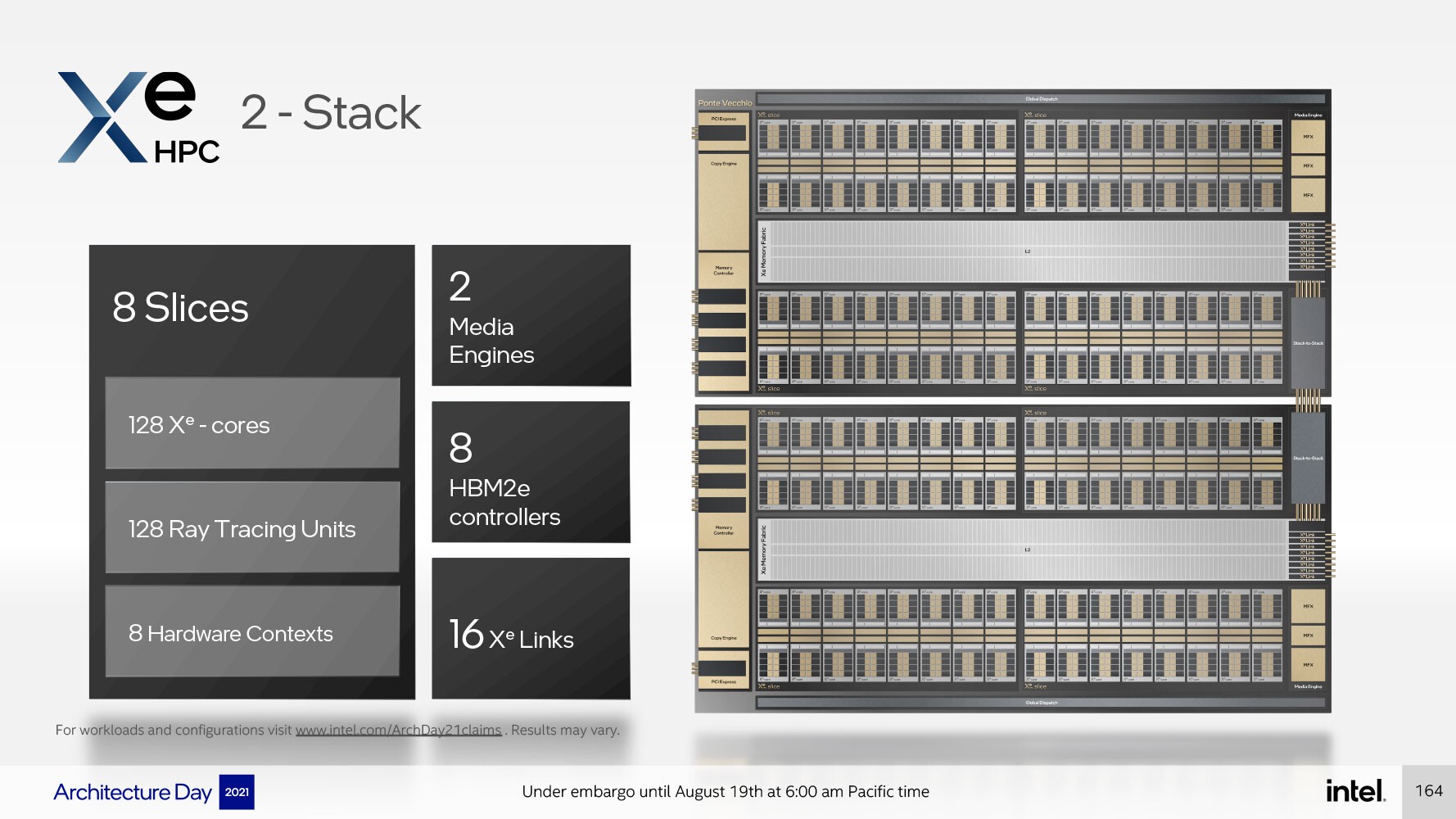
وبشكل عام، تحتوي شريحة أو بلاطة الحوسبة (compute tile) في بنية Xe HPC أو Xe HPC Stack"أيّاً كان المُسمّى الذي تُفضّله" ، على أربعة (Xe HPC Slices) أو شرائح Xe HPC، و 64 نواة Xe HPC و 64 وحدة Raytracing Units، و 4 سياقات للأجهزة (hardware contexts)، وتتشارك فيما بينها ذاكرة تخزين مؤقت من المستوى الثاني L2 كبيرة بسعة 144 ميجابايت. كما وتشتمل المكونات غير الأساسية على واجهة PCI-Express 5.0 x16، وواجهة ذاكرة HBM2E بعرض 4096 بت ، ومحرك تسريع للوسائط مزود بأجهزة ذات وظيفة ثابتة لتسريع فك تشفير تنسيقات الفيديو الشائعة (وربما تشفيرها أيضاً)، ووصلات بينية Xe Link، وهو اتصال داخلي مصمم للتفاعل مع ما يصل إلى 8 مجموعات أخرى من حزم Xe HPC المزدوجة ، بإجمالي يصل إلى 16 مكدسًا.
ويستخدم كل مكدس مزدوج اتصالًا داخليًا ذو زمن انتقال منخفض بين مكدس إلى مكدس. وبالتالي ، ينتهي كل مُكدّس مزدوج بما يصل إلى 128 نواة Xe HPC ، و 128 وحدة تتبع شعاع ، ومحركين للوسائط ، وواجهة HBM2E بعرض 8192 بت. الجدير بالذكر المكدس المزدوج عبارة عن مجموعة ذات صلة هنا في هذا التصميم، حيث يتميز معالج "Ponte Vecchio" على سبيل المثال بقطعتين للحوسبة، أو اثنان من وحدات Xe HPG Stacks) ) وثمانية مكدسات ذاكرة النطاق الديناميكي الواسع HBM2E.




وأخيراً، من المهم أن نلاحظ هنا أن شرائح Xe HPC تجلس داخل قوالب متخصصة تسمى البلاط الحسابي أو (compute tiles ) المصنوع بناء على عملية تصنيع TSMCذات عقدة 5 نانومتر أو N5، بينما توجد بقية الأجهزة على قالب أساسي مبني على عقدة Intel 7 أو 10 نانومتر المُحسّنة SuperFin. وقد تم تكديس القوالب الإثنين باستخدام تقنية التكديس Foveros مع نتوءات بحجم 36 ميكرون. في حين أن بلاط الربط Xe Link هو عبارة عن قطعة منفصلة من السيليكون مخصصة للتواصل مع الحزم المجاورة. تم بناء هذا القالب على عقدة تصنيع TSMC 7 نانومتر ، ويتكون بشكل أساسي من مكونات SerDes (serializer-deserializer).




كل OAM "Ponte Vecchio" يأتي مع اثنين من حزم Xe HPC (one MCM) مع عرض نطاق ذاكرة مدمج يزيد عن 5 تيرابايت / ثانية ، وعرض نطاق اتصال Xe Link يزيد عن 2 تيرابايت / ثانية. كما ويحتوي النظام الفرعي الرباعي أو x4من "Ponte Vecchio" على أربع وحدات OAM، وهو مصمم لعقدة 1U مع معالجي Xeon "Sapphire Rapids". حيث يتم تبريد حزم "Ponte Vecchio" الأربعة ومُعالجيّ "Sapphire Rapids" بالتبريد المائي أو السائل.
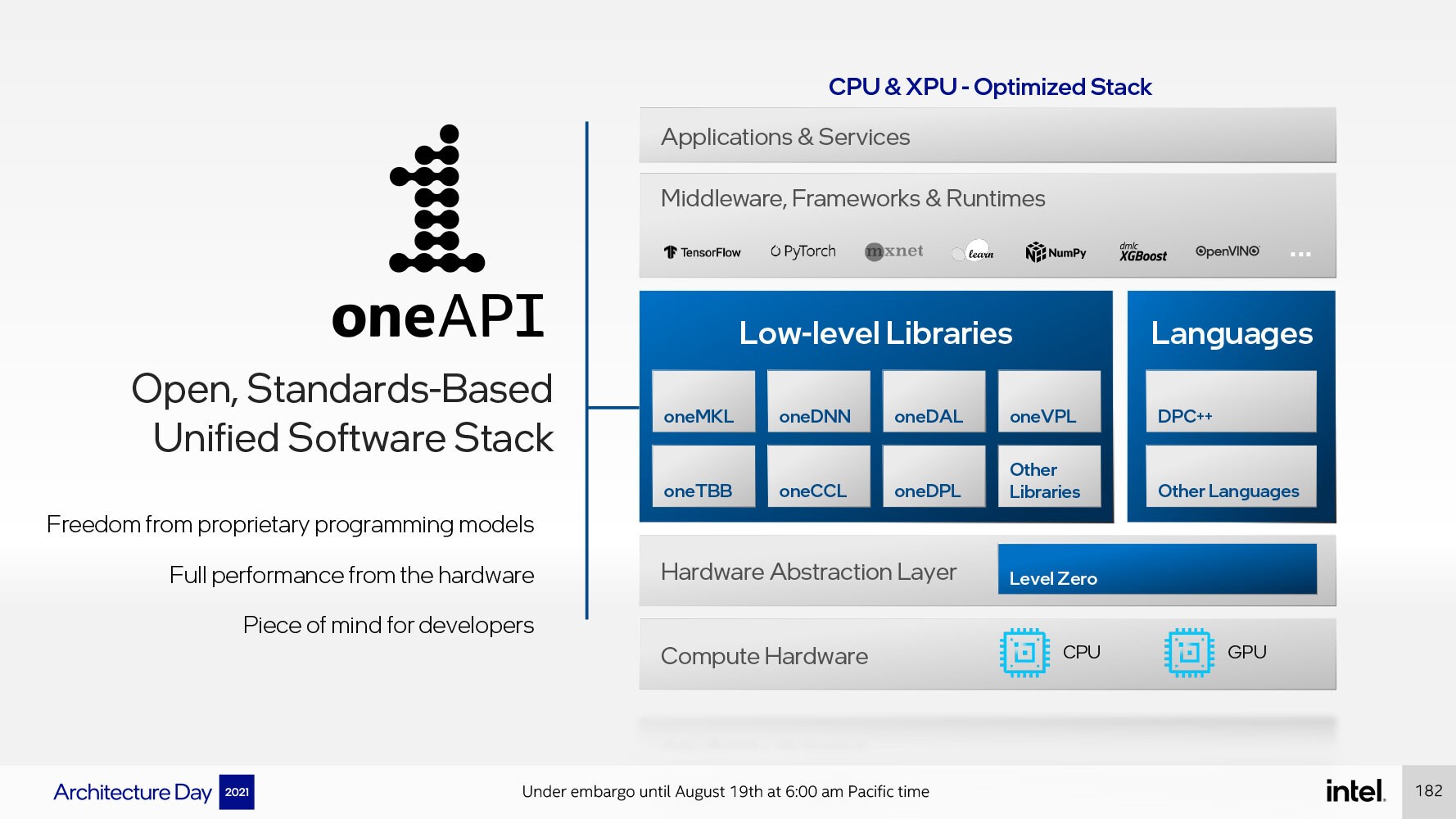
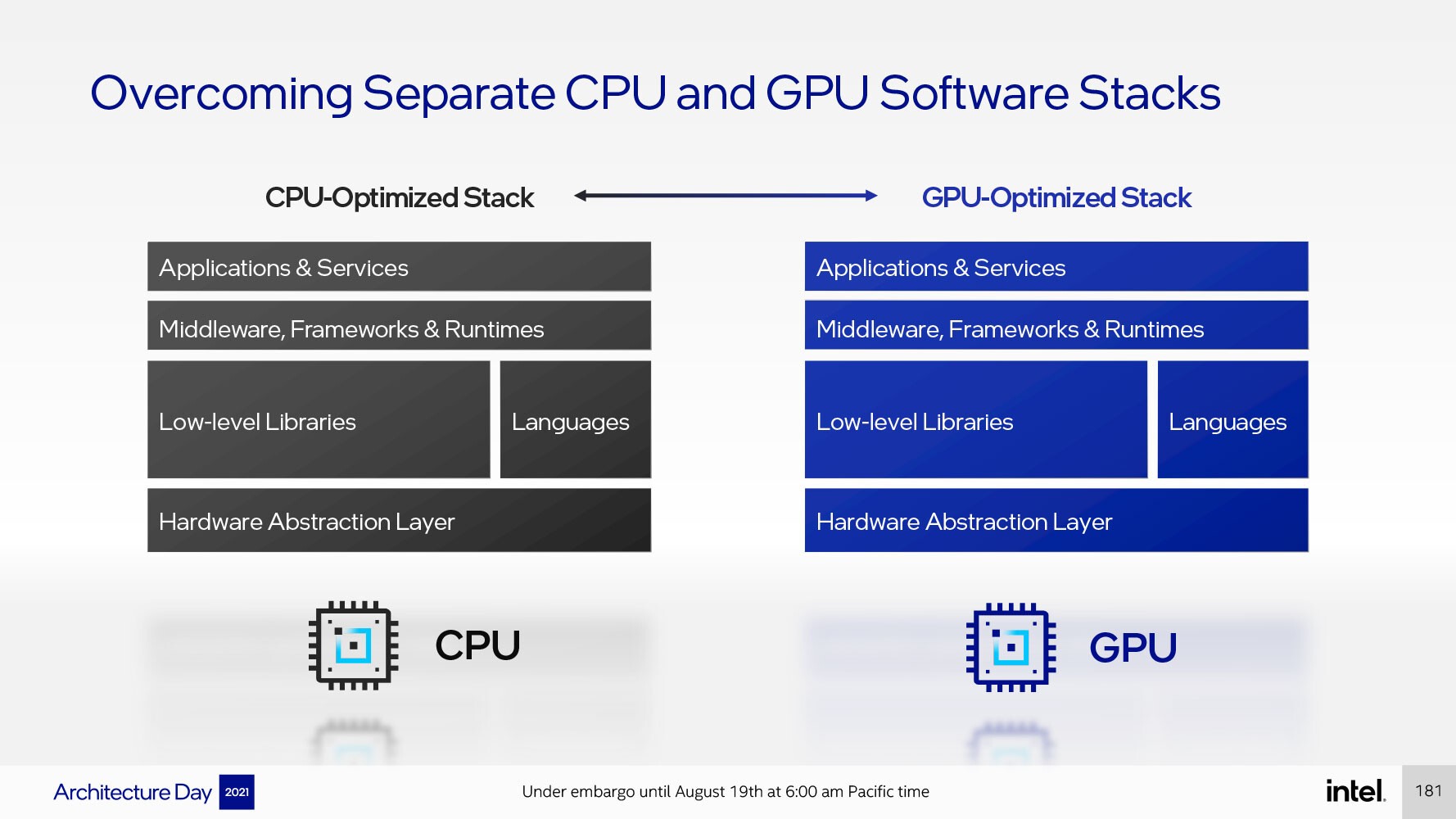

هذا وتؤكد Intel أن الأجهزة ليست سوى جزء من القصة ، حيث تستثمر Intel بشكل كبير في توفير بيئة برمجية موحّدة OneAPI، وهي بيئة برمجة جماعية لكل من وحدات المعالجة المركزية ووحدات المعالجة الرسومية الخاصة بها .
ما الذي يعنيه كل ذلك ؟
في الحقيقة، وبعيداً عن كل تلك التعقيدات التقنية والأجزاء التي قد لا يعرف الكثير منكم الكثير عنها. فالمُحصّلة التي يُمكننا أن نستشفّها من هذه المعلومات التقنية الخاصة بالمعمارية الجديدة من انتل تعني أمراً واحداً. وهو أن شركة Intel تنوي بالفعل الدخول بقوة لسوق المستهلكين وأيضاً سوق الحواسيب عالية الأداء والسوق الإحترافية للخوادم، وذلك تحقيقاً للوعد الذي رأيناه من الشركة في يوم الإعلان وهو أنها تنوي الدخول بمعمارية ARC وبنية Xe ليس فقط لسوق العتاد فحسب، وإنما لتشمل مجموعة واسعة من المُنتجات المتنوعة.
فدخولها لحيز البطاقات الرسومية يعني مُنافسة قوية في هذا السوق، وبالنظر لقدرة انتل التي نعرفها مُسبقاً في مجال الذكاء الإصطناعي، فأنا عن نفسي مُتفائل من تطبيقاتها في هذا المجال، سواء على شكل تقنيات مُستحدثة مثل تقنية تعظيم الصورة الخاصة بها XeSS أو من خلال بطاقات التسريع الحسابية مثل العملاق Ponte Vecchio الذي يُنذر بالمنافسة في مجال الحوسبة عالية الأداء HPC، فلا ضير من الإنتظار قليلاً إذاً !...






