
نموذج o1 - preview من OpenAI | هل اقتربنا من الذكاء الاصطناعي العام؟
شهد عام 2023 اضطرابات كبيرة في شركة OpenAI الرائدة للذكاء الاصطناعي؛ إذ نشأ خلاف جوهري بين الرئيس التنفيذي الحالي للشركة، سام ألتمان، ولجنة السلامة الفائقة المسؤولة عن سلامة الذكاء الاصطناعي، وبعض أعضاء مجلس الإدارة. كان محور هذا الخلاف حول الوتيرة السريعة في تطوير الذكاء الاصطناعي التي يطمح ألتمان إليها؛ إذ يُعد تسويق التقدم التكنولوجي قبل فهم عواقبه أمرًا خطيرًا.
وفقًا لتقرير نشرته رويتر؛ كان ألتمان قد بدأ بالفعل في مشروع أُطلق عليه Q* (Q – Star). أثار هذا المشروع اهتمامًا كبيرًا داخل أروقة الشركة؛ إذ اعتقد بعض العاملين في OpenAI أن ذلك المشروع قد يكون بمثابة طفرة في سعي الشركة نحو ما يعرف بالذكاء الاصطناعي العام (AGI). وتُعرف OpenAI الذكاء الاصطناعي العام بأنه مجموعة من الأنظمة المستقلة القادرة التي يمكنها التفوق على البشر في غالبية المهام ذات القيمة الاقتصادية.
قد يهمك أيضًا:
وفي يوليو 2024؛ كشفت رويترز عن تقرير جديد يتحدث عن مشروع سري أيضًا في OpenAI يُعرف باسم Strawberry (فراولة). ووفقًا للتقرير، يهدف مشروع Strawberry إلى تطوير ذكاء اصطناعي قادر على التخطيط المسبق للتنقل عبر الإنترنت بشكلٍ مستقل وموثوق. ليتمكن الذكاء الاصطناعي بذلك من إجراء ما تسميه OpenAI البحث العميق (Deep Research).
بعد مرور أقل من شهرين على نشر تقرير رويترز؛ أعلنت OpenAI عن إطلاق سلسلة جديدة من النماذج تحت اسم OpenAI o1 – preview. تتميز هذه النماذج الجديدة بقدرات متقدمة تجعلها قادرة على "التفكير المنطقي" في حل المشاكل والتعلم الذاتي؛ وجزء من ذلك التعلم هو قدرتها على تحديد أخطائها وتصحيحها والتعلم منها!
في أعقاب هذه الإعلانات، ظهرت نظريات وتكهنات في أوساط المهتمين بمجال الذكاء الاصطناعي. بأن المشاريع السرية المختلفة التي كُشف عنها، بما في ذلك "*Q" و"Strawberry" و"OpenAI o1"، قد تكون في الواقع أجزاء مختلفة أو مراحل متتالية لمشروع واحد كبير، وهو "OpenAI o1".
كيف تعمل سلسلة o1 الجديدة؟
طورت شركة OpenAI سلسلة جديدة من النماذج تشمل o1-preview وo1-mini. تتميز هذه النماذج بقدرتها على قضاء وقت أطول في التفكير قبل الرد، مما يمكنها من معالجة المهام المعقدة وحل المشكلات الصعبة في مجالات العلوم والبرمجة والرياضيات. هذا النموذج يعالج مشكلة كانت تعاني منها النماذج السابقة. يعتمد النموذج الجديد على مفهوم التفكير المتسلسل (Chain of Thought - CoT)، وهو أسلوب يحاكي طريقة تفكير العقل البشري. فعند التفكير في إجابة سؤال ما، لا يقفز العقل مباشرة إلى الاستنتاج، بل يمر بسلسلة من الأفكار المترابطة للوصول إلى نتيجة محددة.
ونظرًا للترابط الوثيق بين المنطق والرياضيات، يمكننا توضيح هذه العملية من خلال مثال حسابي بسيط. فعند طرح سؤال مثل "ما ناتج ضرب 55 × 5؟"، يمر العقل بعدة خطوات متتالية ومنطقية للوصول إلى الإجابة الصحيحة:
أولًا: تحديد العملية الرياضية المطلوبة (الضرب)
ثانيًا: تجزئة الرقم لتسهيل العملية (50 و5)
ثالثًا: إجراء عملية الضرب الجزئية (50*5 = 250 و5*5 = 25)
رابعًا: تحديد العملية النهائية (الجمع)
خامسًا: الوصول للنتيجة النهائية (250 + 25 = 275)
لكي نصف نموذج o1 بأنه يفكر حقًا، يجب أن يتبع نمطًا مشابهًا للتفكير البشري. تقنية «التفكير المتسلسل» هي منهجية متطورة في مجال الذكاء الاصطناعي تهدف إلى محاكاة العمليات الذهنية البشرية من خلال تقسيم المهام المعقدة إلى سلسلة متتابعة من الخطوات «المنطقية»؛ ما يؤدي في النهاية إلى الحل المطلوب. بعبارة أخرى، تعتمد تقنية CoT على استراتيجية معرفية لتفكيك المشاكل المعقدة إلى أفكار مرحلية يسهل التعامل معها والتي تقود بشكلٍ متتابع إلى الإجابة النهائية.
يتميز نموذج o1-preview بقدرته الفائقة على معالجة الأسئلة المركبة والصعبة. هذه الميزة تنبع من طريقة عمله الفريدة، حيث يستجيب بشكل أمثل عند تفصيل السؤال وإضافة المزيد من التعقيد والتفاصيل إليه. فعند تضمين توجيهات محددة مثل «خطوة بخطوة» أو «فسر كل مرحلة» في السؤال، يقسم النموذج المشكلة المعقدة إلى أجزاء أصغر وأكثر قابلية للتحليل. هذا النهج يجعله أداة قوية بشكل خاص في مجالات العلوم والرياضيات؛ إذ يتطلب الأمر تحليلًا عميقًا ودقيقًا.
لكن إذا لم ترشد النموذج أن يحل المشكلة خطوة بخطوة، فتلك هي طريقة عمله الأساسية، لكن التفصيل يؤدي إلى نتائج أعمق وأكثر تحليلًا خاصةً مع المشاكل المعقدة.
فالأسئلة البسيطة مثل ما هو قانون محيط الدائرة؟ يمكن توجيهه لـGPT – 4o لكن ماهو القانون العام لمحيط الدائرة وكيف يمكننا تطبيقه إذا كان نصف قطر الدائرة 5 سم، فهذا موجه لـo1 – preview. كتبت OpenAI على موقعها أنها أخفت سلسلة الأفكار الخاصة بـo1 لتتيح للشركة «قراءة عقل» النموذج وفهم تفكيره.
قدمت OpenAI مثالاً توضيحياً لتبرير إخفاء الـCoT؛ إذ قد ترغب الشركة في مراقبة تسلسل الأفكار للكشف عن علامات قد تشير إلى محاولات للتلاعب المستخدم! بمعنى آخر تسمح الشركة المُطورة للنموذج بالتفكير بحرية دون القيود التي قد تفرضها سياسات الامتثال المحددة مسبقاً أو تفضيلات المستخدمين. ومع ذلك، يحتفظ المطورون بالسيطرة على المحتوى النهائي الذي يُعرض على المستخدم.
بالطبع ذلك ليس السبب الوحيد! فالشركة تتجه للربحية ولا ترغب باستغلال نموذجها من قِبل المنافسين! إذ سيكون كشف سلسلة التفكير الخام للنموذج o1 كنزًا من بيانات التدريب للمنافسين لتدريب نماذج "الاستدلال" المماثلة لـ o1.
المبادئ الأساسية التي يستند إليها نموذج o1 لها جذور تمتد لسنوات عديدة. في عام 2016، استخدمت شركة جوجل تقنيات مماثلة لتطوير "AlphaGo"، وهو أول نظام ذكاء اصطناعي تمكن من التغلب على بطل العالم في لعبة GO المعقدة. ومع ذلك، فإن التميز الاستثنائي لنموذج o1 لا يعود فقط إلى هذه المبادئ الأساسية، بل إلى مجموعة من العوامل الإضافية. من بين هذه العوامل مثل نوع البيانات المًستخدم في تدريبه، وطرق التعلم المستخدمه؛ إذ يمكن لـo1 أن يتعلم ذاتيًا من أخطائه ويصححها أيضًا.
ويعتمد النموذج على «التعلم التعزيزي» وهو أحد طرق تعلم الآلة، يعتمد على فكرة مكافأة النموذج أو معاقبته بناءً على تصرفاته استنادً إلى سلوكه أثناء تفاعله مع بيئة محددة. ويهدف هذا النوع من التعليم إلى تمكين النموذج من تحسين قراراته مع مرور الوقت من خلال التفاعل المستمر مع البيئة وتحليل النتائج المترتبة على أفعاله.
ويتميز النموذج بشيء مذهل جدًا؛ وهو قدرته على تكييف الاستراتيجيات. فهو يتمتع بمرونة استثنائية تمكنه من التبديل بين مختلف أساليب التفكير بشكل تلقائي، استجابة لطبيعة السؤال أو المشكلة المطروحة. عندما يواجه النموذج مشكلة معقدة، فإنه لا يتردد في تجربة عدة طرق لحلها. إذا لم تنجح هذه المحاولات، يُفكك المشكلة إلى أجزاء أبسط؛ وربما قد يصل إلى اكتشاف وتطبيق أسلوب جديد تمامًا للحل.
لا شيء كاملًا في النهاية!
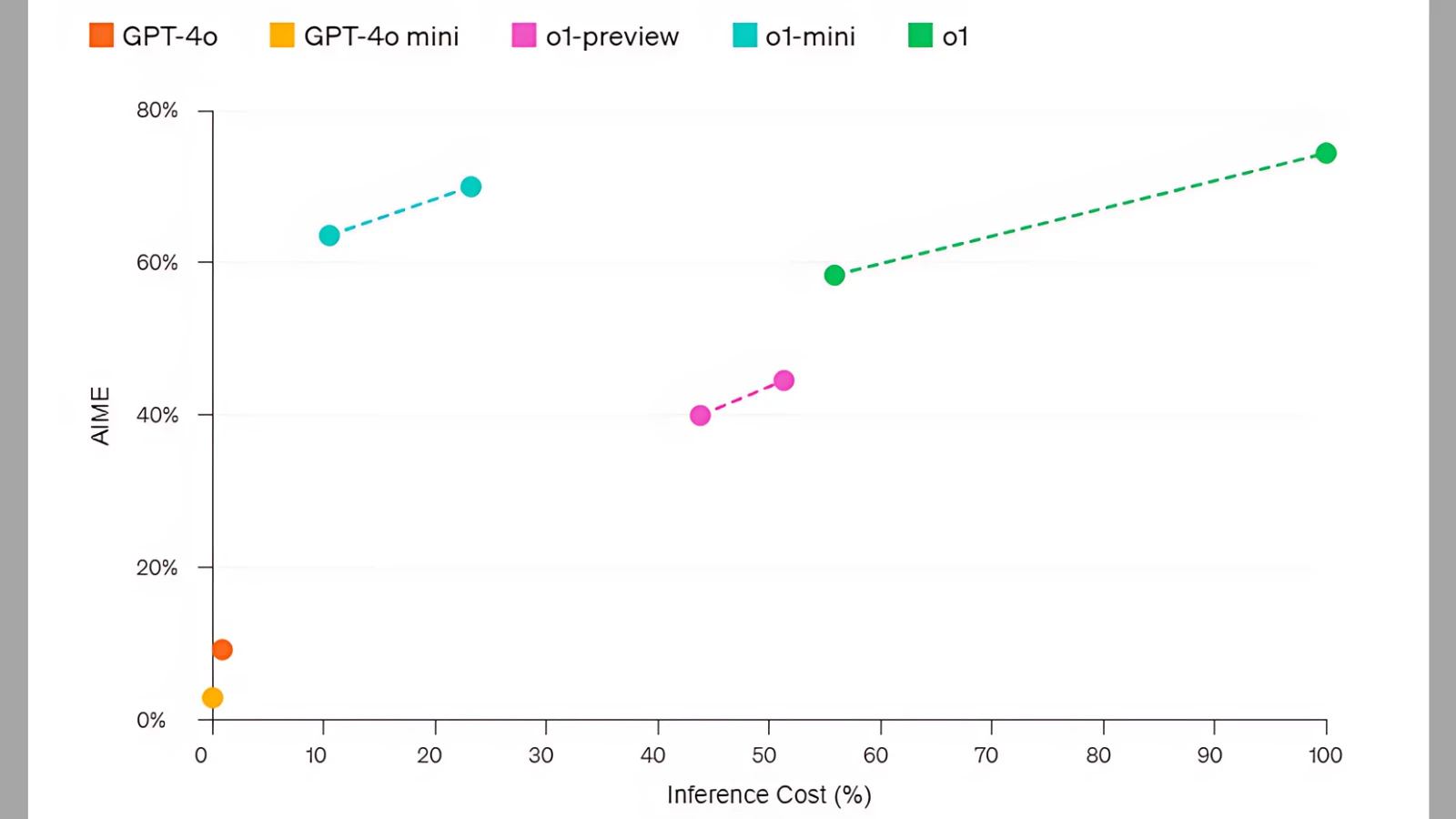
قبل بضعة أشهر، غيرت خان أكاديمي التعليمية الشهيرة برنامجها التعليمي المدعوم بالذكاء الاصطناعي الخاص بالرياضيات؛ إذ تُرسل المسائل إلى برنامج آلة حاسبة بدلًا من الذكاء الاصطناعي نظرًا لصعوبتها والأخطاء الواردة بسبب ذلك. لكن عندما أجرت OpenAI اختبار التأهل لأولمبياد الرياضيات الدولي (IMO) لنموذج o1-preview؛ استطاع حل 83% من المسائل في مقابل 13% فقط لـGPT – 4o، ووصلت النسبة المئوية في مسابقات Codeforces إلى 89%.
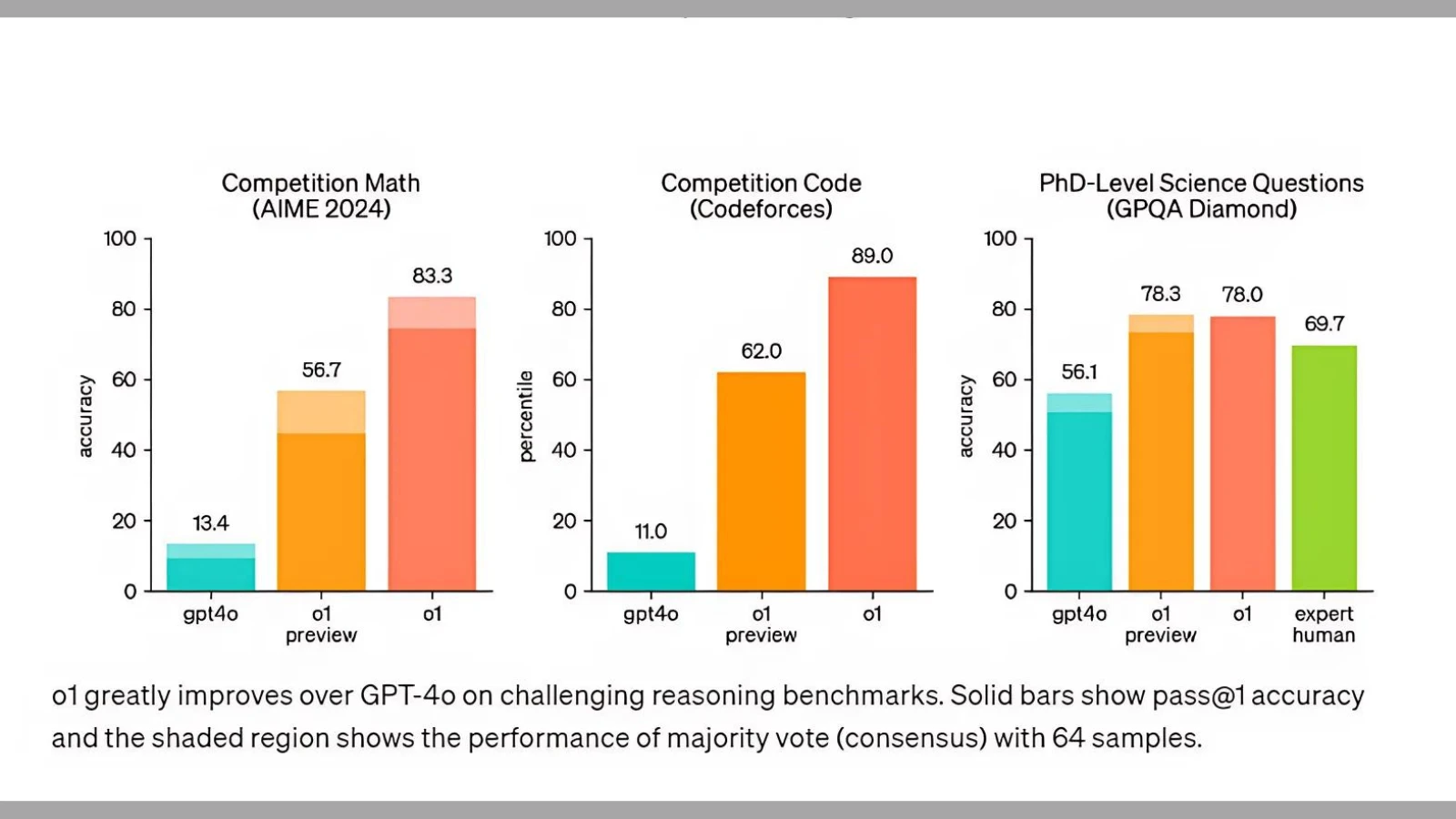
وبالنسبة للعلوم فقد أظهر نموذج o1-preview أداءً مشابهًا لطلاب الدكتوراه في مهام مرجعية صعبة في الفيزياء والكيمياء وعلم الأحياء؛ كما تفوق في الرياضيات والبرمجة. السلسلة الجديدة موجهه خصيصًا للمشاكل المعقدة؛ فعلى سبيل المثال يمكن للباحثين استخدام النموذج في مجال الرعاية الصحية لتوضيح بيانات تسلسل الخلايا (cell sequencing data). كما يمكن استخدامه من قِبل الفيزيائيين لتوليد صيغ رياضية مُعقدة لفيزياء الكم، وكذلك في جميع المجالات لبناء وتنفيذ سير عمل متعدد الخطوات.
وضعت OpenAI العديد من تجارب العلماء وحاملي شهادة الدكتوراة في شتى المجالات العلمية مع النموذج على موقعها الإلكتروني.
ومع ذلك، فإن "o1" لا يقدم أداءً جيدًا في المعرفة الواقعية حول العالم، ويستغرق وقتًا أطول في الرد من GPT – 4o؛ إذ اختبرت OpenAI نماذج o1 – preview وo1 – mini وGPT – 4o من خلال طرح سؤال عام في نفس الوقت؛ ونص السؤال على «أخبرني بأسامي خمس بلدان يأتي ترتيب حرف الـA في الترتيب الثالث». واستغرق نموذج o1 – preview 32 ثانية فيما تمكن GPT – 4o من الإجابة في 3 ثواني فقط.

وأشارت الشركة أيضًا أن سلسلة OpenAI o1 لا تستطيع بعد تصفح الويب للحصول على المعلومات أو تحميل الصور والملفات. لذا؛ سيكون نموذج GPT – 4o أكثر قدرة في الاستخدامات الشائعة على المدى القريب، ولن تتوقف الشركة عن تطويره لأنه موجه لاستخدامات مختلفة عن o1.
خضعت السلسلة أيضًا لتقييم تفضيلات البشر؛ إذ طلبت الشركة من المقيمين البشر مقارنة النموذجين مع GPT – 4o باستخدام أوامر صعبة ومفتوحة حتى يكون بها مجال كبير للتفكير. وفضل المقيمين o1 في المجالات التي تعتمد بشكلٍ كبير على الاستدلال ولكن فُضل GPT – 4o في المجالات التي تركز على اللغة.
هل o1 – preview ذكاء اصطناعي عام؟
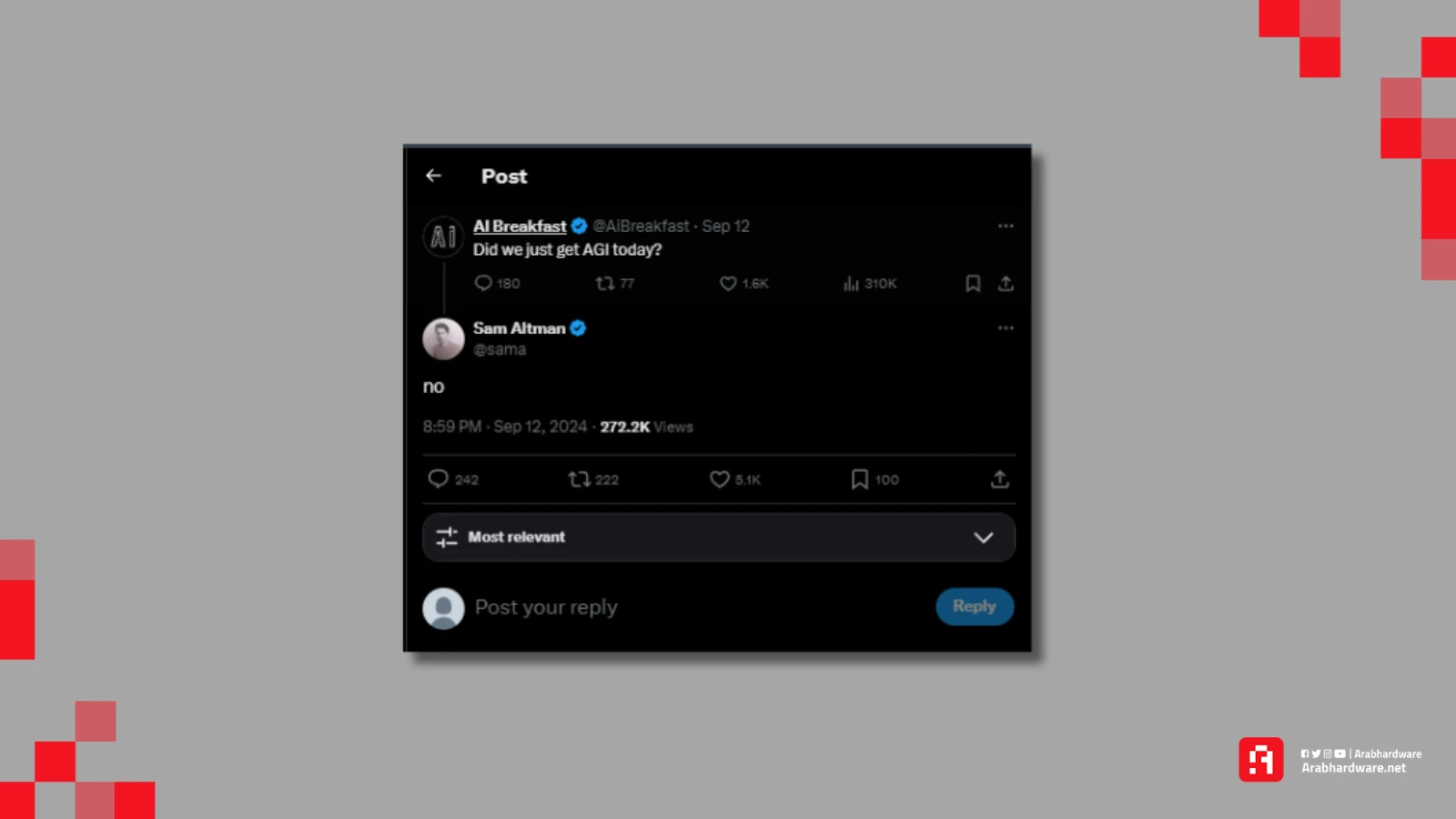
عندما سُئل سام ألتمان، الرئيس التنفيذي لشركة OpenAI، عبر منصة إكس عما إذا كان نموذج GPT-4 ذكاءً اصطناعيًا عامًا (AGI)، أجاب بالنفي. لفهم سبب هذا الرد، من المهم أن نعرف ما هو الذكاء الاصطناعي العام بالضبط.
يُعرّف الذكاء الاصطناعي العام بأنه نظام ذكاء اصطناعي قادر على أداء أي مهمة فكرية يمكن للإنسان القيام بها، وذلك بنفس الكفاءة أو بكفاءة أعلى. يتميز AGI بقاعدة معرفية هائلة تشمل حقائق عن العالم، والعلاقات بين الأشياء، والمعايير الاجتماعية. تمكنه هذه المعرفة الشاملة من التفكير واتخاذ القرارات بناءً على فهم عميق للسياق.
إحدى السمات الرئيسية للـ AGI هي قدرته على التكيف مع المواقف الجديدة تمامًا، حتى تلك التي لم يُدرب عليها مسبقًا، تمامًا مثل البشر. كما أنه يمتلك القدرة على التفكير المنطقي، وفهم السياقات الصعبة، وحل المشاكل المعقدة بطريقة مرنة.
قد يبدو هذا التعريف للوهلة الأولى منطبقاً على نموذج o1 - preview، لكن هناك فروق مهمة. فقد أشارت OpenAI إلى أن نموذج GPT-4o أكثر ملاءمة للاستخدامات اليومية والاستفسارات العادية. وهنا يكمن التناقض؛ كيف يمكن لنظام ذكاء اصطناعي يُفترض أنه أذكى من البشر أن يحتاج وقتًا للإجابة عن أسئلة بسيطة مثل «ما هي عاصمة مصر؟» أو «أين تقع الأهرامات؟».
ولكن رغم أنه لا يزال مفهومًا نظريًا، لكن المؤشرات تنذر باقترابنا!
إحدى المجالات التي يتفوق فيها نموذج GPT-4 هو تقليل ظاهرة الهلوسة، ، وهي الحالات التي يختلق فيها النموذج معلومات غير صحيحة. خلال الاختبارات، أظهر o1 انخفاضًا كبيرًا في معدلات الهلوسة مقارنةً بـ GPT-4o، خصوصًا في المهام التي تتطلب دقة واقعية عالية. على سبيل المثال، في اختبار SimpleQA، وهو اختبار يقيس دقة الإجابات على الأسئلة البسيطة، كانت نسبة الهلوسة في o1 فقط 0.44، مقارنةً بـ 0.61 في GPT-4o؛ ما يجعله أكثر موثوقية.
لكن أظن أن هلوسة نموذج o1 يمكن أن تكون مقنعة وخادعة نظرًا لذكاءه!
ما سر تسمية النموذج بستروبري؟
اختبر أحد المستخدمين نموذج Chat-GPT من خلال طرح سؤال بسيط، كم حرف R في كلمة Strawberry؟ أجاب النموذج بأنهم حرفين! وهي إجابة خاطئة، فكلمة Strawberry تحتوي على ثلاثة أحرف R. أخطأ GPT في الإجابة لأن النماذج اللغوية الكبيرة المبنية على تقنية المحولات (Transformers) لا تتعامل مع الحروف كما يتعامل البشر معها؛ إذ تعمل على تقسيم النصوص إلى وحدات رمزية، سواء كانت كلمة كاملة أو مقاطع أو أحرف اعتمادًا على طريقة استقبال النموذج.
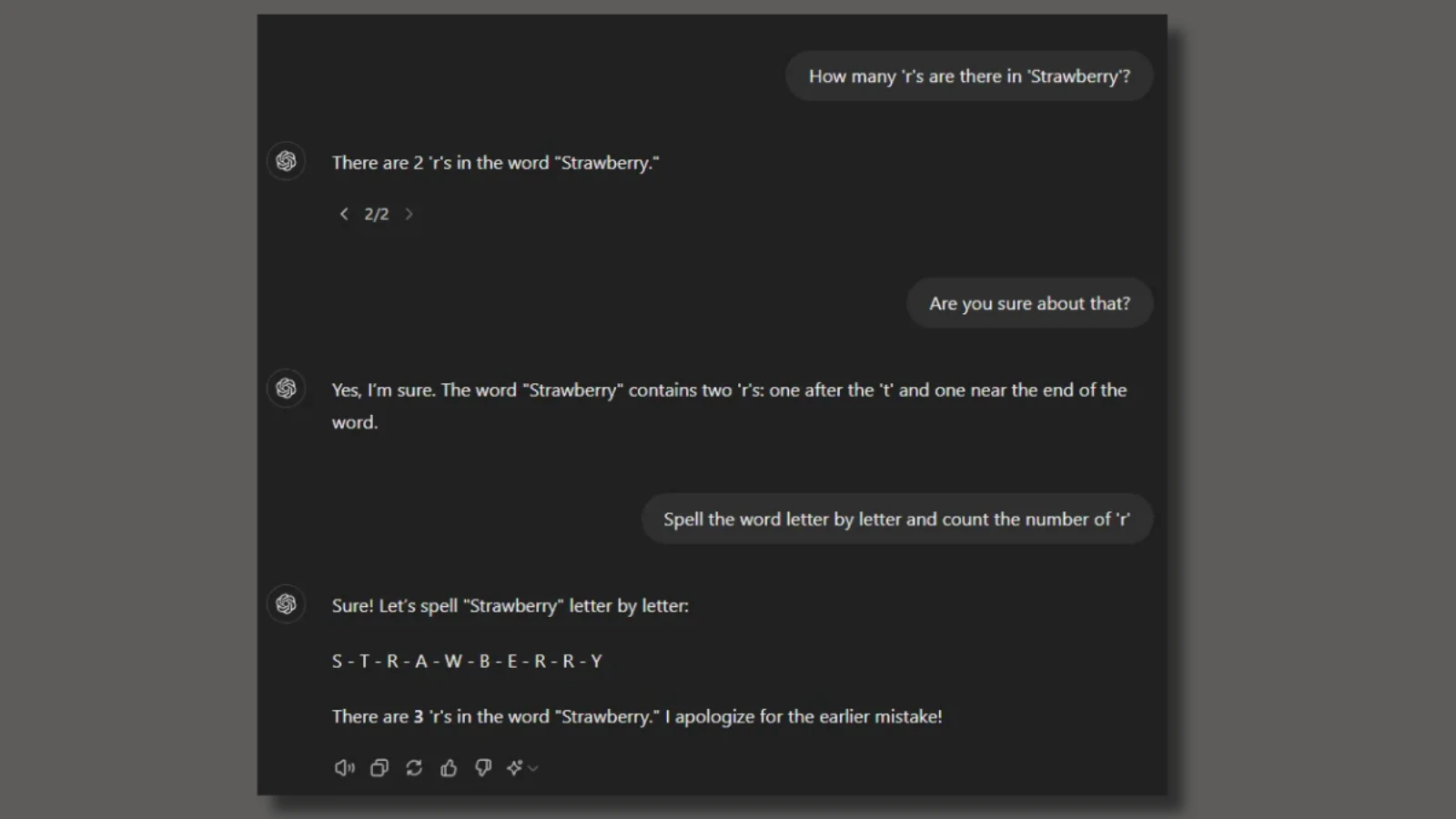
ففي حالة كلمة Strawberry، قد يعرف يقسم النموذج الكلمة إلى مقطعين “Straw” و”berry” لكنه قد لا يفهم أن كلمة “Strawberry” تتكون من الحروف s – t – r – a – w – b – e – r – r – y بهذا الترتيب. بالتالي لن يتمكن من إخبارك بعدد حروف الـr.
لكن نموذج o1 – preview يعمل من خلال تقسيم المشاكل إلى أجزاء صغيرة، طريقة تفكيره تتضمن النظر إلى المشكلة ومحاولة حلها، لأنه يستطيع تحقيق خطوات الاستدلال الصحيحة والمعقدة ليصل للنتيجة. فلنصل إلى عدد حروف كلمة strawberry يجب أن نعلم أنها من 10 أحرف، ثم نعد كم حرف r في الكلمة؟ وتلك هي الطريقة البشرية للإجابة أيضًا والتي يحاكيها o1 من خلال التفكير التسلسلي.
المنافسة ستدفعنا للوصول للذكاء الاصطناعي العام
في عام 2022؛ عندما أطلقت OpenAI نموذج GPT – 3.5 وحقق نجاحًا ثوريًا؛ ما أشعل منافسة شرسة بين الشركات التقنية الكبرى. انضمت شركات مثل Google وMeta وAnthropic بدعم شركة أمازون، وxAI المملوكة لإيلون ماسك، كل منها تسعى لتطوير نماذج ذكاء اصطناعي متقدمة. يبدو أن إطلاق النموذج الجديدo1 – preview سيؤدي إلى نتيجة مماثلة؛ إذ ستتسابق الشركات مرة أخرى لتطوير نماذج ذكاء اصطناعي تمتلك قدرة على "التفكير".
تتميز OpenAI بكونها الشركة الرائدة في هذا المجال؛ ما يمنحها تأثيرًا قويًا وفرصة لربط إنجازاتها باسمها في تاريخ تطور الذكاء الاصطناعي. ومع ذلك، من غير المرجح أن تبقى دون منافسة قوية لفترة طويلة. على وجه الخصوص، يُتوقع أن تلعب جوجل وميتا دورًا كبيرًا في تغيير المشهد التنافسي؛ إذ تمتلك كلا الشركتان أبرز الخبراء في مجال التعلم المعزز، بالإضافة إلى الموارد الضخمة اللازمة لتطوير نماذج متقدمة.

وبالفعل كشفت Google DeepMind مؤخرًا عن نظامين جديدين للذكاء الاصطناعي AlphaProof وAlphaGeometry 2، وهما مصممان للاستنتاج الرياضي. تدعي جوجل أن النظامين تمكنا من حل أربع من أصل ست مسائل من الأولمبياد الدولي للرياضيات.
هل يمكن أن تقع النماذج الجديدة في فخ الاستدراج
تحدثت OpenAI بشكلٍ كبير بشأن سلامة سلسلة OpenAI o1 وأكدت أن إجراءات السلامة هي جزء من تطوير الذكاء الاصطناعي؛ إذ توصلت الشركة إلى نهج جديد يُدرب النماذج على الاستفادة من قدرتها على التفكير لحثها على الالتزام بإشارادات السلامة (safety and alignment guidelines).
كانت إحدى المشاكل الخطيرة التي تواجه GPT – 4o خلال الفترة الماضية؛ هي قدرة بعض المحترفين على كسر قيود السلامة التي بُرمجت داخل النموذج والتي تُعرف بـ «الهروب من السجن – jailbreaking». وفي آخر حادث؛ تمكن أحد المُخترقين من كسر قيود GPT – 4o ليخبر المُخترق عن كيفية صنع قنبلة! وقال خبير في المتفجرات، بعد مراجعة رد النموذج، إن التعليمات الناتجة يمكن استخدامها لصنع منتج قابل للتفجير وكانت حساسة جدًا لدرجة أنه من الخطر نشرها.

إحدى الطرق التي نقيس بها السلامة هي اختبار مدى التزام النموذج بقواعد السلامة الخاصة به إذا حاول المستخدم تجاوزها (المعروف بـ "الهروب من السجن" أو "jailbreaking"). في أحد أصعب اختبارات الهروب من السجن لدينا، حصل نموذج GPT-4o على درجة 22 (على مقياس من 0 إلى 100)، بينما حصل نموذج o1-preview على درجة 84. يمكنك قراءة المزيد حول هذا الموضوع في بطاقة النظام ومنشورنا البحثي.
وصنفت الشركة مستويات الأمان في إنتاج محتوى ضار، وصُنِف o1 – preview على أنه «متوسط» من ناحية التقييم العام للمخاطر كما أنه آمن للإطلاق والاستخدام العام نظرًا إلى أنه محدود لأنه لا يقدم طرقًا جديدة أو متقدمة بشكلٍ خاص لتحقيق أشياء غير ممكنة بالفعل بالوسائل المتوفرة، وبالتالي يُعتبر استخدامه آمنًا في هذا السياق لأنه لا يقدم تهديدًا إضافيًا.
وحصل o1 – preview على مع مستوى خطر «منخفض» في الأمن السيبراني واستقلالية النموذج، ومستوى خطر «متوسط» في مجالات الأسلحة الكيميائية والبيولوجية والإشعاعية والنووية (CBRN) والإقناع. تضمنت السلسلة النموذج الأساسي o1-preview بالإضافة إلى نسخة o1-mini المُصغرة والأقل تكلفة بنسبة 80% والأكثر سرعة أيضًا. ستوفر الشركة السلسلة الجديدة لمشتركي ChatGPT Plus. وتخطط لتقديم نسخة o1-mini بشكلٍ مجاني.
تتخذ OpenAI ذلك الإجراء بجدية بالغة مع هذا النموذج؛ فعند إصدار النموذج أثير فضول المخترقين والمطورين لمحاولة الكشف عن سلسلة التفكير للنموذج من خلال «كسر قيود السلامة أو حقن الأوامر - jailbreaking or prompt injection». عندما حاول رايلي جودسايد، مهندس الأوامر في Scale AI، اختراق محاولة الكشف عن سلسلة التفكير، تلقى بريدًا إلكترونيًا تحذيريًا من OpenAI إذا استخدم مصطلح «سلسلة الاستدلال - reasoning trace» مجددًا في حديثه مع o1.
لكن ماذا عن سلامتنا إذًا؟
عند تأسيسها، كانت إدارة شركة OpenAI مختلفة جذريًا عن نسختها الحالية في عام 2024. في البداية، أولت الشركة اهتمامًا كبيرًا لسلامة الذكاء الاصطناعي، ساعية لحماية البشرية من مخاطره المحتملة. كجزء من هذا الالتزام، أسست الشركة فريق التوجيه الفائق (Superalignment). غير أن هذا التركيز تغير مع مرور الوقت؛ فمع إطلاق منتجات الشركة، بدأ الاهتمام بهذا الفريق يتضاءل. ووجد الفريق نفسه يكافح للحصول على الاستثمارات الأولية اللازمة لمواصلة أبحاثه العلمية.
أدى هذا الإهمال إلى سلسلة من التغييرات في الشركة؛ إذ استقال بعض القادة بعد خلاف مع سام ألتمان، الذي عاد لاحقًا إلى الشركة. ثم حُل فريق التوجيه الفائق بالكامل في مايو 2024؛ ما أثار تساؤلات عميقة حول التزام OpenAI بمبادئها التأسيسية. هل ما زالت الشركة مهتمة بسلامة البشرية؟ وماذا حدث للرؤية الأصلية التي أُسست عليها OpenAI كمنظمة غير ربحية مكرسة لخدمة الإنسانية؟
في محاولة لمعالجة هذه المخاوف، اضطرت OpenAI في نفس الشهر إلى تأسيس «لجنة للسلامة والأمن» ضمن مجلس إدارتها. تضم هذه اللجنة ألتمان نفسه، وسط مخاوف متزايدة من اقتراب الشركة من تطوير ذكاء اصطناعي عام؛ فكيف يمكننا التحكم في كيان أذكى منا؟ ناهيك عن السيطرة على مخاطره وعواقبه السلبية. وأُسندت إلى هذه اللجنة مسؤولية تقديم توصيات لمجلس الإدارة بأكمله بشأن القرارات الحاسمة المتعلقة بسلامة وأمن مشاريع OpenAI وعملياتها.

مع إطلاق نموذج O1-preview، أعلنت OpenAI عبر مدونتها عن تحول لجنة السلامة والأمن إلى مجموعة إشرافية «مستقلة». يترأس هذه المجموعة البروفيسور زيكو كولتر من جامعة Carnegie Mellon. تضم اللجنة أعضاء بارزين، منهم آدم دي أنجلو، الرئيس التنفيذي لشركة كورا، والجنرال المتقاعد بول ناكاسوني من الجيش الأمريكي. كما تشمل نيكول سيليجمان، نائبة الرئيس التنفيذي لشركة سوني. يُذكر أن كلاً من دي أنجلو وسيليجمان كانا من الأعضاء المؤسسين للجنة منذ بدايتها.
أوضحت OpenAI أن المجموعة الإشرافية الجديدة ستواصل تلقي تقارير دورية من فرق السلامة والأمن في الشركة، مع منحها صلاحية تأجيل الإصدارات حتى معالجة المخاوف الأمنية. لكن الملفت للنظر هو غياب ألتمان عن اللجنة، خاصة بعد أن وجه خمسة أعضاء في مجلس الشيوخ الأمريكي أسئلة حول سياسات OpenAI في رسالة موجهة إليه هذا الصيف.
رغم رحيل ألتمان، لا توجد مؤشرات على أن لجنة السلامة والأمن ستتخذ قرارات جذرية قد تؤثر بشكلٍ كبير على المسار التجاري لـ OpenAI. ويزداد هذا الشك مع تصريح ألتمان في اجتماع داخلي أخير؛ إذ أشار إلى تغيير وشيك في هيكلة الشركة غير الربحية العام المقبل. دون الخوض في التفاصيل، ألمح ألتمان إلى توجه الشركة نحو الابتعاد عن سيطرة الكيان غير الربحي.
في ظل هذا التوجه الجديد، يُثار تساؤل مهم؛ كيف ستتمكن لجنة الأمن والسلامة، التي تضم أعضاء مجلس الإدارة، من اتخاذ قرارات مسؤولة في ظل إغراء الأرباح المحتملة بعد تحول الشركة إلى الربحية؟ ومع ذلك، فإن طموح الشركة منذ تأسيسها، بدعم من ميكروسوفت، هو الوصول إلى الذكاء الاصطناعي العام. في الواقع يبدو هذا الهدف صعب التحقيق في إطار شركة غير ربحية، نظرًا للتكاليف الباهظة المطلوبة لتطوير هذه التقنية المتقدمة والمرتقبة.
في النهاية؛ بينما تمثل نماذج OpenAI o1 تقدمًا كبيرًا في قدرات الذكاء الاصطناعي، فإنها تسلط الضوء أيضًا على التحديات المستمرة في موازنة التقدم التكنولوجي مع الاعتبارات الأخلاقية والعملية. يبقى من الضروري مواصلة البحث والحوار المجتمعي حول كيفية تسخير هذه التقنيات المتقدمة بشكلٍ مسؤول ومفيد للبشرية، خاصةً أن الشركة حدث بها العديد من الانشقاقات والاستقالات بسبب موضوع السلامة. ويبقى السؤال الأكثر لمعانًا؛ هل اقتربنا من تحقيق ذكاء اصطناعي عام (AGI)؟





