
خطوة جديدة نحو التحدّي: بلاطة الحوسبة في معمارية Panther Lake
البطل يمرض ولا يموت!
تُعد هذه العبارة واحدة من أهم الدروس المُتعلّمة في عالم التقنية، التي تعلّمناها بمرور الزمن. فقد رأينا مرارًا شركات مثل AMD و Intel تتراجع وتترنّح، لتعود بعد ذلك أقوى من السابق. الأمر الذي يَضفي على عالم التقنية هذا الحماس المُتأجّج، فبطل اليوم هو ضحية الغد، والأيام دول! فبالرغم من تفوّقها لعقودٍ من الزمن بلا مُنازع في سوق المعالجات المركزية، تُصارع Intel الموت في الوقت الحالي للبقاء في حيّز المُنافسة والريادة. هذه المرّة مع معمارية Panther Lake، التي تعدنا إنتل بأنها ستُغيّر خارطة طريقتها إيجابيًّا، فهل سنرى ذلك بالفعل؟ أم أنها آمال المُنهزمين، وأنفة إنتل التي ترفض أن تظهر بمظهر الخاسر في معركة لا ينتصر فيها إلا صاحب الابتكار.
نظرة على معمارية Panther Lake
تُمثل معمارية Panther Lake القفزة التالية في خارطة طريق إنتل، ليس فقط كجيل جديد، بل كإعادة صياغة شاملة لكيفية توزيع الأحمال داخل المعالج. التركيز الأكبر في هذه المعمارية ينصب على بلاطة الحوسبة (Compute Tile) الجديدة كليًا، التي تحتضن أحدث ما توصلت إليه مختبرات إنتل، والمُتمثّلة في أنوية الأداء Cougar Cove وأنوية الكفاءة Darkmont.
في السطور القادمة، سنفّكك تفاصيل هذه البلاطة، ونناقش التحسينات المعمارية التي تهدف لتعزيز الـ IPC (التعليمات لكل نبضة)، وكيف يساهم التصميم الثلاثي الطبقات (P-Core, E-Core, LP-E Core) في تقديم أفضل سيناريو للأداء مقابل استهلاك الطاقة.

لنأخذ جولة أعمق داخل الأنوية:
تُسخّر إنتل هذه المرّة استراتيجية هجينة جديدة تحت مُسمّى Hybrid Core Strategy، اعتمدت عليها منذ الجيل الثاني عشر Alder Lake واستمرت عليها إلى أن وصلنا إلى Panther Lake. لكنها بالرغم من ذلك تطوّرت منذ جيلها الأول كثيرًا، فبين الجمع بين كفاءة استهلاك الطاقة من Lunar Lake وأداء تعدد الأنوية في Arrow Lake، تخرج لنا Panther Lake كنتيجة نهائية لهذا التزاوج.
- P-Core: تُحسّن أداء المعالجة أحادية النواة وإنتاجيتها.
- E-Cores: تُحسّن أداء المعالجة متعددة الأنوية، والعمليات المتوازية.
- LP-E Cores: تُحسّن كفاءة الطاقة.



تُحدد هذه التصريحات بوضوح استراتيجية توزيع الأعباء، حيث ركزت إنتل على تخصيص تصميم كل نواة لخدمة مهام محددة بكفاءة قصوى. وبهذا، ترتقي الشركة بالبنية الهجينة ثلاثية المستويات إلى مرحلة متقدمة، ما تراه الشركة التطبيق الأمثل لهذا المفهوم المعماري.
أنوية الأداء P-Core، خليج كوجر Couger Cove

تتبنى الواجهة الأمامية (Front-End) لنواة Cougar Cove نفس الأبعاد الهيكلية لنواة Lion Cove من حيث العرض والعمق، إلا أنها خضعت لعمليات تحسين دقيقة استهدفت رفع مستويات الأداء وتعزيز كفاءة المعالجة؛ وتتمثل أبرز مواصفاتها في:
- 8Wide Decode: فك ترميز بعرض 8 تعليمات.
- 4Wide MSROM: ذاكرة تعليمات دقيقة (Microcode ROM) بعرض 4 تعليمات.
- 12Wide µOP Cache: ذاكرة كاش التعليمات الدقيقة بعرض 12 µOP.
- 8Wide Allocate/Rename/Move Elimination/Zero IDIOM: تخصيص وتحسين التعليمات.
وبعيدًا عن كل هذا الهراء التقني الذي قد لا يعرف الكثيرين معناه، دعونا نوضّح في السطور التالية ما هي هذه التحسينات على أرض الواقع وماذا تعني.

الواجهة الأمامية (Front-End): من جلب التعليمات إلى إدارة الموارد
تعد الواجهة الأمامية للمعالج هي المسؤول الأول عن رسم مسار الأداء؛ فهي المحطة التي تبدأ بجلب تعليمات البرامج والألعاب من الذاكرة الأساسية أو الذاكرة المخبأة، وتنتهي بتهيئتها وتحويلها إلى صيغة قابلة للتنفيذ.
بعد جلب هذه التعليمات يتم فك تشفيرها لمعرفة نوع العملية الحسابية، ونوع البيانات التي سيتم التعامل معها، والمعاملات التي سيتم إجراء العملية عليها. فيتم تبسيط أو تفكيك التعليمة Instruction إلى تعليمة أبسط µOPs (اختصارًا لكلمة Micro Operation). بعد ذلك تُخزّن في ذاكرة تسمى µOPs Cache لانتظار دورها داخل خطوط التنفيذ في الواجهة الخلفية للمعالج Back End.
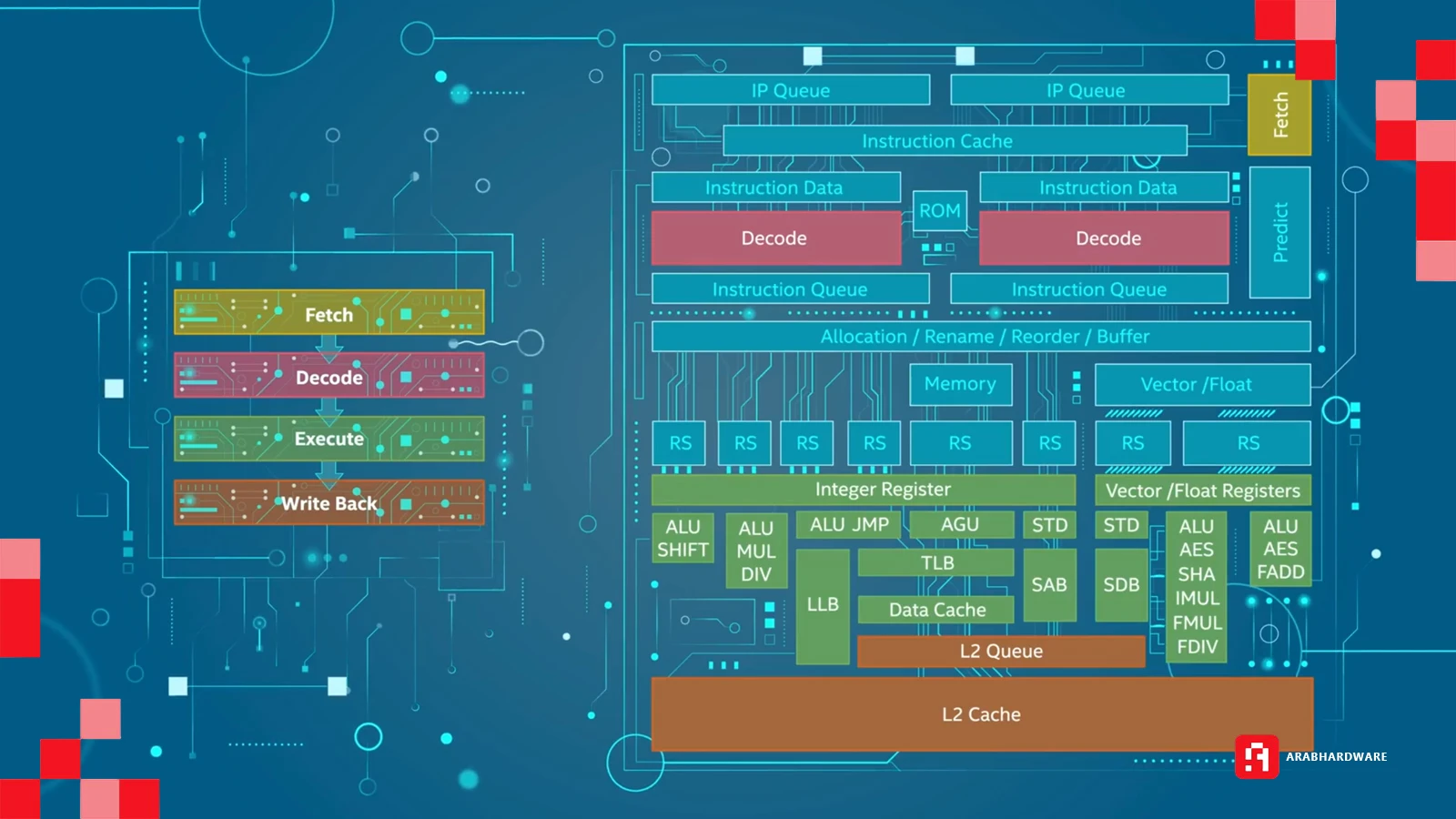
لتوضيح الأمر أكثر، دعونا نوضّح المُصطلحات التقنية التي تمّت صياغتها في معمارية Panther Lake
- وحدات فك التشفير (8Wide Decode):
تبدأ الرحلة بتحويل التعليمات (Instructions) إلى عمليات دقيقة تُعرف بـ µOPs (Micro-Operations). تأتي هذه الوحدات بعرض 8-Wide، مما يعني قدرتها على فك تشفير 8 تعليمات كاملة في الدورة الواحدة (Cycle). هذا التصميم يمنح النواة عمقًا وعرضًا يضاهي أنوية Lion Cove، مما يضمن تدفقًا غزيرًا للبيانات نحو مراحل التنفيذ التالية.
- وحدة التسلسل (4Wide MSROM):
نظراً لأن بنية x86 تعتمد على نظام التعليمات المُعقّدة (CISC)، توجد بعض الأوامر البرمجية التي تتسم بتعقيد عالٍ أو تكرار نمطي يصعب على وحدات التشفير العادية معالجته بكفاءة. هنا يأتي دور وحدة Microcode Sequencer ROM؛ وهي مخزن يحتوي على تسلسلات جاهزة للتعامل مع هذه الحالات المعقدة. تستطيع هذه الوحدة معالجة 4 تعليمات في الدورة الواحدة، مما يخفف العبء عن وحدات التشفير الرئيسية ويضمن استمرارية العمل دون اختناقات.
- ذاكرة العمليات الدقيقة (12Wide µOP Cache):
تعمل هذه الذاكرة كمخزن استراتيجي للتعليمات التي تم فك تشفيرها بالفعل. تكمن وظيفتها في تخزين الـ µOPs الجاهزة وتمريرها مباشرة إلى مرحلة تخصيص الموارد. وتمتاز هذه الوحدة بقدرة إخراج (Throughput) تصل إلى 12 تعليمة دقيقة في الدورة الواحدة، مما يوفر سرعة استجابة فائقة ويقلل من الحاجة لإعادة فك تشفير التعليمات المتكررة.
- منظومة التخصيص والتحسين (8Wide Allocate/Rename and Optimization):
تعد هذه الكتلة هي الحلقة المحورية التي تربط الواجهة الأمامية بالخلفية، وتعمل بعرض 8 تعليمات في الدورة الواحدة، وتتكون من عدة تقنيات ذكية:
- Allocate and Rename: تتولى مسؤولية حجز الموارد اللازمة في خطوط التنفيذ (مثل وحدات الحساب والمنطق ALU أو وحدات الفاصلة العائمة FPU)، بالإضافة إلى إعادة تسمية السجلات (Register Renaming) لمنع تضارب التعليمات على نفس السجل وضمان تنفيذها خارج الترتيب (Out-of-Order) بسلاسة.
- Move Elimination: تقنية ذكية تكتشف عمليات نقل البيانات غير الضرورية داخل المعالج وتقوم بإلغائها، مما يوفر دورات تنفيذ لا طائل منها ويقلل من استهلاك الطاقة.
- Zero IDIOM: ميزة متطورة قادرة على رصد الأنماط التي تؤدي لنتائج صفرية (مثل طرح مسجل من نفسه)، وتقوم بإنهاء هذه العمليات فوراً في مرحلة التسمية دون إرسالها لوحدات التنفيذ، مما يقلل من "الاعتمادات الوهمية" (False Dependencies) ويوفر موارد المعالج للمهام الأهم.
يتم توجيه مخرجات هذه العمليات بدقة إلى "ملفات السجلات" (Register Files) المناسبة، سواء كانت سجلات الأعداد الصحيحة (Integer) أو سجلات المتجهات والفاصلة العائمة (Vector and Float) لتصبح جاهزة تمامًا للتنفيذ الفعلي في الواجهة الخلفية.
نظرة أعمق على التحسينات الجوهرية داخل نواة Cougar Cove
ننتقل الآن إلى تحليل أعمق للتحسينات الجوهرية داخل نواة Cougar Cove، حيث ركزت إنتل على معالجة الاختناقات الزمنية وتحسين دقة التوقعات، مستفيدة من قفزة كثافة الترانزستورات التي وفرتها عقدة التصنيع 18A. والتي يُمكن تفنيدها في النقاط التالية:
- Memory Disambiguation "فك التباس الذاكرة".
- TLB Enhancements جدول ترجمة العنوانين الافتراضية الى عناوين حقيقية.
- Branch Prediction متنبئ الفروع.
- زيادة المستوى الثالث من الذاكرة المخبأة L3 Cache إلى 18MB بدلاً من 12MB في Lunar Lake.

فك التباس الذاكرة Memory Disambiguation
في معمارية Von Neumann هناك 4 عمليات أساسية يقوم بها المعالج:
- جلب التعليمات من الذاكرة "Fetching Data".
- فك تشفيرها كما ذكرنا سابقًا "Decode".
- تنفيذ هذه التعليمات "Execution".
- كتابة وقراءة هذه التعليمات من وإلى الذاكرة مرة أخرى
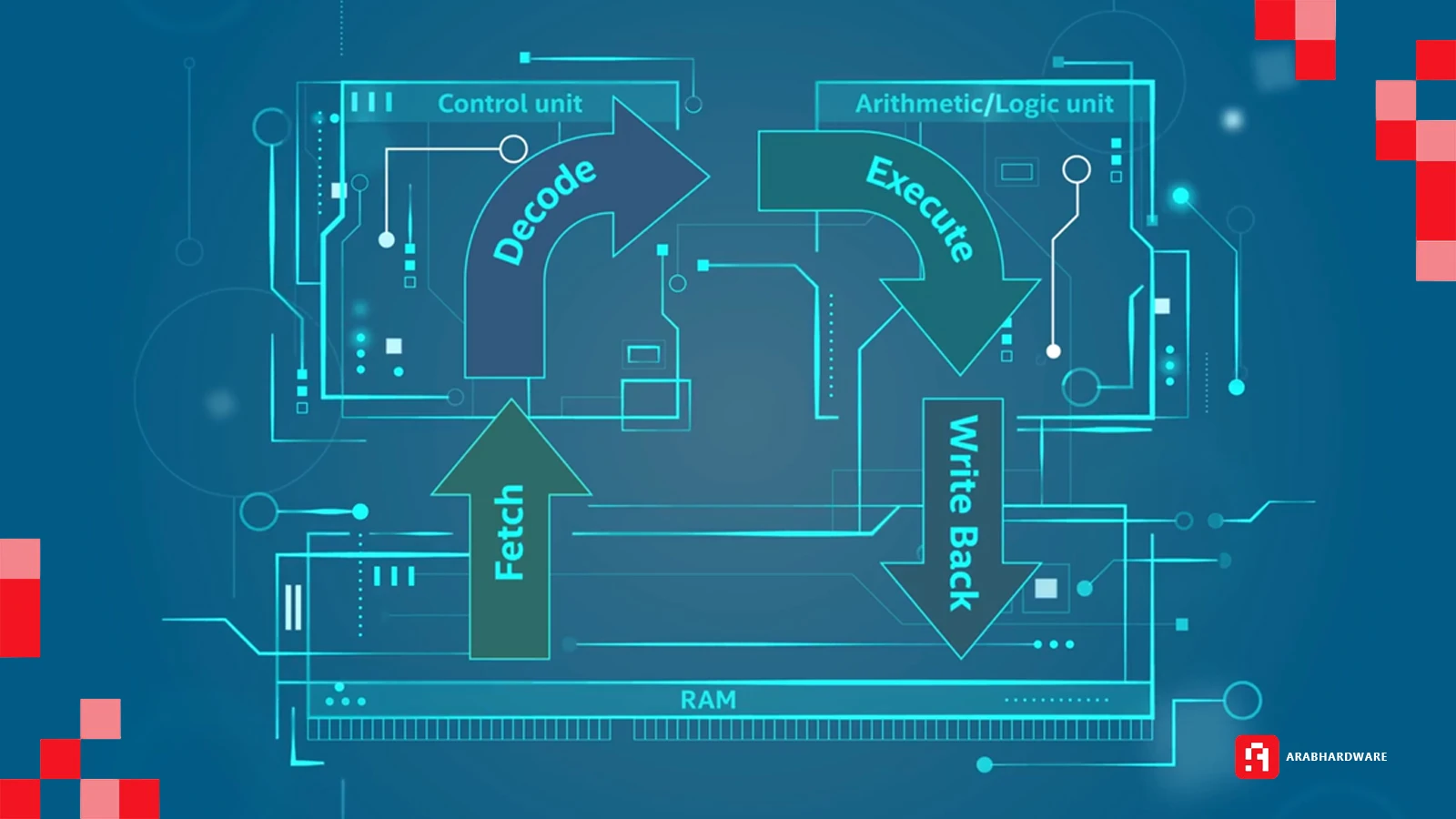
هكذا تبنى الأنظمة منذ عشرات السنين على هذه المعمارية، أثناء عملية التخزين أو التحميل قد يصادف أن عملية قراءة بيانات من الذاكرة مرتبطة بعملية تخزين دعونا نضرب مثالاً:
لنفترض أن هناك تعليمة قد نُفِّذت ونتيجتها ستخزن في سجل معين، في نفس الوقت هناك عملية نتيجتها متوقفة على التعليمة الأولى مثل:
- Store (A) = 10.
- Load R1 = (A).
عملية قراءة السجل R1 مرتبطة بعملية تخزين القيمة 10 في A "أي هناك اعتماديه قراءة بعد كتابة" بالتالي لا يمكن قراءة البيانات إلا إذا تمت عملية تخزينها في البداية. المشكلة تظهر عندما تأتي العمليتين خلف بعضهم، والمعالج غير متأكد إذا كانوا مرتبطين بنفس العنوان أم لا (العنوان هُنا هو مكان تخزين البيانات). هنا تكمن مشكلة الغموض، خصوصًا في التنفيذ خارج الترتيب، فالمعالج بين أمرين:
- إما أن يقوم بتنفيذ عملية القراءة من الذاكرة، وإذا لم يكونوا مرتبطين تكون عملية القراءة صحيحة.
- أو أن يكونوا مرتبطين، وهنا عليه الانتظار حتى لا يقرأ بيانات قديمة، وبالتالي يحدث بعض التأخير في التنفيذ.
لحل المشكلة، حسّنت شركة Intel قدرتها على التنبؤ بترابط عملية القراءة والكتابة، من خلال وحدة Memory Dependence Predictor، التي تُسجّل العمليات المتشابهة وتراقبها. لتتعلم عن العمليات المرتبطة والغير مرتبطة عن طريق خوارزمية ذكية، ومن ثم استخدام تلك المعلومة لتنفيذ عملية التحميل في التوقيت الصحيح. وعندما يتم ذلك بدقة، نحصل على زيادة في عدد التعليمات المنفذة في كل دورة (IPC) وبالتالي تحسن في الأداء العام.
جدول ترجمة العناوين TLB Enhancement
يُعدّ TLB اختصارًا لـ Translation Lookaside Buffer، وهو ذاكرة صغيرة وسريعة داخل المعالج تُستخدم لتخزين أحدث عمليات ترجمة العناوين من العناوين الافتراضية (Virtual Addresses) إلى العناوين الفيزيائية (Physical Addresses)، وهي عملية تقوم بها وحدة إدارة الذاكرة MMU (Memory Management Unit).
من منظور المبرمج، يتم التعامل مع العناوين والسجلات بطريقة مجرّدة (افتراضية) دون معرفة مواقعها الفعلية داخل المعالج، حيث تتولى وحدات من المعمارية داخل المعالج، بما في ذلك آليات مثل إعادة تسمية السجلات (Register Renaming)، تحويل السجلات المنطقية إلى سجلات فعلية.
يساعد الـ TLB على تسريع الوصول إلى الذاكرة عبر تخزين نتائج الترجمات المستخدمة حديثًا، مما يقلّل الحاجة إلى الرجوع المتكرر إلى جداول الصفحات في الذاكرة. وقد تم زيادة سعة هذه الذاكرة بنسبة تقارب 50% بفضل استخدام عقدة التصنيع الحديثة Intel 18A، التي وفّرت كثافة أعلى للترانزستورات لكل ملليمتر مربع (mm²).
متنبئ الفروع Branch Prediction
تم تحسين الخوارزمية المستخدمة في التنبؤات بالفروع فأصبحت أكثر ذكاء ودقة، أيضاً التغيير المهم هو مستوى التنبؤات والسِّعة Multi-Level Predictor أصبح لا يعتمد على مستوى واحد من التاريخ، بل يستطيع تتبع التكرارات قصيرة المدى مثل 4 أو 5 تكرارات أو حتى بعيدة المدى 100 تكرار أو أكثر، يستطيع تعلم النمطين معاً، متنبئ الفروع يحدد جزء كبير من أداء المعمارية.
ننتقل الآن إلى أنوية الكفاءة E-Cores التي حصلت على بعض التغييرات المثيرة للاهتمام، نتناول في البداية أهم التحسينات، ثانياً نستعرض الوحدات داخل النواة كما فعلنا مع Couger Cove.
الجبل المظلم Darkmont، نواة الكفاءة E-Core

وفقًا للبيانات الصادرة عن إنتل، تعكس بنية Panther Lake قفزة نوعية في مؤشرات الأداء والكفاءة، مدفوعةً بالتحسينات المعمارية لـ 'أنوية الكفاءة' والاستفادة القصوى من عقدة التصنيع 18A.
وتتجلى هذه النتائج في تحقيق زيادة بنسبة 10% في أداء الخيط الواحد (ST) مقارنة بمعماريتي Arrow and Lunar Lake عند نفس استهلاك الطاقة، مع تعزيز أداء تعدد الخيوط (MT) بنسبة 50% مقارنة بـ Lunar Lake.
أما على صعيد كفاءة الطاقة، فقد سجلت المعمارية تحسناً بنسبة 40% في الأداء مقابل كل واط مقارنة بـ Arrow Lake، فضلاً عن خفض استهلاك الطاقة بنسبة 30% عند ثبات مستويات أداء تعدد الخيوط.
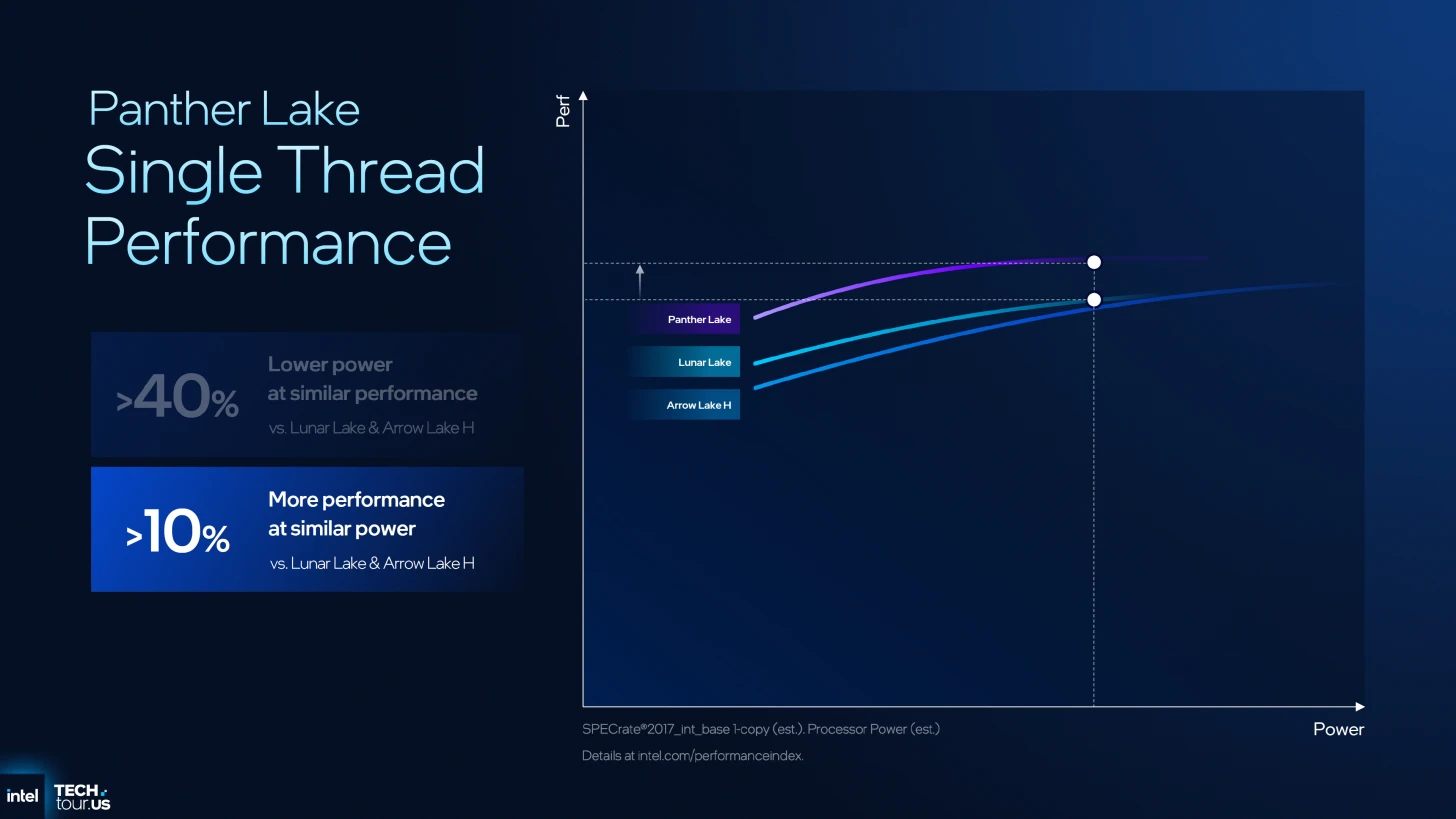
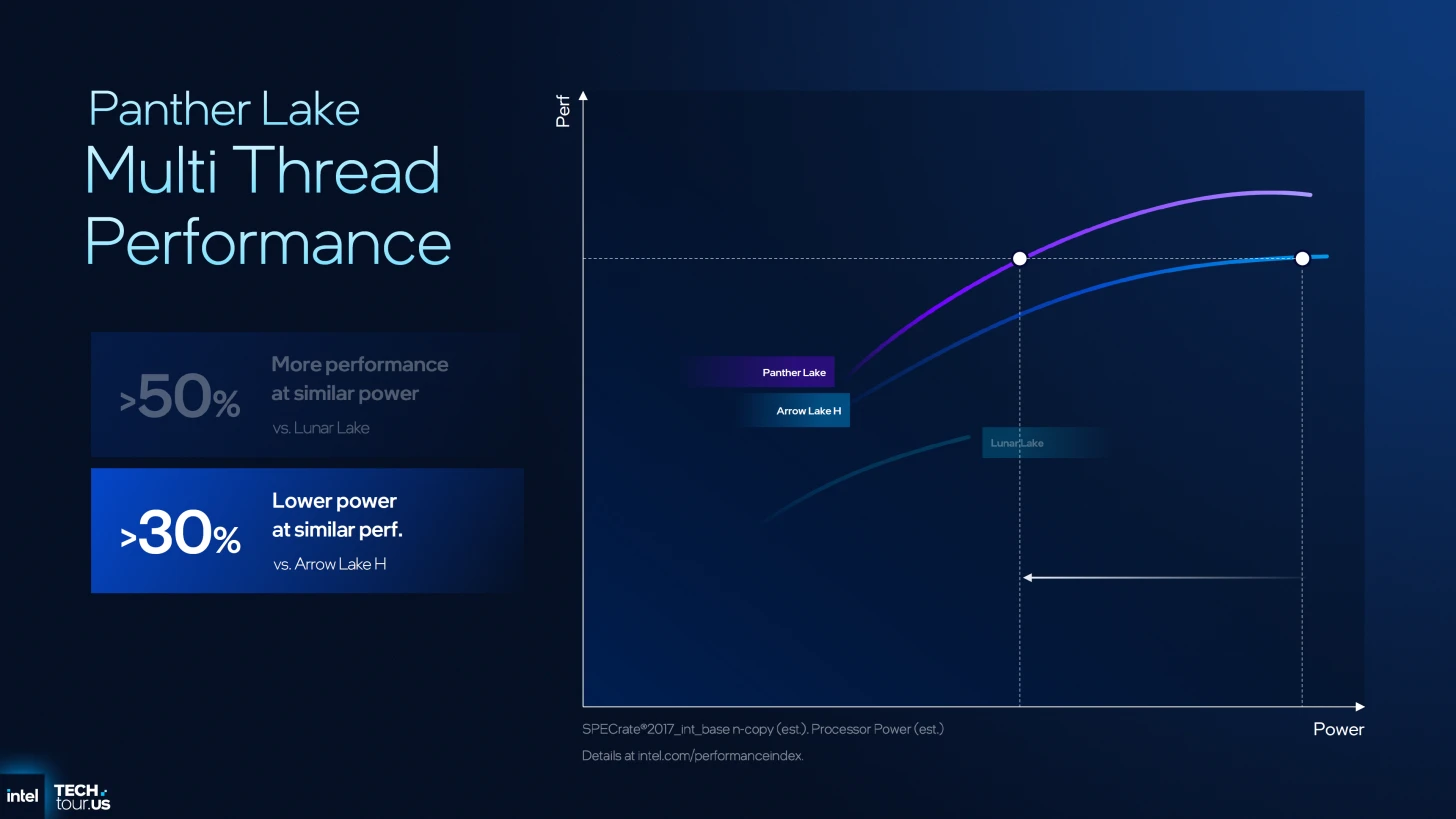
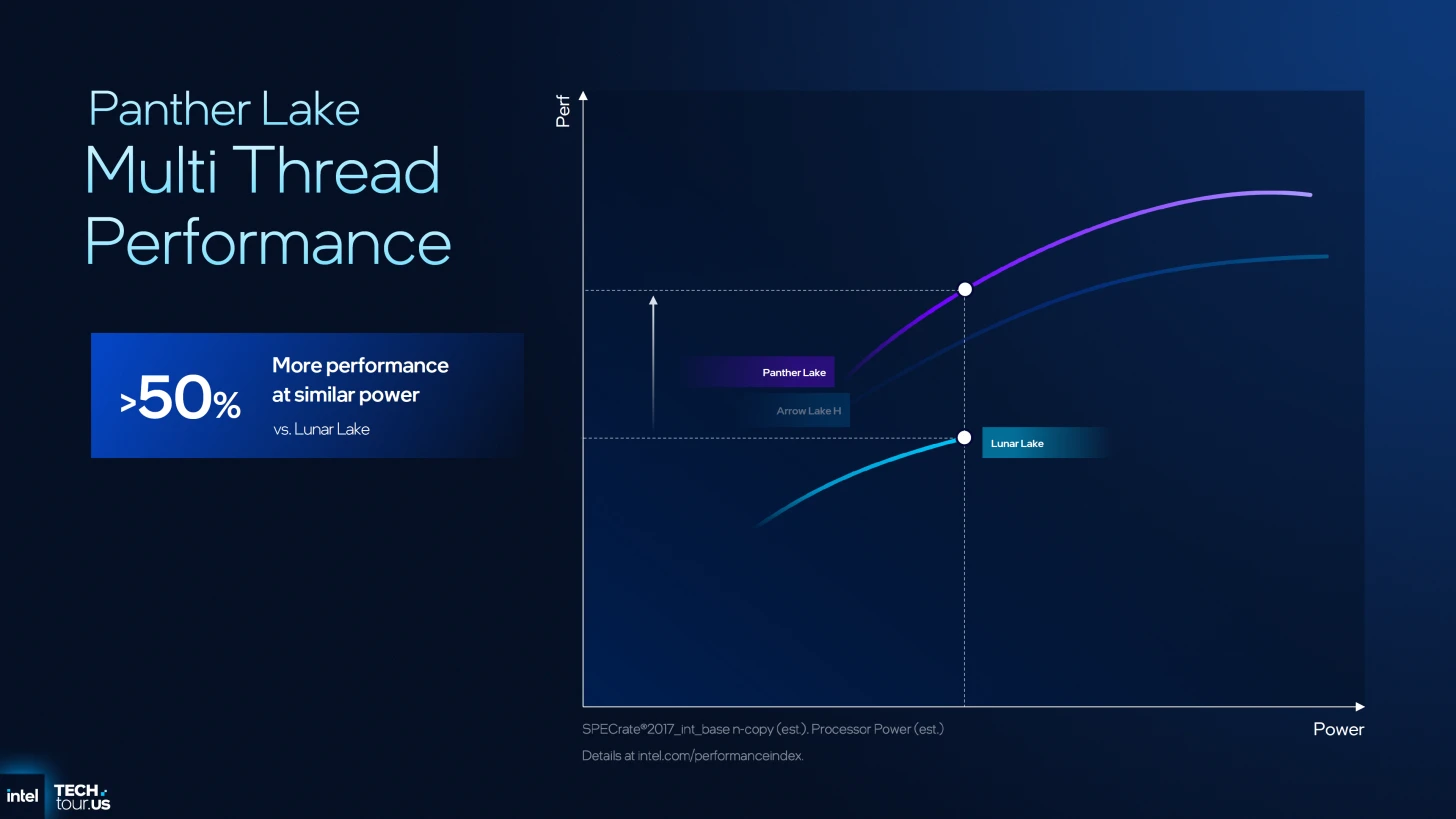
التحسينات على أنوية الكفاءة Darkmont
لا تقتصر قوة معمارية Panther Lake على أنوية الأداء فحسب، بل تمتد لتشمل أنوية الكفاءة Darkmont التي خضعت لعملية صقل معماري شاملة. لم تعد هذه الأنوية مجرد وحدات لتوفير الطاقة، بل أصبحت محركات ذكية تعتمد على تقنيات متطورة مثل Nanocode وفك التباس الذاكرة، مع تحسينات جذرية في تنبؤ الفروع وجلب البيانات. إليكم تحليل لأبرز أربعة محاور نقلت هذه الأنوية إلى مستوى جديد من الأداء.
- Branch Prediction
- Dynamic Prefetcher Controls
- Nanocode Performance
- Memory Disambiguation
متنبئ الفروع Branch Prediction:
يعتبر "متنبئ الفروع" هو البوصلة التي توجه المعالج، وبقدر دقته يتجنب المعالج هدر الوقت والطاقة. في أنوية Darkmont، قامت إنتل بنقل نفس التقنيات المتقدمة المستخدمة في أنوية الأداء Cougar Cove إلى هذه الأنوية الصغيرة. شمل ذلك زيادة ضخمة في أحجام البُنى الداخلية مثل الجداول والذاكرة المخصصة لتخزين مسارات التعليمات السابقة، بالإضافة إلى صقل خوارزميات التنبؤ لرفع درجة دقتها. والنتيجة هي تقليل حالات "الخطأ في التوقع" (Misprediction) التي تتسبب في إفراغ أنبوب التنفيذ (Pipeline Flush) وإعادة العمل من جديد.
التحكم الديناميكي في الجلب المسبق Dynamic Prefetcher Controls:
وحدة جلب التعليمات من الذاكرة أصبحت مرنة أكثر ومتكيفة مع مختلف الأحمال، هذه التحسينات تهدف إلى كفاءة استهلاك الطاقة أكثر.
التحكم في أدق تفاصيل العتاد Nanocode Performance:
أنوية Darkmont هي الوحيدة التي تستخدم Nanocode في كل معماريات إنتل، يُعد من أهم التحسينات المعمارية على هذه الأنوية، دعونا نتطرق إلى شرح بسيط وسريع عن الـ Microcode ثم نبين ما هو ال Nanocode والفرق بينهم:
مجموعة تعليمات x86 هي تعليمات معقدة ومتغيرة الطول تنتمي إلى بُنى CISC المعقدة، طريقة تنفيذ هذه التعليمات المعقدة ومتغيرة الطول تحتاج إلى فك وترجمة وتحويل داخل المعالج إلى تعليمات دقيقة سهلة التنفيذ على العتاد وهي وظيفة وحدات فك التشفير التي ذكرناها سابقاً Decoders، الـ Microcode هو دليل تشغيل داخلي أو كتالوج خطوات التنفيذ المنطقية على الوحدات داخل المعالج، اعتقد أنك بدأت في استيعاب وتخيل ما هو الـ Nanocode ، من الاسم هو مستوى أدنى وأعمق من الـ Microcode يعطي تحكم أفضل في تنفيذ التعليمات فهو لديه القدرة على التحكم في الإشارات الفيزيائية، التوقيتات بين المدخلات والمخرجات، فتح وغلق إشارات التحكم والمسارات الداخلية بين الترانزستورات، فهما يعملان معاً لوصف تسلسل الإشارات وخطوات التنفيذ، ولكن ليس كل التعليمات تحتاج إلى Nanocode لتنفيذها، فهو يُستخدم في حالات معينة ويعتبر من الأسرار التجارية حتى في دراسات الهندسة العكسية من النادر معرفة تفاصيله بدقة.
باختصار هو الطبقة الأدنى من الكود داخل نواة معالجات إنتل، تتحكم مباشرة في تنفيذ التعليمات على مستوى العتاد، وتُستخدم لتحقيق المرونة، التوافق، والتحكم الدقيق في الأداء.
فك التباس الذاكرة Memory Disambiguation:
في خطوة تعكس وحدة الهدف المعماري، تمت مشاركة المكتسبات البحثية لفريقي هندسة الأداء والكفاءة، لتقديم استجابة هندسية موحدة للتحديات البنيوية التي تواجه الأنوية بمختلف فئاتها.
نظرة داخل نواة الكفاءة من حيث بنية النواة وعمقها

الواجهة الأمامية للنواة تأتي كالآتي:
- 96KB L1 Cache (64KB Instruction Cache + 32KB Data Cache) Per Core
- 9Wide Decode
- 8Wide Allocate/Rename
- 4MB Shared L2 Cache
تستند بنية النواة الجديدة إلى تحسينات جوهرية في تدفق البيانات، حيث تم تعزيز الذاكرة المخبأة من المستوى الأول (L1 Cache) لتصل إلى 96KB لكل نواة (مقسمة إلى 64KB للتعليمات و 32KB للبيانات)، مع ذاكرة مخبأة مشتركة للمستوى الثاني (L2 Cache) بسعة 4MB.
وحدة فك التشفير (9Wide Decode):
اعتمدت إنتل تصميماً متطوراً لوحدة فك تشفير التعليمات بعرض 9-Wide، مُقسمة إلى ثلاثة تجمعات (Clusters). يعمل كل تجمع بعرض 3 تعليمات، مما يتيح فك تشفير وتحويل التعليمات إلى عمليات دقيقة (µOPs) بكفاءة عالية في الدورة الواحدة. هذا التصميم يمنح النواة عمقاً وعرضاً يضاهي معمارية Skylake، بينما يتفوق بشكل ملحوظ على نويات Crestmont السابقة في معمارية Meteor Lake.
تخصيص الموارد وإعادة التسمية (8Wide Allocate/Rename):
تأتي وحدات تخصيص الموارد للواجهة الخلفية (Back-end) وإعادة تسمية السجلات بعرض 8 تعليمات في الدورة الواحدة. تهدف هذه الوحدات إلى إدارة الموارد بدقة ومنع تضارب البيانات، مما يضمن تدفقاً سلسلاً للتعليمات نحو مراحل التنفيذ.
مصفوفة انتظار العمليات الدقيقة (µOP Queue):
شهدت صفوف انتظار العمليات الدقيقة توسعاً في السعة من 64 إلى 96 إدخالاً (Entries). هذا التوسع يعزز من قدرة النواة على استيعاب كم أكبر من التعليمات الجاهزة، مما يضمن تغذية مستمرة للواجهة الخلفية ويقلل بفعالية من فترات الخمول (Stalls) داخل المعالج.
نافذة التنفيذ خارج الترتيب (Out-Of-Order Execution Window):
لتعزيز كفاءة المعالجة المتوازية، تمت توسعة نافذة التنفيذ خارج الترتيب لتصل إلى 416 إدخالاً. تتيح هذه التوسعة للمعالج مرونة أكبر في إعادة ترتيب وتنفيذ عدد ضخم من التعليمات بشكل غير تسلسلي، وهو ما ينعكس بشكل مباشر وجوهري على تحسين أداء تعدد الخيوط (Multi-threading performance).
منافذ التنفيذ (Execution Ports):
حافظت الواجهة الخلفية على استقرار التصميم الموروث من معمارية Lunar Lake، وذلك عبر الاعتماد على 26 منفذاً (Ports). تعمل هذه المنافذ كقنوات اتصال حيوية لنقل التعليمات بين الواجهة الأمامية والخلفية، مما يضمن الحفاظ على معدل نقل بيانات (Throughput) مرتفع ومستقر.
ننتقل الآن إلى أحد أكثر الجوانب إثارة للاهتمام في تصميم نواة Darkmont، وهو التعديل الجوهري في وحدات القراءة والكتابة من وإلى الذاكرة (Load/Store Ports).
في العرف الهندسي للمعماريات الحاسوبية، جرت العادة أن تتطابق وحدات التحميل (Load) مع وحدات التخزين (Store) في العدد لضمان التوازن مقابل وحدة توليد عناوين (AGU) لكل منفذ تحميل ومنفذ تخزين. ومع ذلك، تأتي نواة Darkmont لتتبني نهجاً مغايراً عبر تخصيص 3 منافذ للتحميل (Load Ports) مع وحدتي توليد عناوين فقط! مقابل 4 منافذ للتخزين (Store Ports) مع 4 وحدات توليد عناوين.
هذا التباين الرقمي غير المعتاد يطرح تساؤلات تقنية عميقة حول الفلسفة التي اتبعتها إنتل في إدارة تدفق البيانات. ولتوضيح الأسباب الكامنة وراء هذا التصميم الفريد، نقتبس الإيضاح من المهندس المسؤول عن قيادة فريق هندسة الأنوية في إنتل، حيث صرّح قائلًا:
" حسنًا، لنقسّم الأمر إلى جزأين: توليد العناوين مقابل التنفيذ.
عندما يكون لديك ثلاث منافذ لتنفيذ عمليات التحميل (load execution ports)، فأنت تحتاج إلى ثلاث وحدات لتوليد عناوين التحميل (load address generators). وهذا منطقي.
أما في جانب التخزين (store side)، لدينا أربع وحدات لتوليد عناوين التخزين (store address generation units)، ولكننا لا نستطيع في الواقع إلا تنفيذ عمليتي تخزين فقط في ذاكرة البيانات (data cache) في كل دورة.إذن هناك بعض عدم التماثل في جانب التخزين. وسؤالك في محله: لماذا لدينا وحدات أكثر لتوليد عناوين التخزين (AGU) من عدد منافذ التخزين الفعلية؟
الجواب هو أن هناك تعارضات (hazards) بين عمليات التحميل (loads) وعمليات التخزين (stores) ففي بعض الأحيان، تتعطل عمليات التحميل بسبب أننا لا نعرف عنوان التخزين بعد، لأن التنفيذ يتم خارج الترتيب (out-of-order)لذلك، بزيادة عرض النطاق (bandwidth) لتوليد عناوين التخزين، نقلل من زمن التأخير اللازم لحل هذه التعارضات.
بمعنى آخر، نحصل على أداء أفضل لأننا نبذل مزيدًا من الجهد والوقت في توليد عناوين التخزين، مما يمنع عمليات التحميل من التوقف أو الانتظار."
يرتبط هذا التحسين الهيكلي أيضاً بشكل وثيق بمفهوم "فك التباس الذاكرة" (Memory Disambiguation)؛ وهي تقنية حيوية تتيح للمعالج التنبؤ بوجود تعارضات بين عمليات التحميل والتخزين قبل حدوثها، مما يمنع التوقفات غير الضرورية في أنبوب التنفيذ. وبالرغم من التعقيد المعماري المبهر الذي تقدمه إنتل في وحداتها الأساسية، إلا أن هذه القوة العتادية تظل كامنة ما لم يتم استغلالها عبر منظومة برمجية متطورة.
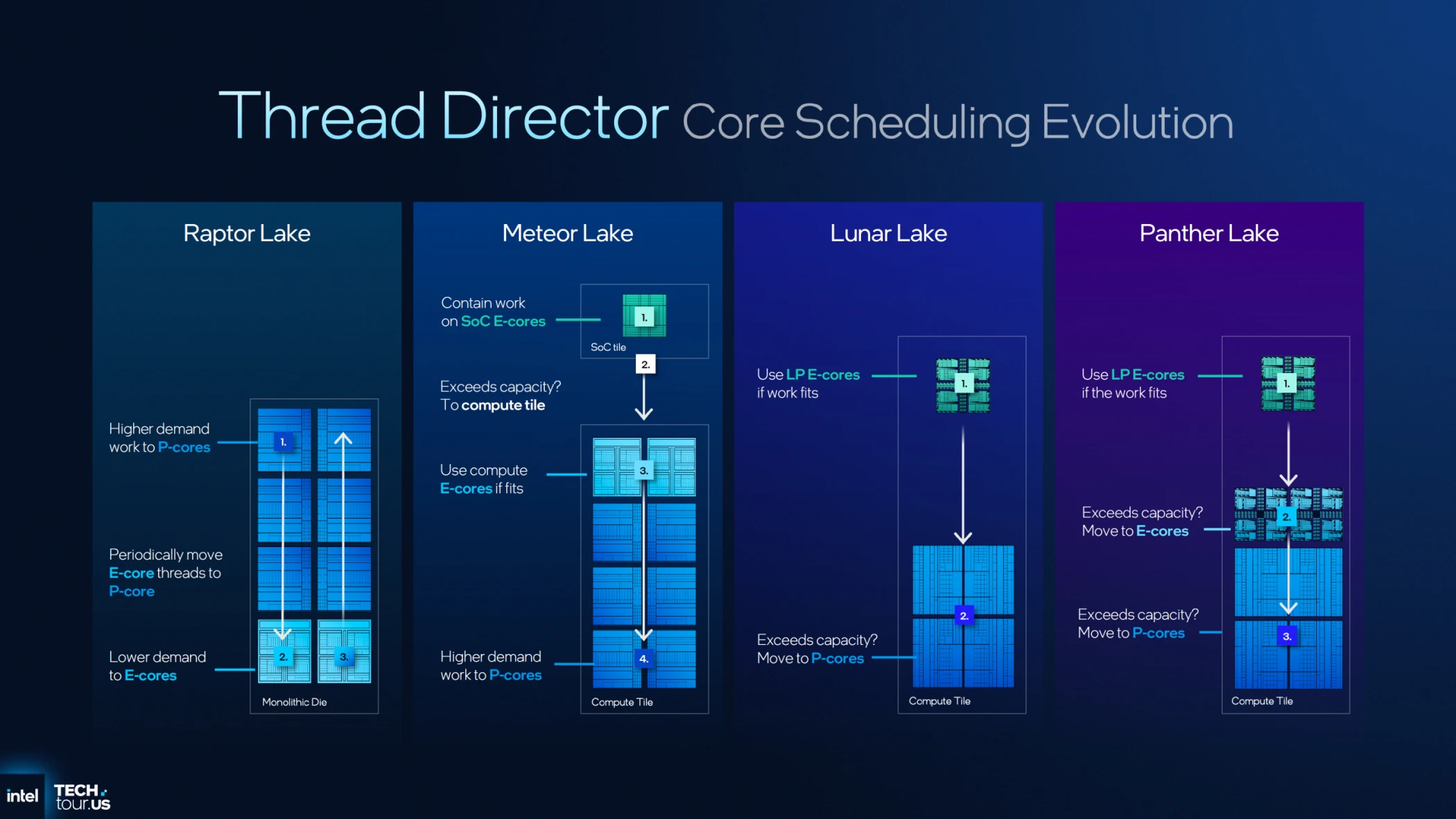
هنا يأتي الدور المحوري للتنسيق بين نظام التشغيل OS Scheduler والبرمجيات، والأهم من ذلك، النسخة المطورة من وحدة Intel Thread Director. لقد خضعت هذه الوحدة لتحسينات جوهرية لتتوافق مع استراتيجية إنتل الجديدة في توزيع الأنوية، حيث تعمل كـ "مايسترو" تقني يمتلك رؤية لحظية لقدرات كل نواة (P, E, و LP-E).
بفضل هذه التحسينات، أصبح Thread Director أكثر ذكاءً في توجيه الأحمال المعقدة إلى النواة الأنسب بناءً على طبيعة العمل، سواء كانت تطلب أداءً فائقاً (ST) أو كفاءة في تعدد الخيوط (MT)، مما يضمن ترجمة هذه الابتكارات الهندسية إلى تجربة أداء ملموسة للمستخدم النهائي.
المايسترو الرقمي في جيله الجديد Intel Thread Director
لا تكتمل روعة التصميم الهندسي لأنوية Panther Lake دون وجود "عقل مدبر" يدير هذا التنوع المعماري بكفاءة؛ وهنا يأتي دور Intel Thread Director. إذا كانت الأنوية هي العضلات، فإن هذا المحرك هو الجهاز العصبي الذي يضمن توجيه القوة الصحيحة للمهمة الصحيحة في الوقت المثالي.
لقد قامت إنتل بتطوير نماذج التصنيف (Classification Models) الخاصة بها لتصبح أكثر ذكاءً وقدرة على قراءة المشهد البرمجي بدقة غير مسبوقة. لم يعد الأمر يقتصر على تمييز المهام "الثقيلة" من "الخفيفة" فحسب، بل امتد النطاق ليشمل تصنيفاً نوعياً للأعمال؛ حيث بات المعالج يدرك الفوارق الدقيقة بين أحمال الإنتاجية الإبداعية (مثل تحرير الفيديو والتصميم ثلاثي الأبعاد) وبين متطلبات الألعاب، أو حتى المهام الروتينية البسيطة.

بروتوكول التعاون: كيف يدار العمل بين الـ ITD ومجدول النظام (OS Scheduler)؟
تعتمد عملية توزيع الأحمال على حلقة وصل تقنية فائقة السرعة تبدأ من قلب المعالج وتنتهي عند نظام التشغيل، وتتم عبر المراحل التالية:
المراقبة والتحليل (Monitoring)
يقوم Thread Director بمراقبة كل خيط (Thread) بشكل لحظي، محللاً عدة متغيرات حيوية تشمل (طبيعة العمليات المنفذة، معدل استهلاك الطاقة، نسبة الاستخدام (Utilization)، وزمن التأخير (Latency).

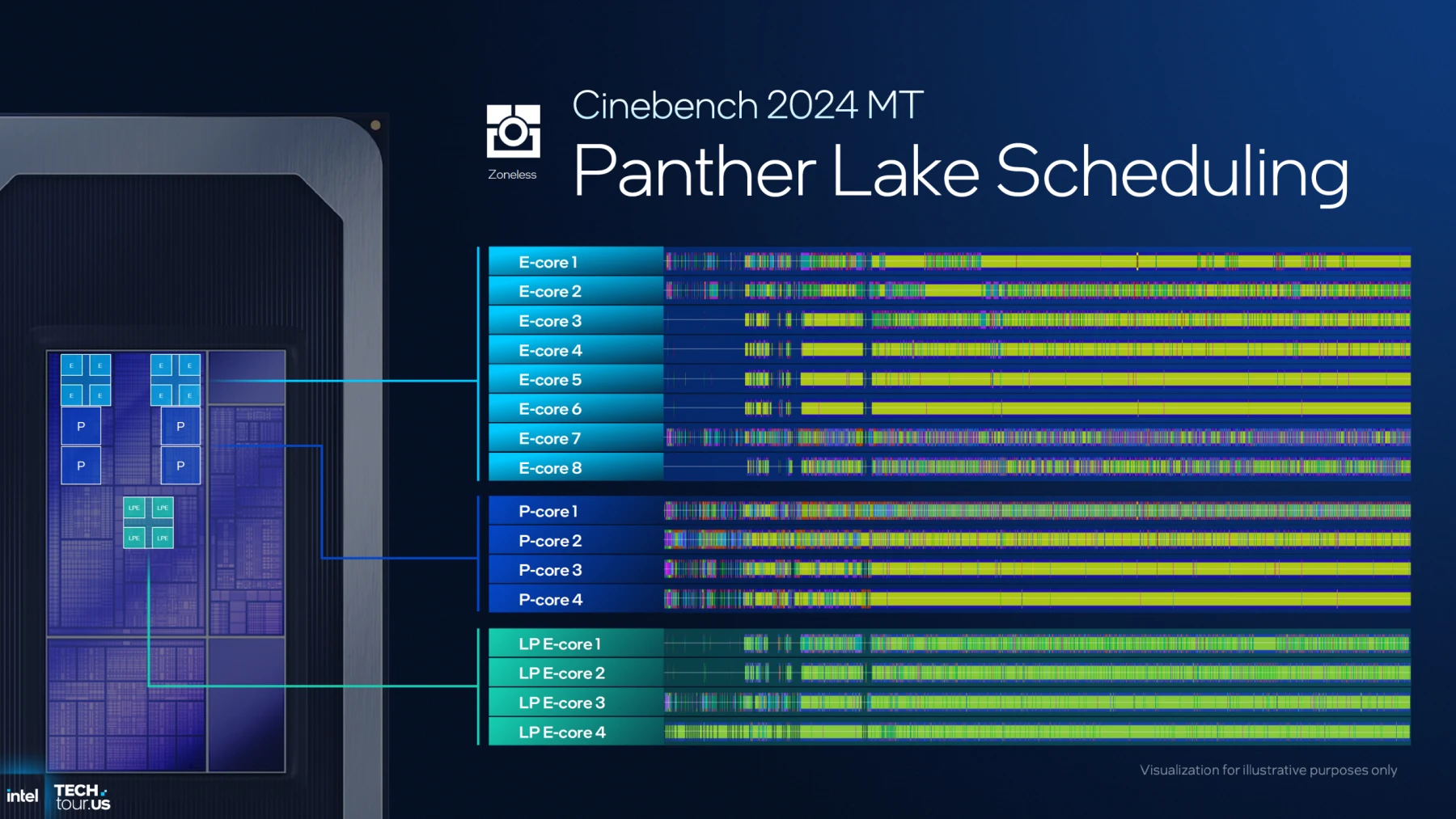
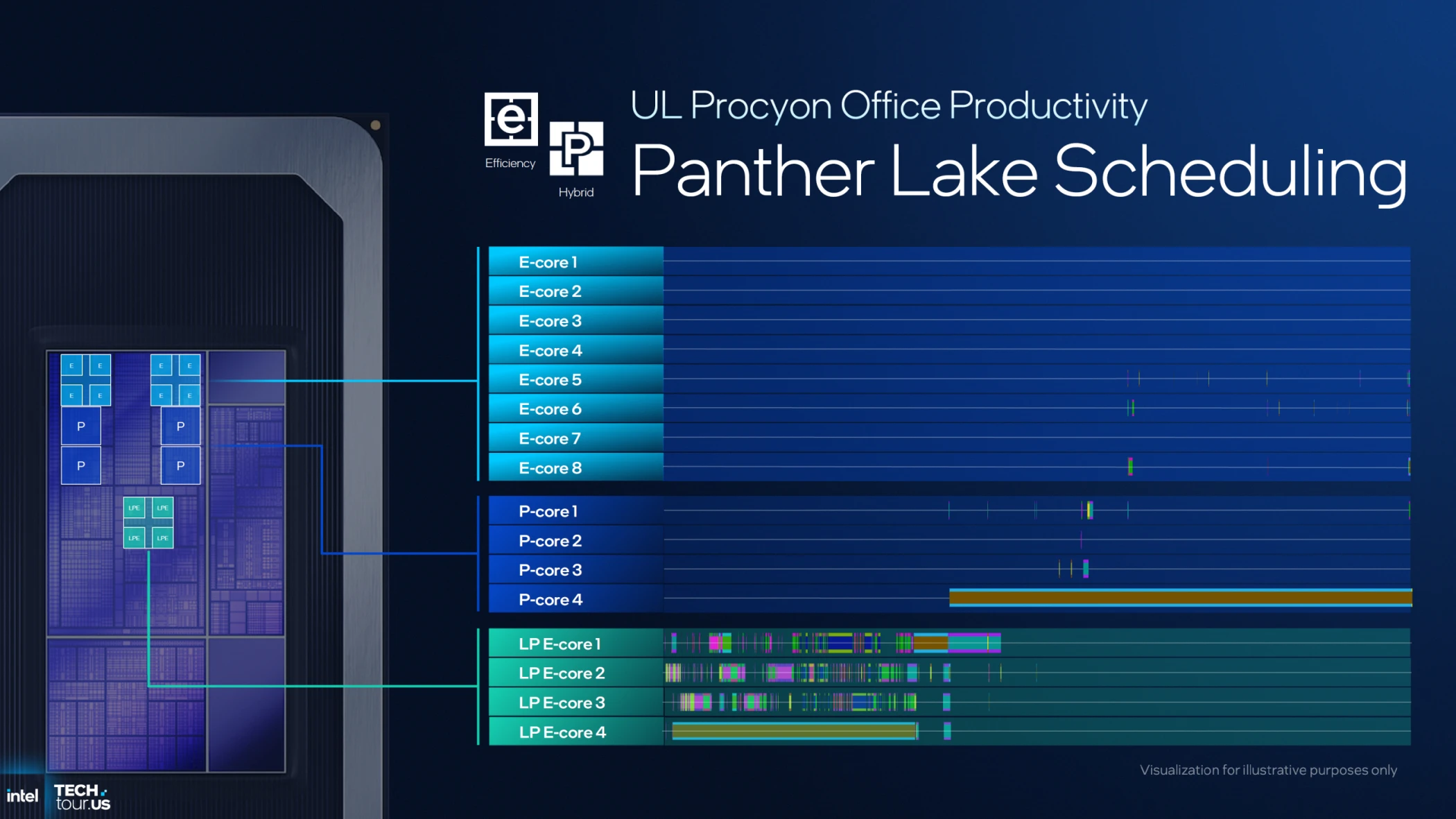



التصنيف الطبقي (Workload Classification)
بناءً على البيانات المجمعة، يتم إدراج كل مهمة تحت أحد التصنيفات الأربعة الرئيسية (Classes) وهي:
- Class 0 (Scalar): تعليمات بسيطة وعامة، يتم توجيهها فوراً لـ أنوية الكفاءة المنخفضة (LP-E Cores) للحفاظ على الطاقة.
- Class 1 (Slightly Better IPC): مهام تتطلب أداءً أعلى قليلاً ومعدل تعليمات لكل نبضة أفضل، وعادة ما تخدمها أنوية الأداء (P-Cores) أو أنوية الكفاءة (E-Cores) حسب الحالة.
- Class 2 (AI/CPU-Based): تعليمات معقدة (مثل معالجة الذكاء الاصطناعي) تتطلب ترددات عالية وقوة معالجة مكثفة.
- Class 3 (Non-Scalable Workloads): مهام ثقيلة لا تستجيب لتعدد الأنوية (مثل الألعاب وبرمجيات Legacy القديمة)، وهنا تبرز قوة أنوية الأداء بتردداتها القصوى.
جدول التغذية (Feedback Table)
بعد تحديد التصنيف المناسب، يقوم Thread Director بتدوين هذه التوصيات في "جدول تغذية" (Feedback Table). هذا الجدول يعمل كمرجع تقني حي، يقوم مجدول نظام التشغيل (OS Scheduler) بقراءته دورياً لاتخاذ القرار النهائي بتوجيه كل خيط إلى النواة الأنسب له.

نصل الآن إلى مسك الختام في تحليلنا المعماري، وهو شريان الحياة لأي معالج، منظومة الذاكرة والمستويات المخبأة (Cache and Memory Subsystem).
في Panther Lake، لم تكتفِ إنتل بزيادة السعات الرقمية، بل أعادت هندسة المسارات لتقليل زمن الوصول إلى أدنى مستوياته.
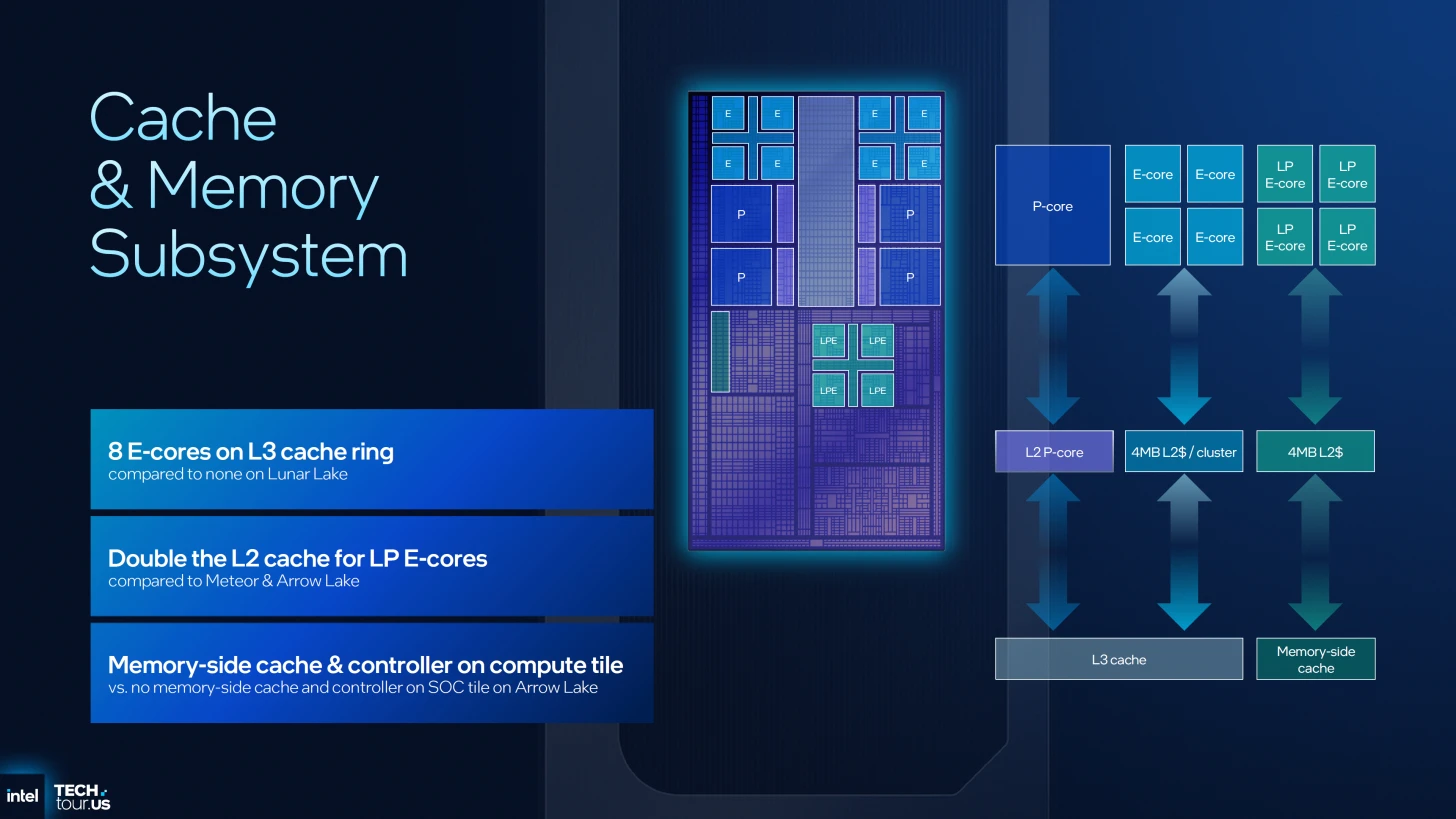
منظومة الذاكرة: هندسة المسارات وتقليص زمن الاستجابة
تعتمد معمارية Panther Lake استراتيجية هرمية ذكية لتوزيع الذاكرة المخبأة، تهدف في مقامها الأول إلى رفع معدل تدفق البيانات (Throughput) وتقليل الفجوة الزمنية بين طلب المعلومة ومعالجتها.
أنوية الأداء (Cougar Cove P-Cores): سرعة الاستجابة القصوى
- المستوى الأول (L1 Cache): تأتي بسعة 256KB، موزعة بذكاء بين 192KB (L1D) و 48KB (L0D). هذا التقسيم الفرعي هو مفتاح السرعة، حيث يعمل الـ L0D كطبقة فائقة السرعة لتقليل زمن الوصول في أنابيب التحميل والتخزين (Load/Store Pipeline).
- المستوى الثاني (L2 Cache): شهدت قفزة نوعية لتصل إلى 3MB لكل نواة، بزيادة قدرها 1MB عن معمارية Lion Cove السابقة، مما يوفر مساحة أكبر للبيانات القريبة من أنبوب التنفيذ.
أنوية الكفاءة (Darkmont E-Cores): التشارك الذكي
على عكس أنوية الأداء، تعتمد أنوية الكفاءة نظام التجمعات (Clusters)، حيث يتشارك كل تجمع في الموارد من المستوى الثاني من الذاكرة المخبأة L2 Cache:
- المستوى الأول (L1 Cache): بسعة 96KB، مقسمة إلى 32KB (L0D) المخصصة حصرياً لبيانات المتغيرات الحسابية، و 64KB (L1I) المخصصة لتعليمات البرامج.
- المستوى الثاني (L2 Cache): تم رفع سعة الـ Cluster الواحد لتصل إلى 4MB، مما يعزز أداء تعدد المهام داخل التجمع الواحد.
المستوى الثالث (L3 Cache): قلب الترابط المعماري
شهد المستوى الثالث التحسين الأكبر في هذه المعمارية، حيث ارتفعت السعة بنسبة 50% لتصل إلى 18MB (مقارنة بـ 12MB في الجيل السابق).
- المرونة والترابط: لم تقتصر الزيادة على الحجم، بل شملت تحسين درجة الترابط (Associativity) وتسريع المسارات الداخلية، مما يتيح تخزين عناوين البيانات في مواقع متعددة وبسرعة استجابة أعلى.
- تكامل الوحدات: أصبحت بلاطة الرسوميات (GPU Tile) قادرة على الوصول المباشر إلى الـ L3 Cache، وهو ما يقلل الاعتماد على الذاكرة العشوائية (RAM) ويقلص زمن الوصول بشكل يخدم تطبيقات الإنتاجية والألعاب.

ثورة الـ LPE-Cores وذاكرة الشريحة الشاملة
في تحول استراتيجي، قامت إنتل بنقل أنوية الكفاءة منخفضة الطاقة (LPE-Cores) لتصبح داخل البلاطة الحوسبية (Compute Tile) مباشرة، مع مضاعفة الذاكرة المخبئية للمستوى الثاني الخاصة بها لتصل إلى 4MB.
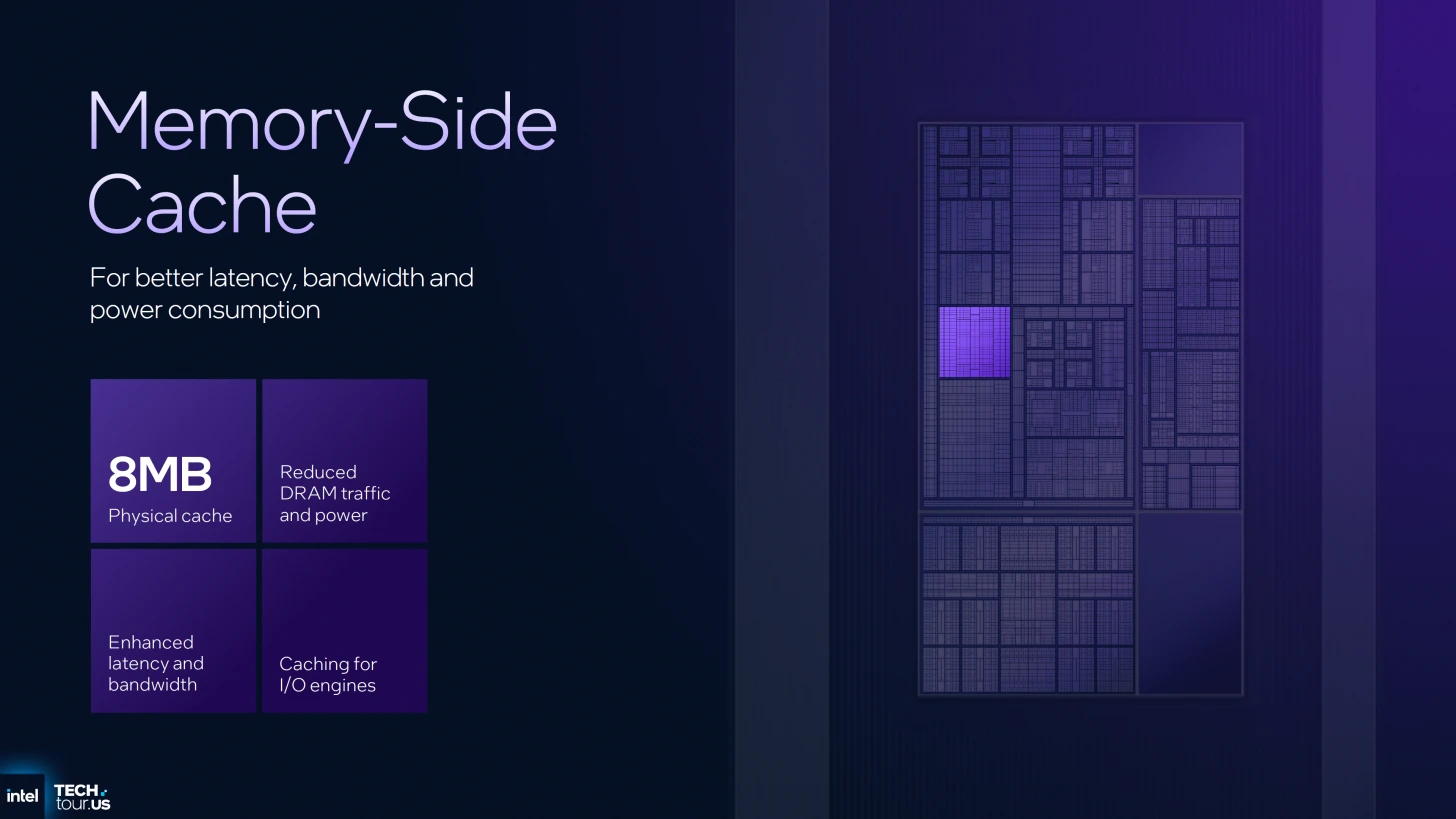
أما الابتكار الأبرز فهو الـ Memory-Side Cache:
السعة: ذاكرة مشتركة بحجم 8MB تقع ضمن وحدة Home Agent.
الوظيفة: تعمل كجسر تواصل فائق السرعة بين كافة وحدات الشريحة (CPU, GPU, IPU, NPU).
مثال عملي: تستفيد وحدة معالجة الصور (IPU) من هذه الذاكرة عند معالجة بث الكاميرا (Webcam Streams)، مما يلغي الحاجة للذهاب إلى الـ RAM البعيدة، وبالتالي يوفر الطاقة بشكل كبير ويقلل زمن التأخير (Latency).
الخـــلاصة
تُعد معمارية Panther Lake خطوة نوعية في مسار تطور معالجات إنتل، إذ تعكس انتقال الشركة من مجرد تحسينات تدريجية في الأداء إلى إعادة صياغة شاملة للبنية الداخلية بما يتناسب مع متطلبات الحوسبة الحديثة. فالتركيز على فصل وحدات الحوسبة إلى بلاطات مستقلة (Compute Tiles) وربطها بأنظمة ذاكرة أكثر ذكاءً مثل الـ Memory-Side Cache، يعزز من كفاءة التواصل الداخلي ويحدّ من زمن الوصول إلى البيانات، مما يمنح النظام استجابة أسرع وقدرة أعلى على التعامل مع أعباء العمل المتوازية والمعقدة.
كما أنّ تحسين توزيع المهام بين أنوية الأداء والكفاءة عبر خوارزميات توجيه ذكية (Thread Director) يُبرز نضج فلسفة التصميم الهجينة لدى إنتل، ويجعل المعالج أكثر مرونة في التنقل بين أنماط الاستخدام المختلفة؛ من الألعاب إلى الإنتاجية إلى تطبيقات الذكاء الاصطناعي، وأيضاً هو إثبات على مدى قدرة الهيكل التنظيمي للمعالج على إدارة الموارد واستهلاك الطاقة بأقصى كفاءة ممكنة دون المساس بالأداء الخام.
بالنظر إلى التطويرات الجوهرية في تصميم الكاش، وتنظيم البلاطات، وتحسين مسارات البيانات، يبدو أنّ الشركة تراهن هذه المرة على الكفاءة المعمارية أكثر من الأرقام النظرية للتردد.
ويُضاف إلى ذلك أنّ التحسينات العميقة في تصميم الأنوية وإدارة استهلاك الطاقة جعلت هذه المعمارية موفرة للطاقة بدرجة لافتة مقارنة بما اعتدناه من معالجات x86، وهو تحسن كبير في سوق الحواسيب المحمولة، إذ يتيح أداءً قويًا مع استهلاك طاقة منخفض، مما يرفع من كفاءة التشغيل ويطيل عمر البطارية دون التضحية بالأداء.
في النهاية، يمكن القول إنّ Panther Lake ليست مجرد جيلٍ جديد من المعالجات، بل مرحلة انتقالية نحو مفهوم أكثر توازناً بين الأداء، والكفاءة، والذكاء الداخلي في إدارة الموارد، وهي تمهّد الطريق لمعمارية أكثر تطورًا في الأجيال القادمة التي ستُبني على هذه الأسس الصلبة.
تمثل شركة Intel الركيزة السيادية التي لا يمكن للصناعة الأمريكية السماح بسقوطها؛ فهي ليست مجرد شركة تقنية، بل هي ملاذ الأمن القومي في مواجهة التقلبات الجيوسياسية.
إن ارتكاز سلسلة التوريد العالمية بالكامل على مورد واحد مثل TSMC يمثل نقطة ضعف هيكلية تهدد بانهيار الصناعة في حال حدوث أي اضطراب في مضيق تايوان. هذا الواقع دفع العمالقة لإعادة حساباتهم؛ فنحن نرى اليوم تحولاً استراتيجياً ملموساً من خلال اعتماد آبل لعقدة التصنيع 18A في معالجات M5 القادمة، تزامناً مع توجه Google و Meta لتقييم حلول التغليف المتقدمة من Intel لرقائق الذكاء الاصطناعي وشرائح ASIC الخاصة بكل شركة.
يُمكننا القول إذًا أن Intel اليوم تتحول من مجرد منافس إلى البديل الاستراتيجي الحتمي لضمان استمرارية الحوسبة العالمية.





