الحاسوب الخارق DGX-1 ببطاقات Tesla V100 يحطم نتائج بينشمارك GeekBench!

حاسوب انفيديا الخارق DGX-1 يعتبر من أقوى ما انتجته انفيديا في عالم الحواسب الخارق على صعيد قدرته الحوسبية المدمرة. الحاسوب الخارق DGX-1 المشغل بواسطة بطاقات Tesla V100 من معمارية Volta قادر ببسطاة على تقديم تحسين في سرعة العمليات الحسابية بثلاث مرات لأعباء عمل الذكاء الاصطناعي المتطلبة للغاية في عالمنا اليوم.
لن نبالغ بقولنا أنها من أحد أفضل الحواسب الخارقة التي أطلقتها انفيديا في مجال الذكاء الاصطناعي, فالإصدار السابق لحاسوب DGX-1 أتى مع 8 بطاقات Tesla P100 من معمارية باسكال وقدم كمواصفات الشيء الكثير فهو كان قادر على تقليص حوسبة 1.33 مليار صورة في اليوم خلال ساعتين بينما الإصدار الأقدم كان يحتاج إلى 22 ساعة, وخلال مقارنته مع الإصدار الجديد لحاسوب DGX-1 فهو قادر على تشغيل مجموعة واسعة من تدشينات الذكاء الاصطناعي الحديثة في المجالات المهنية الرائدة، مزودي الخدمات السحابية ومنظمات الأبحاث في جميع أنحاء العالم, يكفي أن أقول لكم أن الحاسوب الخارق قادر على استبدال 400 سيرفر بفضل قوته!

ما كانت تحتاجه بطاقة TITAN X للقيام به خلال 8 أيام هذا الحاسوب الخارق قادر على تنفيذه خلال ساعتين فقط طبعاً يقصد هنا بقوة حوسبة الذكاء الاصطناعي والتعلم العميق! هذا الحاسوب الخارق يضم 8 بطاقات Tesla V100 التي تعمل بواجهة NVLink, وبداخل كل تلك البطاقات هناك 40,960 ألف نواة كودا مع حجم ذاكرة HBM2 كلي يصل إلى 128GB لنجد أنه قادر على توفير قوة حوسبة تصل إلى 960Tensor TFLOP.
نتائج مدمرة لبينشمارك GeekBench!

استطاع هذا الحاسوب ببساطة من تدمير وتحطيم النتائج التي تم رصدها علي GeekBench بفضل قوة 8 بطاقات Tesla V100 مع معالجين إنتل Xeon E5-2698 v4, ذاكرة DDR4 بحجم 512GB ووأقراص تخزين SSD بحجم 1.92TB. هذه البطاقات تضم بداخلها نواة من معمارية Volta لتكون أول بطاقة بالعالم التي تأتي بدقة تصنيع 12nm FFN فهي تستخدم نواة GV100 التي تحمل بداخلها حوالي 5120 معالج تدفق مع 80 وحدة SM وكل وحدة تحتوي على 64 معالج تدفق كن المختلف معها انها تاتي بانوية حوسبة جديدة تحمل إسم Tensor core مختلفة بشكل واضح عن معمارية باسكال, مع تردد 1455MHz, بذاكرة HBM2 من الجيل الثاني بحجم 16GB وبمواجهة ذاكرة 4096bit مع أداء حوسبة FP32 يصل إلى 15.0TF.
هذه النواة تعتبر الأولى بالعالم التي تصل لهذا الحجم 815mm2 فلم يسبق أن وصلت نواة بهذا الحجم من قبل فخليفتها السابقة نواة GP100 كانت قد أتت بحجم 610m2. كما تأتي لنا مزودة بحوالي 21 مليار ترانزيستور لتقدم أداء مكافئ لـ100 معالج مركزي من ناحية قدرة حوسبة التعلم العميق. كما انها توفر تحسناً بخمس مرات عن معمارية باسكال، وبـ15 مرة عن معمارية ماكسويل.
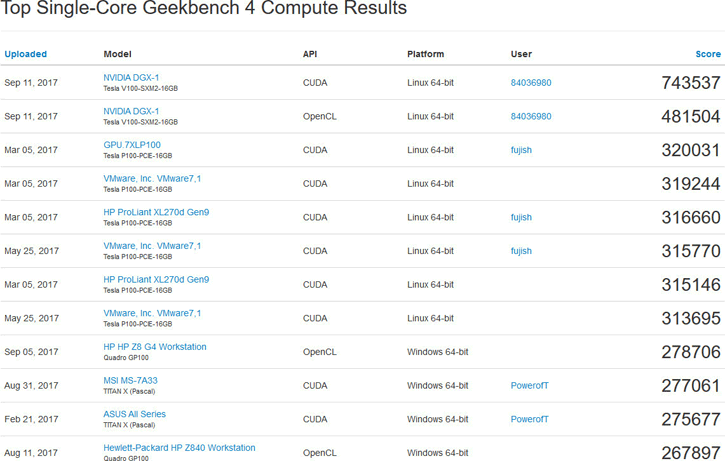
من خلال النتائج التي تم رصدها على بينشمارك Geekbench 4 نلاحظ حصول الحاسوب القديم ببطاقات P100 على نتيجة 320 ألف نقطة بينما الحاسوب الجديد ببطاقات V100 فلقد حصل على 481,504 ألف نقطة على OpenCL و 746,537 ألف نقطة على CUDA. هذه القوة المفرطة ممكن الحصول عليها لتخدم الشركات والمهتمين في مجال الحوسبة السريعة والذكاء الاصطناعي لكن بمبلغ 149 ألف دولار.
تثبت انفيديا في كل مرة انها وحش حقيقي في مجال الحوسبة التي تعتمد على المعالج الرسومي..هل تعتقدون أن المعالج المركزي فقد قدرته على منافسة المعالج الرسومي في مجال التصيير والحوسبة السريعة؟ شاركونا برأيكم